学界 | 哈佛大学提出变分注意力:用VAE重建注意力机制
机器之心发布
机器之心编辑部
注意力 (attention) 模型在神经网络中被广泛应用,不过注意力机制一般是决定性的而非随机变量。来自哈佛大学的研究人员提出了将注意力建模成隐变量,应用变分自编码器(Variational Auto-Encoder,VAE)和梯度策略来训练模型,在不使用 kl annealing 等训练技巧的情况下进行训练,目前在 IWSLT German-English 上取得了非常不错的成果。

论文链接:https://arxiv.org/abs/1807.03756v1
相关代码:https://github.com/harvardnlp/var-attn
一、背景
近年来很多论文将 VAE 应用到文本生成上,通过引入隐变量对不确定性进行建模。不过这会导致一个常见的 KL collapsing 问题,导致的现象就是直接训练的 VAE 得到的 KL 接近于 0,也就意味着近似后验和先验一样,隐变量被模型所忽略。
为了解决这个问题,在哈佛研究人员的工作中,注意力被建模成隐变量,由于解码器 (decoder) 和译码器 (encoder) 之间的主要信息传输通道是通过注意力来传输的,如果忽略了这个隐变量,就会因无法得到源文本的信息而得到很大的惩罚 (penalty)(这相比之前的许多工作中直接把隐变量加入到每个解码步骤不同,因为那样即使解码器忽略了隐变量,也可以达到很好的模型表现)。因此通过直接优化目标函数才能使得这个隐变量也不易被忽略,研究人员的实验完全验证了这一点。
值得注意的是,研究人员将注意力建模成隐变量并不是单纯为了应用 VAE 这个工具,而是因为研究人员认为将注意力建模成隐变量可以为解码器提供更干净 (clean) 的特征,从而在不增加模型参数的情况下提高模型的表现能力。
二、实验效果
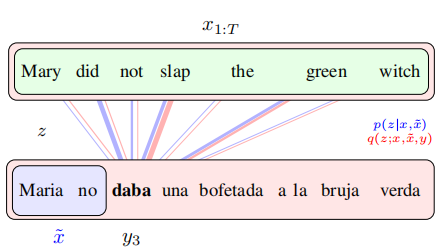
与传统的注意力机制进行对比,传统的注意力机制仅能通过之前生成的单词确定当前即将生成单词的注意力(上图蓝色部分,仅能观测到已经预测的单词,由于存在多种翻译方式,因此会注意到和实际翻译的单词并不对应的位置),研究人员通过全部的源文本和目标文本去得到更准确的后验注意力(上图红色部分,通过全部信息得到后验,因此注意力和实际翻译应该与注意 (attend) 的源单词对应),并把更好的后验注意力提供给解码器,从而使解码器拿到更为干净的特征,藉此希望得到更好的模型。
三、核心思想
方法:假定 x 是源文本,y 是目标文本,z 是注意力,根据标准的 VAE 方法,研究人员引入推理网络 (inference network) q(z | x, y) 去近似后验,那么 ELBO 可以表达为(为了方便,只考虑目标文本只有一个单词的情况):
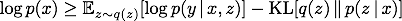
上面不等式的右侧是 ELBO,其中第一项是从 q(z | x, y) 中采样出注意力,使用采样出的注意力作为解码器的输入计算交叉熵损失,第二项是确保后验分布接近于先验分布(注意到此处的先验和一般的 VAE 不同,这里的先验是和模型一起学习的)。此时的 p(z | x) 和 q(z | x, y) 都是分类分布的,因此我们使用梯度策略去优化上面的目标函数。
由于此时的后验 q 能看到全部的 x 和 y,因此后验中采样的注意力可以比先验 p(z | x) 好,比如以下的例子:
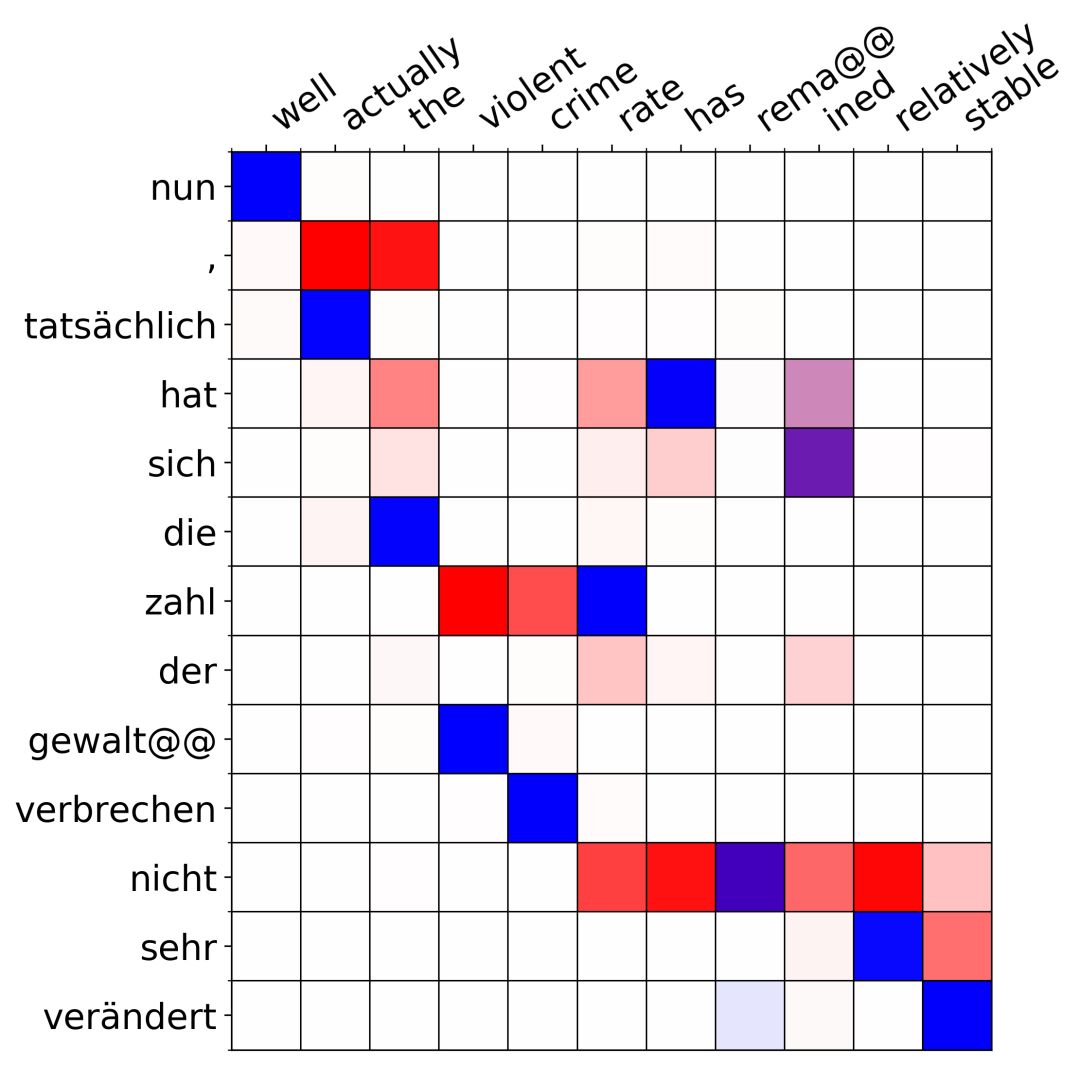
这里需要把德语(纵向)翻译成英语(横向),红色代表先验(即只观测到 x 而不观测到 y 的 p(z | x)),蓝色代表后验(即观测到全部信息的 q(z | x, y))。注意到在第二个单词「actually」处,红色的先验试图注意到「nun」后面的逗号「,」,从而试图生成一个「well,」的翻译结果,然而实际的英语翻译中并没有逗号,而是直接是」well actually」,由于后验 q(z | x, y) 可以看到实际的翻译,因此蓝色的后验正确地注意到了「tatsachlich」上。注意到训练目标 ELBO 中我们从后验 q 中采样注意力给解码器,因此通过使用 VAE 的方法,解码器得到了更准确的注意力信号,从而提高了模型的表达能力。
四、展望
注意力方法是自然语言处理等领域普遍存在的工具,但它们很难用作隐变量模型。这项工作通过具有良好实验结果的变分注意力机制来探索潜在对齐的替代方法。研究人员同时也表示未来的工作将实验规模较大的任务和更复杂的模型,如多跳注意力模型 (multi-hop attention models),变压器模型 (transformer models) 和结构化模型 (structured models),以及利用这些潜在变量的可解释性作为一种方式去将先验知识进行结合。

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


