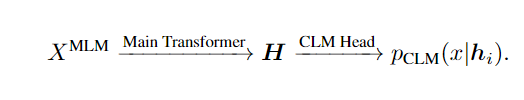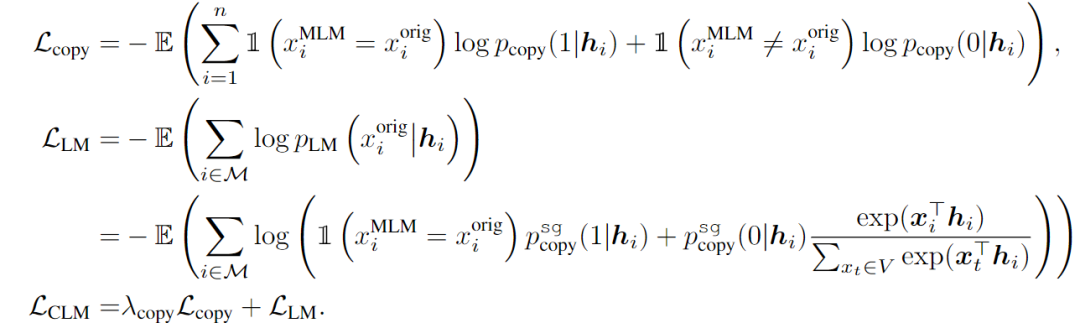编辑:技术组
【新智元导读】近日,微软最新的第5代图灵模型(T-NLRv5)同时问鼎SuperGLUE和GLUE两个排行榜,并且在GLUE基准的MNLI和RTE上首次实现了和人类相当的水平!
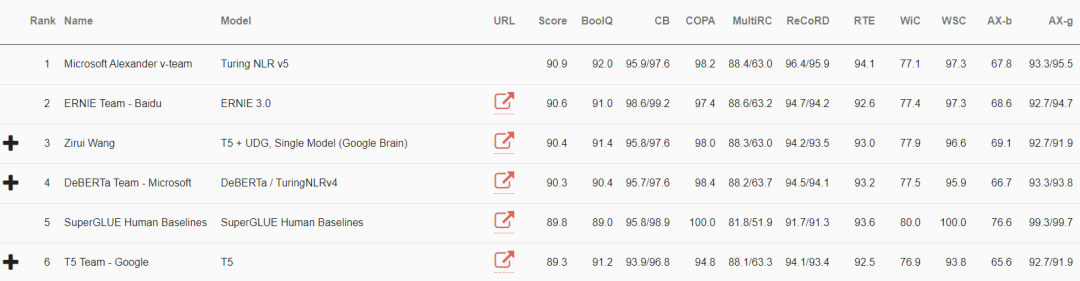
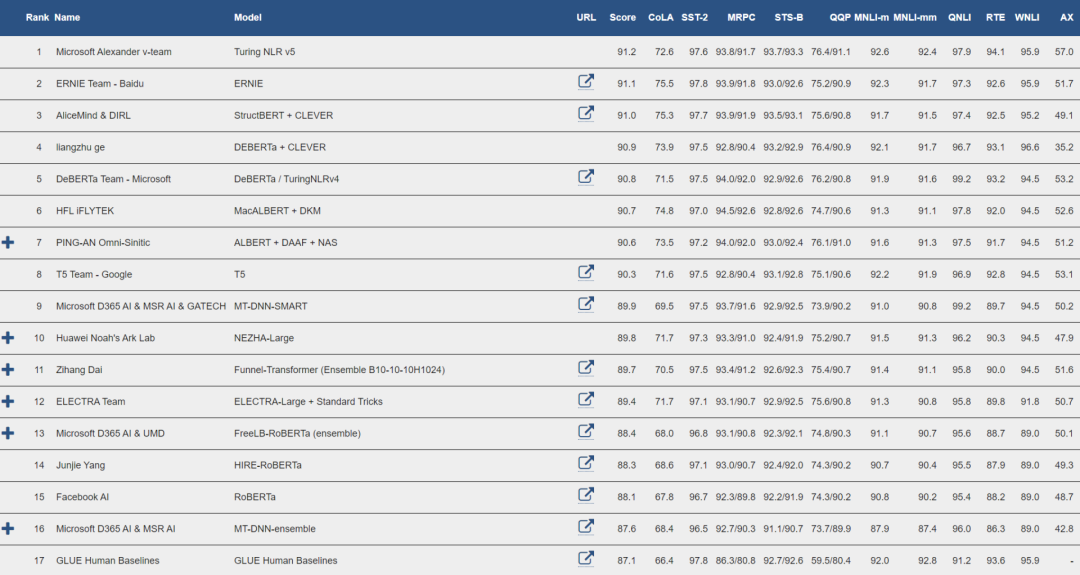
SuperGLUE以及GLUE榜单的第一名又易主了!
近日,最新的微软图灵模型(T-NLRv5)在SuperGLUE和GLUE排行榜上又重新夺回第一。
值得注意的是,T-NLRv5在GLUE基准的MNLI和RTE两项任务上首次实现了和人类相当的水平,而这两项任务也是之前的NLP模型在GLUE上一直没有达到人类水平的任务。
此外,T-NLRv5在减少50%的参数和预训练计算成本的情况下达到了和其他模型相当的效果。
图灵-自然语言表示模型(T-NLRv5)整合了微软研究院、Azure AI和微软图灵的最佳建模技术。其中,这些模型使用了基于FastPT和DeepSpeed的高效训练框架来进行大规模的预训练。
T-NLRv5的作者之一是微软研究院副总裁高剑峰,他同时也是微软研究院的杰出科学家,IEEE Fellow,ACM Distinguished Member。
高剑峰主要领导深度学习小组,剑指自然语言和计算机视觉领域的SOTA模型,比如NLP领域的MT-DNN,UniLM,DeBERTa和CV领域的OSCAR,VIVO,VinVL模型都是出自他的研究团队。
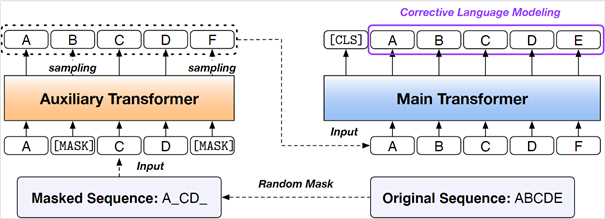
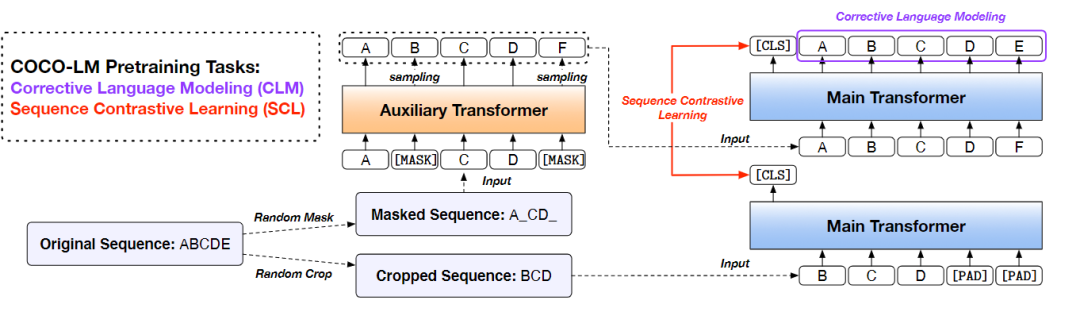
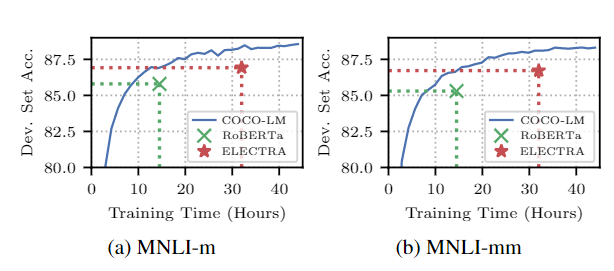
基于「COCO-LM」,T-NLRv5融合了ELECTRA模型和语言纠正模型预训练的优点。
NLRv5通过「辅助模型」来破坏输入的文本序列并产生对抗性信息,而主模型则使用纠正性语言模型任务进行预训练,即检测和纠正被辅助模型替换的标记。
https://arxiv.org/pdf/2102.08473.pdf
T-NLRv5还使用了为开发早期T-NLR版本而优化的训练数据集和数据处理管道DeBERTa和UniLM,以及其他预训练研究工作的优化,如TUPE。
T-NLRv5的另一个关键特点是可以在较小的规模下保持模型的有效性,不管是几亿参数,还是有几十亿参数。
此外,通过禁用辅助模型中的dropout,使辅助模型的预训练和主模型训练数据的生成能够在一个过程中完成。
同时,禁用COCO-LM中的顺序对比学习任务可以减少计算成本,从而实现训练更深的Transformer网络。
COCO-LM首次于2月16日上传至arxiv,10月27日论文又更新了内容。文中提出了一种新的预训练模型的框架,涉及到之前提到的辅助模型。
1. COrrecting Language Modeling (CLM):
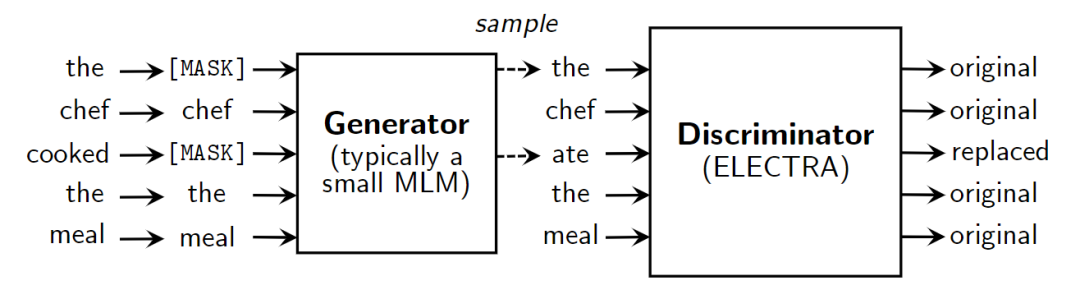
模型的灵感来自于ELECTRA预训练模型的对抗思想, 引入一个生成器G和一个判别器D,其中生成器就是经过MLM方法训练后的Transformer,判别器D用来判断输入中的每个token是否由生成器生成。
ELECTRA使用的预训练方法也称为RTD(replaced token detection),在实验中性能总是要比MLM更好。RTD首先使用一个生成器预测句中被mask掉的token,接下来使用预测的token替代句中的[MASK]标记,然后使用一个判别器区分句中的每个token是原始的还是替换后的。
和ELECTRA不同的是,COCO-LM模型在CLM Head中引入了一个语言模型层,还有一个二元分类的可训练copy机制,在训练时采用多任务的方式同时训练这两个任务,训练后模型能够同时利用MLM和ELECTRA的优势。
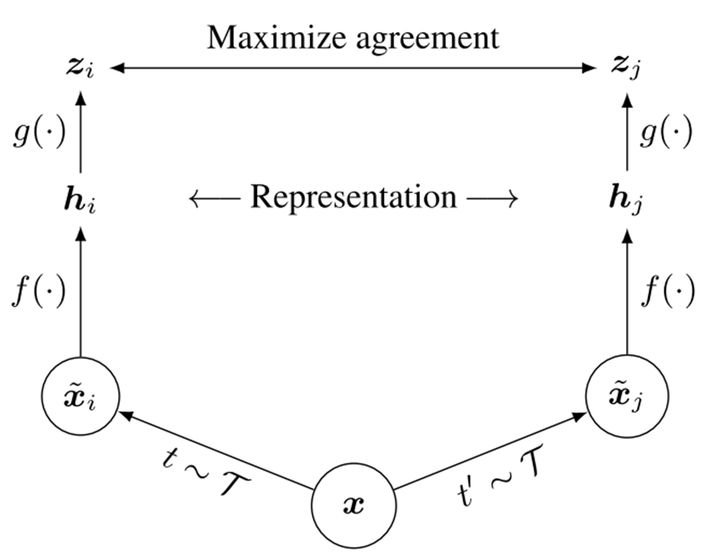
2. Sequence COntrasting Learning(SCL):
模型还引入了对比学习的思想,对比学习的主要方法是对齐同一数据的不同视角(view)
,并且让不相关的样本尽可能远离。在CV领域,同一数据的不同视角主要由数据增强(如旋转、裁切、模糊等)来做,所以模型能够识别变换后的图像,从而增加了模型鲁棒性。
在自然语言中,不同位置的[MASK]实际上也相当于是同一数据的不同视角,例如对应图片的裁切操作,文本可以裁切掉10%来保留句子的主要语义,裁切后的文本作为对比学习过程中的正例,其他随机文本作为负例。
虽说COCO-LM模型的灵感一部分来自于ELECTRA,但COCO-LM预训练所用的GPU小时数要比ELECTRA少了近50%,并且性能没有任何损失。
COCO-LM的第一作者孟瑜,目前在伊利诺伊大学厄巴纳-香槟分校(UIUC)的攻读博士。
主要研究方向为利用自监督、无监督和弱监督的文本挖掘技术来组织和挖掘文本数据。
他分别在2017年和2019年获得UIUC的学士和硕士学位,GPA全部为4.0满分。
2013-2015年期间就读于北京邮电大学应用物理专业信息与通信基础科学类理科实验班。
训练10亿个参数的神经模型在时间和计算成本上都是非常昂贵的。这产生了一个漫长的实验周期,并减慢了科学发展的速度。
在训练T-NLRv5时,团队利用以下两种方法可以提高其扩展效率,来确保模型参数和预训练计算的最佳使用:
1. 为混合精度定制的CUDA内核
通过使用为快速预训练(FastPT)而开发的定制的CUDA内核,可以优化混合精度(FP16)预训练的速度。
这不仅使模型的训练和推理效率显著提高了20%,而且在混合精度训练中提供了更好的数值稳定性。而后者正是对具有数十亿参数的语言表示模型进行预训练时最重要的需求之一。
2. ZeRO优化器
当把T-NLRv5扩展到数十亿个参数时,团队引入了DeepSpeed的ZeRO优化器技术,在多机并行预训练过程中减少了预训练模型的GPU内存占用。
具体来说,T-NLRv5 XXL(54亿)版本使用了ZeRO优化器阶段1(优化器阶段划分),这使GPU内存占用减少了5倍。
通过上述改进,T-NLRv5在不同的模型规模和预训练计算成本下都达到SOTA。
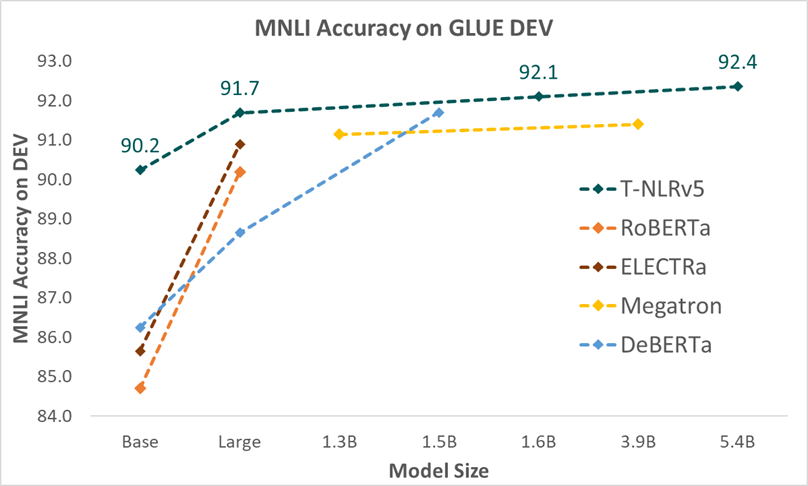
在MNLI(GLUE上最稳定的任务之一)测试中,参数或计算步骤大大减少的T-NLRv5变体,依然优于之前预训练成本更大的模型:
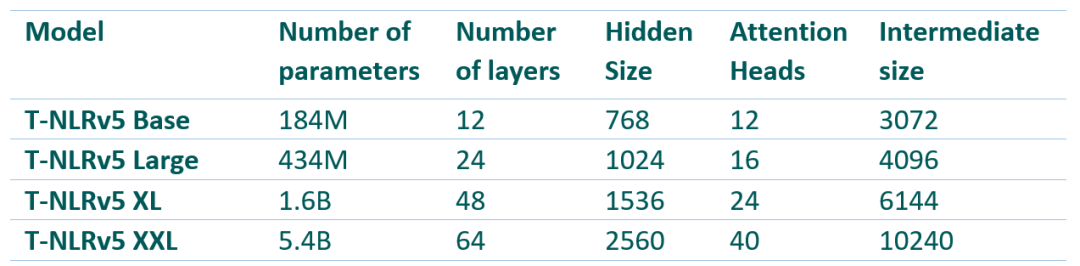
T-NLRv5 Base在使用50%的参数时,性能就超过了RoBERTa Large。
4.34亿参数的T-NLRv5 Large,表现与DeBERTa XL(15亿参数)相当,并超过了拥有39亿参数的Megatron。
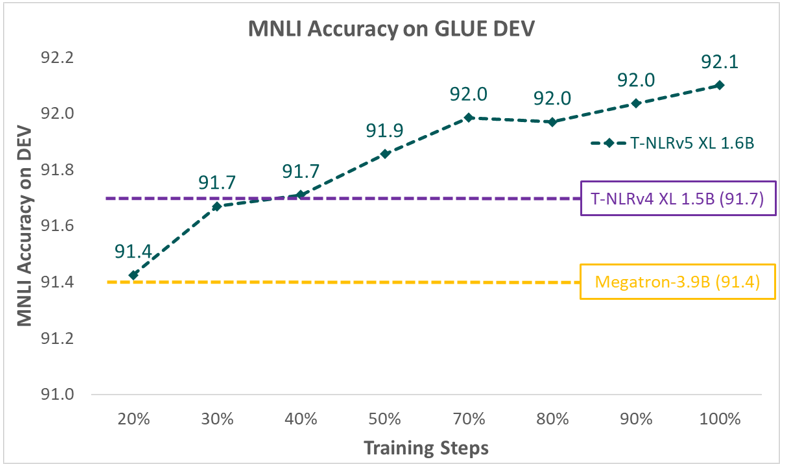
此外,T-NLRv5还显著提高了预训练的效率:在相同的训练语料和计算环境下,只需40%的预训练步骤就可以达到XL模型T-NLRv4-1.5B的精度。
其中,Base和Large的参数递增来自于128K词汇的使用。
由于测试样本与训练数据的区别巨大,因此稳健性对于一个模型在测试中的表现来说非常重要。在这项工作中,团队使用了两种方法来提高T-NLRv5适应下游任务的稳健性:
通过PDR(后置差分正则化)来增强模型的鲁棒性,该方法在模型训练期间对干净输入和嘈杂输入之间的模型后置差分进行正则化。
使用多任务学习,如在多个NLU任务中学习表征来提高模型稳健性的多任务深度神经网络(MT-DNN)。其不仅利用了大量的跨任务数据,而且得益于正则化效应,还可以产生更多的通用表征,从而适应新的任务和领域。
由此,T-NLRv5 XXL模型在MNLI上的测试准确率首次达到了人类的同等水平(92.5对92.4),这是GLUE上信息量最大的任务,同时只使用了一个模型和单一任务微调。
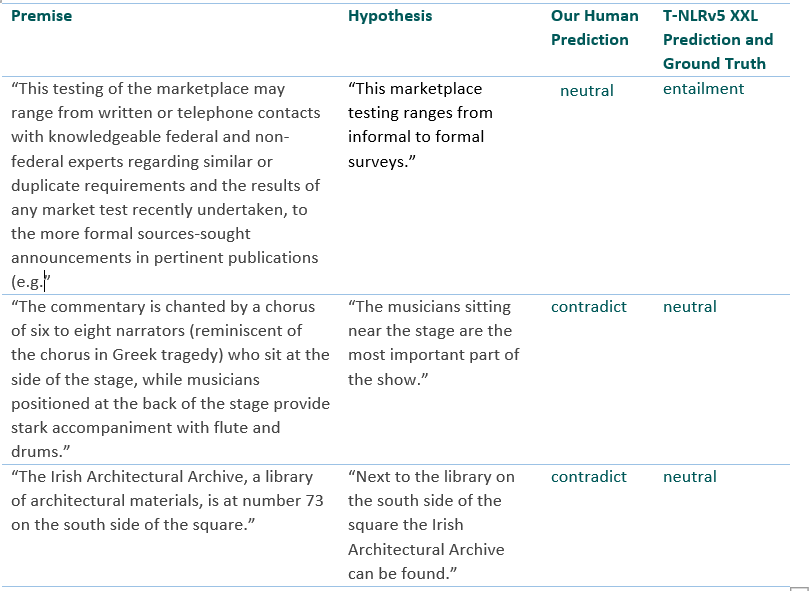
MNLI Dev不匹配的例子,任务是预测前提句是否与假设相联系/相矛盾或中性
出乎意料的是,在一些相当困难的例子中,T-NLRv5 XXL模型成功地做出了正确的预测,而论文的其中一个作者则判断错误。
T-NLRv5在SuperGLUE和GLUE排行榜上进一步超越人类的表现,再次将NLP模型的水平带到一个新的层次,未来通过不断改进这些模型,还可以带来更智能的基于语言的AI产品体验。
参考资料:
https://www.microsoft.com/en-us/research/blog/efficiently-and-effectively-scaling-up-language-model-pretraining-for-best-language-representation-model-on-glue-and-superglue/
![]()