嵌入式图像预览技术:允许人们在延迟加载过程中加载预览图像

低质量图像预览(LQIP) 和 基于 SVG 的变体 SQIP 是当前延迟加载图像的两种主导性技术。这两种技术的共同之处在于,都会在加载过程中首先生成一个低质量的预览图像。这个预览图像会显示得比较模糊,在图像加载完成后,原图像会替换掉预览图像。试想一下,如果你想要在不加载额外数据的情况下向网站访问者显示预览图像,那该怎么做呢?
JPEG 文件通常采用延迟加载技术,根据技术规范,图像其中包含的数据有可能以这样一种方式进行存储:可以让图像先显示其粗略的内容,之后再显示详细的图像内容。于是在这样的加载过程中,图像不再是从上到下逐渐加载显示出来,这也被称作基线模式,而是可以首先非常快速地显示一幅模糊的图像,之后图像会逐渐变得越来越清晰,即渐进模式。
低质量图像预览(LQIP): https://www.guypo.com/introducing-lqip-low-quality-image-placeholders
基于 SVG 的变体 SQIP: https://github.com/axe312ger/sqip


除了更快地显示整图全貌从而带来更好的用户体验之外,渐进式 jpeg 的文件通常也比基线编码 jpeg 的文件更小。根据 Yahoo 开发团队的 Stoyan Stefanov 的说法,对于 10 Kb 以上的文件,在使用渐进模式编码时,有 94% 的可能性会生成更小的图像文件。
如果你的网站中包含许多 jpeg 文件,你就会注意到,即使是采用渐进模式,在加载网页时可能也会一个接一个地进行 jpeg 文件加载。这是因为现代浏览器同时只允许 6 个连接通往同一个域。因此,单凭渐进式 jpeg 并不能带给用户最快的页面体验。在最差的情况下,浏览器将在加载一个图像彻底完毕之后才去加载下一个图像。
本文想要提出的想法是,如果当前只从服务器加载某一指定字节数量的渐进式 JPEG,这样就可以快速显示出图像内容的梗概。稍后,在一个定义的时刻之后(例如,当当前视图中的所有预览图像都已加载完成),再去加载图像的剩余部分,而且不需要再次请求已在预览请求下加载完毕的部分。

遗憾的是,你无法指示属性中的 img 标签在什么时刻应该加载多少图像。但是,对于 Ajax 格式的图像,这是可能做到的,前提是传送图像的服务器支持 HTTP 范围请求: https://developer.mozilla.org/en-US/docs/Web/HTTP/Range_requests
如果使用了 HTTP 范围请求,客户端可以在 HTTP 请求头中通知服务器,会指明文件的哪些字节将包含在 HTTP 响应中。一般各类大型服务器(Apache、IIS、nginx 等)都支持这个特性,主要用于视频回放。假如用户一下跳转到视频的末尾,在用户最终看到所需的部分之前就加载完整的视频,这并不是很有效的做法。因此,只会向服务器请求用户所指定时刻前后的视频数据,这样用户才能尽可能快地从指定时刻继续观看视频。
-
创建渐进式 JPEG。 -
在第一个 HTTP 范围请求中指定加载预览图像必须的字节偏移量。 创建前端 JavaScript 代码。
渐进式 JPEG 一般由几个被称为扫描段的部分组成,每个扫描段包含最终图像的一部分内容。而第一次扫描只会非常粗略地显示图像,在文件中随后进行的扫描会向已经加载的数据继续添加越来越详细的信息,并最终形成了图像最后的全貌。
每一次扫描所显示的外观由生成 jpeg 的具体程序决定。在 mozjpeg 项目中诸如 cjpeg 这样的命令行程序中,你甚至可以定义这些扫描具体包含哪些数据。但是,这当然需要更深的专业知识,而本文的范围并不包含这些。如果想了解更多相关知识,可以参考我的文章“JPG 终极理解”,该篇文章描述了 JPEG 压缩相关的基础知识。在 mozjpeg 项目的 wizard.txt 中详细地解释了扫描脚本中必须传递给程序的各个参数。在我看来,在快速渐进结构和文件大小之间,mozjpeg 使用的扫描脚本(会进行 7 次扫描)默认参数往往已经能达到很好的平衡,因此,推荐采用该默认参数。
要将一个初始 JPEG 文件转换为渐进 JPEG 文件,我们可以使用来自 mozjpeg 项目的 jpegtran 命令。这是一个可以对现有 JPEG 进行无损更改的工具。该工具 Windows 和 Linux 的预编译版本 可以在网上找到。如果出于安全方面的考虑,你更愿意谨慎行事,那么最好自己构建这样的工具。
$ jpegtran input.jpg > progressive.jpg我们的目的是构建一个渐进式 JPEG,而这个过程完全是由 jpegtran 这条命令所负责的,并不需要我们进行任何显式的说明。而且,在这个过程中,原图像数据并不会以任何形式发生更改。改变的仅仅是文件中图像数据的排列顺序。
$ exiftool -all= progress .jpg如果不希望使用命令行工具,还可以使用在线压缩服务 compress-or-die.com 生成不带元数据的渐进式 JPEG 文件。
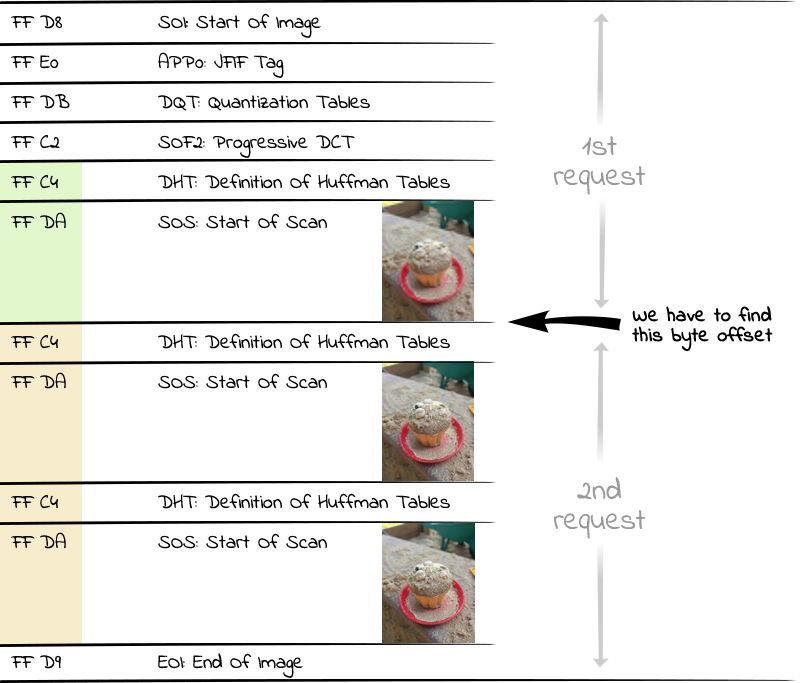
现在 JPEG 文件已经被分成不同的扫描段,每个段包含不同的组件(包括图像数据,如 IPTC、Exif 和 XMP 的元数据,嵌入的颜色配置文件,量化表等等)。每个扫描段都以一个十六进制 FF 字节的标记作为开始。然后紧跟一个字节来指示段的类型。例如,D8 是 SOI 标记,即图像的开始,于是,每个 JPEG 文件都以 FF D8 这两个字节作为开头。
而每次扫描的开始都有 SOS 标记,即扫描的开始,用十六进制 FF DA 作为开头。由于 SOS 标记后面的数据采用熵编码(例如,jpeg 使用的是 Huffman 编码),所以为了实现解码功能,在 SOS 段之前还需要一个带有 Huffman 表的段(DHT),并用 FF C4 作为 DHT 段的开头。因此,在渐进式 JPEG 文件中,我们感兴趣的区域总是由 Huffman 表和扫描数据段交替构成。于是,如果想要显示出图像第一张非常粗略的扫描图,我们必须从服务器请求第二个 DHT 段(由十六进制 FF C4 作为开头)前面出现的所有字节。
<?php
$img = "progressive.jpg";
$jpgdata = file_get_contents($img);
$positions = [];
$offset = 0;
while ($pos = strpos($jpgdata, "\xFF\xC4", $offset)) {
$positions[] = $pos+2;
$offset = $pos+2;
}我们必须将找到的位置加上 2,因为浏览器只有在遇到下一个新标记时才会渲染预览图像的最后一行,而如前所述,该起始标记由两个字节组成。
由于我们对本例中的第一个预览图像感兴趣,所以 $positions[1] 这个变量为第一次扫描找到了正确的结束位置,在此扫描执行之前,我们必须通过 HTTP 范围请求来对该图像文件发起请求。如果要请求分辨率更高的图像作为首次预览图像,我们可以使用数组中较后面的变量,例如 $positions[3]。
<img src="progressive.jpg" data-bytes="<?= $positions[1] ?>">与许多延迟加载库的通常情况一样,这里没有直接定义 src 属性,因此浏览器在解析 HTML 代码时不会立即从服务器请求图像。
使用以下 JavaScript 代码加载预览图像:
var $img = document.querySelector("img[src]");
var URL = window.URL || window.webkitURL;
var xhr = new XMLHttpRequest();
xhr.onload = function(){
if (this.status === 206){
$img.src_part = this.response;
$img.src = URL.createObjectURL(this.response);
}
}
xhr.open('GET', $img.getAttribute('src'));
xhr.setRequestHeader("Range", "bytes=0-" + $img.getAttribute('data-bytes'));
xhr.responseType = 'blob';
xhr.send();这段代码创建了一个 Ajax 请求,这个请求通过 HTTP 范围请求头告诉服务器将文件从开始返回到 data-bytes 中指定的位置为止,不需要更多数据。如果该服务器能理解 HTTP 范围请求,它将以 HTTP-206 响应返回文件部分内容,并以 BLOB 格式返回二进制的图像数据,从中我们可以使用 createObjectURL 生成一个浏览器内部 URL。我们可以使用这个 URL 作为 img 标签的 src。这样,我们就完成了预览图像的加载。
同时,我们还将 BLOB 存储在 DOM 对象中的 src_part 属性中,因为之后将立即需要使用这些数据。
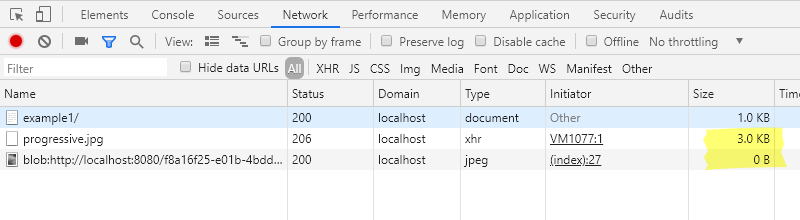
在开发人员控制台的网络选项卡中,你可以检查到,网页并未加载完整的图像,只是加载了图像的一小部分。此外,加载中的 blob URL 会以 0 字节的大小显示在控制台中。
因为我们已经加载了原始 JPEG 文件的头部,所以预览图像的大小是正确的。因此,根据应用程序,我们有时可以省略 img 标签的高度和宽度。
出于性能原因,也可以在 HTML 源代码中直接将预览图像的数据作为数据 URI 传输。这节省了传输 HTTP 头信息的开销,但是 base64 编码会使图像数据大小增长三分之一。如果你使用 gzip 或 brotli 之类的工具进行内容编码并传递给 HTML 代码,那么这相对而言可另当别论,但你仍然应该只为较小的预览图像使用数据 URI。
更重要的是,这样预览图像是即时可用的,用户在打开网页时不会体验到明显的延迟。
<?php
…
$fp = fopen($img, 'r');
$data_uri = 'data:image/jpeg;base64,'. base64_encode(fread($fp, $positions[1]));
fclose($fp);<img src="<?= $data_uri ?>" src="progressive.jpg" alt=""><script>
var $img = document.querySelector("img[src]");
var binary = atob($img.src.slice(23));
var n = binary.length;
var view = new Uint8Array(n);
while(n--) { view[n] = binary.charCodeAt(n); }
$img.src_part = new Blob([view], { type: 'image/jpeg' });
$img.setAttribute('data-bytes', $img.src_part.size - 1);
</script>在本例中,不是通过 Ajax 请求来请求数据(在 Ajax 请求中,我们将立即收到一个 BLOB),而是必须从数据 URI 创建 BLOB。为此,我们从不包含图像数据的部分释放数据 URI,即 data:image/jpeg;base64。并且使用 atob 命令对剩余的 base64 编码数据进行解码。为了从现在的二进制字符串数据创建一个 BLOB,我们必须将数据传输到 Uint8 数组中,这可以确保数据不被视为 UTF-8 编码的文本。从这个数组中,我们现在可以用预览图像的图像数据创建一个二进制 BLOB。
因此,我们不必为这个内嵌版本调整之后的代码,而是将属性 data-bytes 添加到 img 标签上,而在前面的示例中,img 标签包含了一个字节偏移量,它指示了必须从哪里开始第二部分的图像加载。
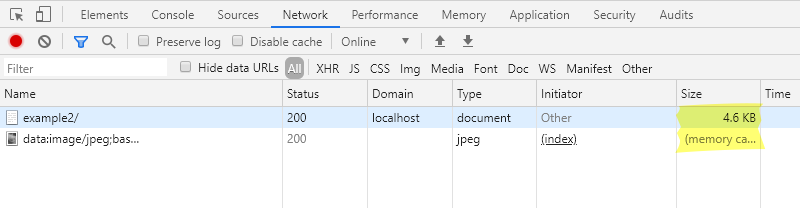
在开发人员控制台的网络选项卡中,还可以检查得知,当 HTML 页面的文件大小增加时,加载预览图像也不会生成额外的请求。
setTimeout(function(){
var xhr = new XMLHttpRequest();
xhr.onload = function(){
if (this.status === 206){
var blob = new Blob([$img.src_part, this.response], { type: 'image/jpeg'} );
$img.src = URL.createObjectURL(blob);
}
}
xhr.open('GET', $img.getAttribute('src'));
xhr.setRequestHeader("Range", "bytes="+ (parseInt($img.getAttribute('data-bytes'), 10)+1) +'-');
xhr.responseType = 'blob';
xhr.send();
}, 2000);在这次的 HTML 范围请求头中,我们指定要从预览图像的结束位置请求图像到文件的结束位置。而第一个请求的响应存储在 DOM 对象的属性 src_part 中。我们使用这两个请求的响应用 new blob() 创建一个新的 BLOB,其中包含整个图像的数据。由此生成的 BLOB URL 会再次用作 DOM 对象的 src 属性。现在,实现了图像的完全加载。
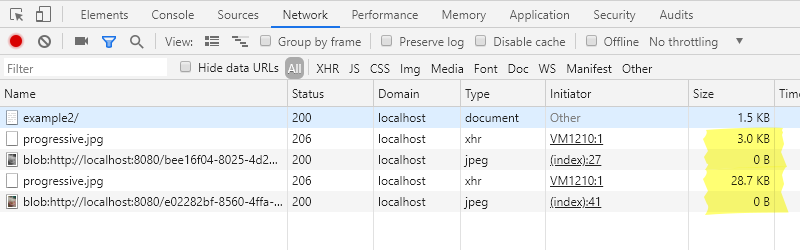
现在我们还可以在开发人员控制台的网络选项卡中再次检查每次加载的大小。
在下面的 URL 中,我提供了一个可以使用不同参数进行试验的原型: http://embedimage-preview.cerdmann.com/prototype/
原型的 GitHub 存储库: https://github.com/mcsodbrenner/embedimage
使用本文介绍的嵌入式图像预览(EIP)技术,我们可以在 Ajax 和 HTTP 范围请求的帮助下为渐进 jpeg 加载不同质量的预览图像。这些预览图像中的数据不会在之后被丢弃,而是完全被重用来显示整个图像。
此外,并不需要为之另外创建一个预览图像文件。在服务器端,只需要确定并保存预览图像结束时的字节偏移量。在 CMS 系统中,应该可以将这个数字保存为图像的属性,并在 img 标签输出时将其考虑在内。甚至可以将此抽象为一个工作流,它用偏移量来补充图片的文件名,例如 progressive-8343.jpg,这样就可以不在图片文件中保存这个偏移量。这个偏移量可以由 JavaScript 代码提取。
由于预览图像数据是可以重复使用的,因此,这种技术可以更好地替代目前的通常加载方法,即先加载一个预览图像文件,然后加载 WebP(并为不支持 web 的浏览器提供 JPEG 回退)。而预览图像常常会破坏 WebP 的存储优势,因为 WebP 不支持渐进模式。
目前,普通 LQIP 中的预览图像质量普遍较差,因为假设加载预览数据需要占用额外的带宽。正如 Robin Osborne 在 2018 年的一篇博客文章(https://www.robinosborne.co.uk/2018/01/05/image-placeholders-do-it-right-or-dont-do-it-at-all-please/)中所明确指出的那样,如果预览图像作为占位符并没有给出最终图像的概貌,那么它的存在实际上就没有多大意义。通过使用本文建议的技术,通过向用户提供渐进式 JPEG 的后续扫描,我们可以毫不犹豫地将更多的最终图像直接展示为预览图像。
如果用户的网络连接很不稳定,根据不同的应用程序的特性,不加载整个 JPEG 文件有时也有其意义,例如,不加载全图,而是省略最后两次扫描。这将生成一个小得多的 JPEG 文件,而其图像质量仅仅是略有下降。用户会为此感谢我们,而我们也不必再在服务器上存储额外的文件。
希望你在试用这个程序原型时能尽享其中的乐趣,我非常期待你的评论。
英文原文: https://www.smashingmagazine.com/2019/08/faster-image-loading-embedded-previews/






