重磅 | 从SwiftScribe说起,回顾百度在语音技术的七年积累

人与机器的自然交互一直是人类孜孜不倦的奋斗目标。随着移动互联网时代的发展,声音与图片成为了人机交互更为自然的表达方式。作为最核心的入口,语音技术就成为了科技巨头们争相攻下的堡垒。而人工智能的进步与发展也让语音技术的识别率突飞猛进,也使其有了产品化的机会。
李彦宏曾在剑桥名家讲堂等多个公开场合说过,百度大脑涉及百度最为核心的人工智能内容,具体包括语音、图像、自然语言理解和用户画像等四个核心能力,此外还有机器学习平台;吴恩达也在公开场合演讲时表达了同样的观点。
3 月 14 日,百度硅谷研究院于推出了一款基于人工智能的转录应用 SwiftScribe ,它基于百度于 2015 年年底推出的语音识别产品 Deep Speech 2,其神经网络通过输入数千小时的标记音频数据,从中学习特定的单词与词组。百度推出 SwiftScribe 主要面向经常需要使用转录功能的企业及个人,甚于它的使用广泛性,能够让一大批用户受益,包括医学健康、法律部门、商业媒体等领域。
语音技术主要分为识别与合成两大领域,对于百度而言,历年来的研究院技术突破也让识别性能有了重大的提升。AI科技评论整理了百度在语音技术的相关研究成果,借此抛砖引玉,得以一窥百度在语音领域的技术积累。
语音识别

via yuyin.baidu
早在 2010 年,百度开始进行智能语音及相关技术研发,并于同年 10 月在掌上百度上推出语音搜索,当时的宣传语是这样说的:「语音搜索就用掌上百度」,这也是第一代基于云端识别的互联网应用。
在 2012 年左右,研究者们开始采用 DNN 进行语音识别的相关研究。经过近两年的发酵,2012 年 11 月百度上线了第一款基于 DNN 的汉语语音搜索系统,这让百度成为最早采用 DNN 技术进行商业语音服务的公司之一。研究显示百度在当时就呈现了优秀的语音识别能力,「在安静情况下,百度的普通话识别率已达到 95% 以上」。
在 2013 年 1 月,李彦宏提出百度成立深度学习研究院,并于同年 4 月设立了硅谷人工智能实验室,彼时AI科技评论也做过相关覆盖与报道。而隔年百度硅谷人工智能实验室(SVAIL)正式成立,加上吴恩达的加盟,更多的研究与投入也让百度开始在语音技术上展露头角。
根据吴恩达在百度语音开放平台三周年大会上的演讲,百度于 2014 年采用 Sequence Discriminative Training(序列区分度训练),当时的识别准确率为 91.5%。
在同年年底,吴恩达带领团队发布了第一代深度语音识别系统 Deep Speech 的研究论文,系统采用了端对端的深度学习技术,也就是说,系统不需要人工设计组件对噪声、混响或扬声器波动进行建模,而是直接从语料中进行学习。
团队采用 7000 小时的干净语音语料,通过添加人工噪音的方法生成 10 万小时的合成语音语料,并在 SWITCHBOARD(沿用近20年的标准语料库,被视为识别的“试金石”) 上获得了 16.5% 的 WER(词错误率,是一项语音识别的通用评估标准)。当时的实验显示,百度的语音识别效果比起谷歌、Bing 与 Apple API 而言优势明显。
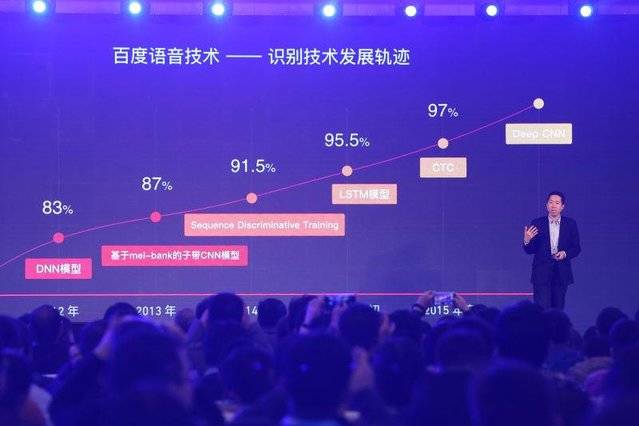
AI科技评论了解到,近年来在 ImageNet 的竞赛中,CNN 的网络结构在不断加深(比如微软亚洲研究院的 152 层深度残差网络),错误率则逐步下降。百度通过借鉴这一研究进展,将深度学习在图像识别领域的进展应用于语音识别,尝试将 Deep CNN 架构配合 HMM (隐含马尔科夫模型)语音识别系统,也呈现出很好的表现。
而 2015 年初基于 LSTM-HMM 的语音识别技术也逐步发展为基于 LSTM-CTC (Connectionist Temporal Classification)的端对端语音识别技术,通过将机器学习领域的 LSTM 建模与 CTC 训练引入传统的语音识别框架里,提出了具有创新性的汉字语音识别方法。
2015 年 8 月,百度研究院新增了汉语的识别能力,准确率高达 94%。这也让端到端的深度学习算法成为语音识别提升最重要的手段之一。在 2015 年 9 月份的百度世界大会上,吴恩达也在较为嘈杂的情况下,验证了机器的语音识别已经超过人类;而李彦宏彼时也宣布,百度语音识别的准确率能够达到 97%。
而在 2015 年年底,百度 SVAIL 推出了Deep Speech 2,它能够通过深度学习网络识别嘈杂环境下的两种完全不同的语言——英语与普通话,而端到端的学习能够使系统处理各种条件下的语音,包括嘈杂环境、口音及区别不同语种。而在 Deep Speech 2 中,百度应用了 HPC 技术识别缩短了训练时间,使得以往在几个星期才能完成的实验只需要几天就能完成。在基准测试时,系统能够呈现与人类具有竞争力的结果。(AI科技评论按:HPC 指的是使用多处理器或某一集群中的数台计算机搭建的计算系统与环境,百度所应用的 HPC 技术实际上是 OpenMPI Ring Allreduce的修改版本。)
得益于在语音交互的突破,百度的深度语音识别技术在 2016 年入选 MIT 十大突破技术。
根据研究院的官方消息,百度 SVAIL 已于 2017 年 2 月成功将 HPC 技术移植到深度学习平台,借此加速 GPU 之间的数据传输速率。该算法以库和 Tensorflow 补丁的形式向开发者开源,分别为 baidu-allreduce 和 tensorflow-allreduce,目前已在 GitHub 上线。
3 月 14 日,百度硅谷研究院也推出了一款基于 Deep Speech2 的 AI 转录应用 SwiftScribe,其神经网络通过输入数千小时的标记音频数据,从中学习特定的单词与词组。
语音合成

via yuyin.baidu
如果说语音识别是让机器听懂人类的语言,那么语音合成便是让机器开口说话。
语音合成即文本转换技术(TTS),根据百度官网的介绍,它是“实现人机语音交互,建立一个有听和讲能力的交互系统所必需的关键技术,是将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的口语输出的技术”。
早期的语音合成做法是机械地将预先录制好的声音拼接在一起,也就是我们经常听到的拼接式合成(concatenative TTS),采用语音编码技术存储合适的语音单元,在合成时通过解码与波形编辑拼接处理后生成相应的语句,一般合成的内容也比较有限,比如自动报时或报站等相对固定的内容,便适合采用这样的方法。
而参数合成法(parametric TTS)则相对复杂,涉及对语音信号的分析并提取参数,再由人工控制参数的合成。但实现合成的全过程可谓兼具高难度与强工作量:首先需要涵盖语音在合成出所有可能出现的声音;随后根据文本的内容选择对应的声学参数,再实现合成。
在 2015 年,手机百度小说频道上线了情感语音合成模块,系统可提供「磁性男声」的朗读版本;而百度新闻也支持语音播报。实际上这两个技术都涉及语音合成技术(TTS)。此外,百度还采用此技术复原了张国荣的声音,目前可达到接近真人的发声效果。
百度 SVAIL 在今年正式推出了 Deep Voice,即一个实时语音合成的神经网络系统(Real-Time Neural Text-to-Speech for Production),目前论文已经投递 ICML 2017。实验显示,在同样的 CPU 与 GPU 上,系统比起谷歌 DeepMind 在去年 9 月发布的原始音频波形深度生成模型 WaveNet 要快上 400 倍。
在去年年末的百度语音开放平台三周年大会上,吴恩达就已经表示,「现在百度在中国语音合成的能力已经达到业界领先的水平。」可见百度在语音合成领域已经是胸有成竹了。
两大应用方向
目前百度的语音技术分为两大应用方向:语音识别(及语音唤醒)还有语音合成。
在语音识别领域,结合自然语言处理技术,百度能够提供高精度的语音识别服务,实现多场景的智能语音交互:
手机百度和百度输入法自不必说,它们能够直接通过语音输入匹配搜索结果,提升输入效率。
主要合作伙伴:艾米智能行车助手;乐视语音助手;海尔智能家居;陌陌;神武游戏等。
而百度的语音唤醒则支持自定义设置语音指令,为应用提供流畅对话。比如:
通过百度语音唤醒技术可以唤醒度秘,满足用户真人化的需求;
在百度 Carlife 、 百度CoDriver 及百度地图中,语音唤醒技术能够帮助驾驶员实现拨打电话、播放音乐、导航等多项操作。
在语音合成领域,最典型的例子莫过于人声朗读了。
百度地图利用合成技术生成导航语音,能够帮助用户实现流畅的人机交互;
iReader 也采用了百度语音合成技术实现语音朗读效果,目前支持中文普通话播报、中英文混读播报,音色支持男声和女声。
主要合作伙伴:塔读文学、AA拼车等。
吴恩达在接受华尔街日报采访时表示了对语音技术的信心与期待:「至少在中国,我们会在接下来几年时间普及语音识别应用,让人机沟通成为一件非常自然的事。你会很快习惯与机器流畅交流的时光,而忘记以前是如何与机器交互的。」AI科技评论也相信,百度未来会在语音技术上取得更大突破,并让人们获得良好的人机交互体验。
相关阅读:
[1] 李彦宏:人工智能的四个核心能力是语音、图像、自然语言理解和用户画像
[2] 百度首席科学家吴恩达演讲:语音技术能为什么带来巨大改变
[3] 百度首席科学家吴恩达:大脑能在一秒内完成的任何工作,都会被AI取代
相关论文:
[4] Deep Speech: Scaling up end-to-end speech recognition
[5] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
AI科技评论招聘季全新启动!
很多读者在思考,“我和AI科技评论的距离在哪里?”,答案就是:一封求职信。
AI科技评论自创立以来,围绕学界和业界鳌头,一直为读者提供专业的AI学界,业界,开发者内容报道。我们与学术界一流专家保持密切联系,获得第一手学术进展;我们深入巨头公司AI实验室,洞悉最新产业变化;我们覆盖A类国际学术会议,发现和推动学术界和产业界的不断融合。
而你只要加入我们,就有机会和我们一起记录这个风起云涌的人工智能时代!
如果你有下面任何两项,请投简历给我们:
*英语好,看论文毫无压力
*计算机科学或者数学相关专业毕业,好钻研
*新闻媒体相关专业,好社交
*态度好,学习能力强
简历投递:lizongren@leiphone.com






