干货 | 只有100个标记数据,如何精确分类400万用户评论?

来源:新智元
本文共2200字,建议阅读6分钟。
本文介绍了面向NLP任务的迁移学习新模型ULMFit,只需使用极少量的标记数据,文本分类精度就能和数千倍的标记数据训练量达到同等水平。
[ 导读 ]在本文中,我们将介绍自然语言处理(NLP)在迁移学习上的最新应用趋势,并尝试执行一个分类任务:使用一个数据集,其内容是亚马逊网站上的购物评价,已按正面或负面评价分类。然后在你可以按照这里的说明,用你自己的数据重新进行实验。在数据标记成本高数量少的情况下,这个通用语言微调模型可以大幅降低你的NLP任务训练时间和成本。
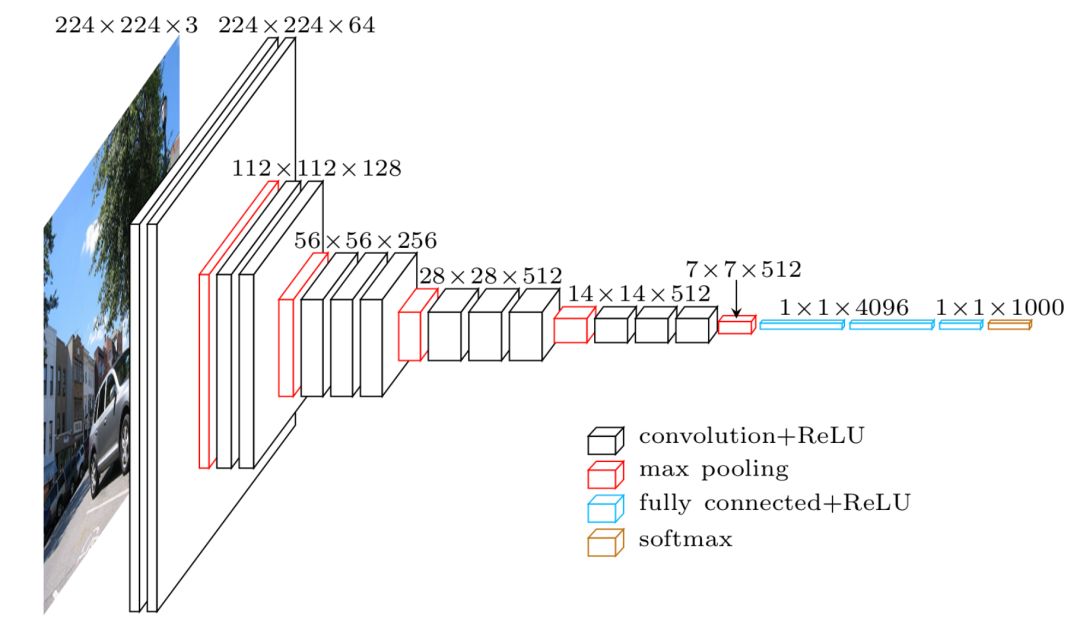
迁移学习模型的思路是这样的:既然中间层可以用来学习图像的一般知识,我们可以将其作为一个大的特征化工具使用。下载一个预先训练好的模型(模型已针对ImageNet任务训练了数周时间),删除网络的最后一层(完全连接层),添加我们选择的分类器,执行适合我们的任务(如果任务是对猫和狗进行分类,就选择二元分类器),最后仅对我们的分类层进行训练。
由于我们使用的数据可能与之前训练过的模型数据不同,我们也可以对上面的步骤进行微调,以在相当短的时间内对所有的层进行训练。
除了能够更快地进行训练之外,迁移学习也是特别有趣的,仅在最后一层进行训练,让我们可以仅仅使用较少的标记数据,而对整个模型进行端对端训练则需要庞大的数据集。标记数据的成本很高,在无需大型数据集的情况下建立高质量的模型是很可取的方法。
迁移学习NLP的尴尬
目前,深度学习在自然语言处理上的应用并没有计算机视觉领域那么成熟。在计算机视觉领域中,我们可以想象机器能够学习识别边缘、圆形、正方形等,然后利用这些知识去做其他事情,但这个过程对于文本数据而言并不简单。
最初在NLP任务中尝试迁移学习的趋势是由“嵌入模型”一词带来的。
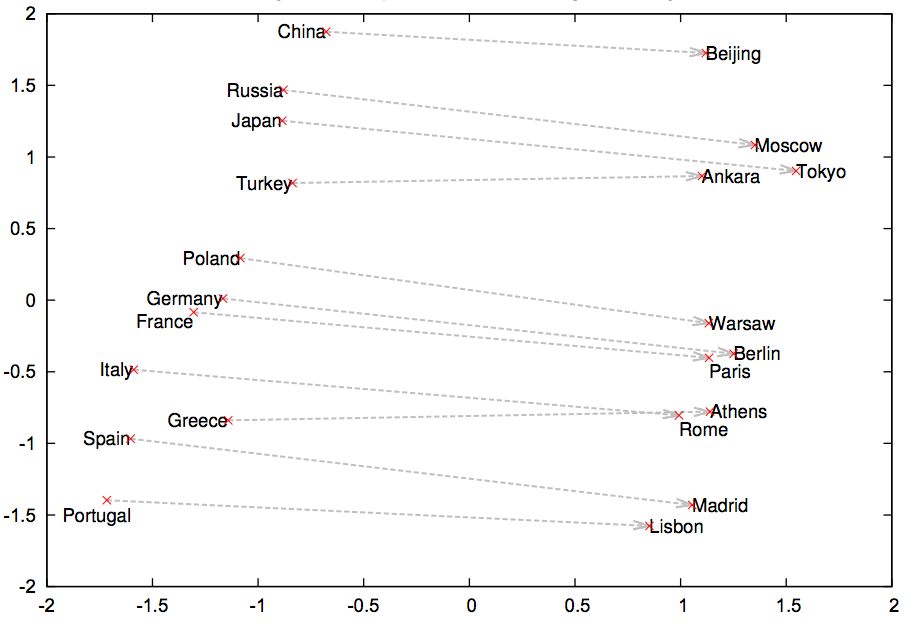
实验证明,事先将预先训练好的词向量加入模型,可以在大多数NLP任务中改进结果,因此已经被NLP社区广泛采用,并由此继续寻找质量更高的词/字符/文档表示。与计算机视觉领域一样,预训练的词向量可以被视为特征化函数,转换一组特征中的每个单词。
不过,词嵌入仅代表大多数NLP模型的第一层。之后,我们仍然需要从头开始训练所有RNN / CNN /自定义层。
高阶方法:微调语言模型,在上面加一层分类器
今年早些时候,Howard和Ruder提出了ULMFit模型作为在NLP迁移学习中使用的更高级的方法。
论文地址:https://arxiv.org/pdf/1801.06146.pdf
他们的想法是基于语言模型(Language Model)。语言模型是一种能够根据已经看到的单词预测下一个单词的模型(比如你的智能手机在你发短信时,可以为你猜测下一个单词)。就像图像分类器通过对图像分类来获得图像的内在知识一样,如果NLP模型能够准确地预测下一个单词,似乎就可以说它已经学会了很多关于自然语言结构的知识。这些知识可以提供高质量的初始化状态,然后针对自定义任务进行训练。
ULMFit模型一般用于非常大的文本语料库(如维基百科)上训练语言模型,并将其作为构建任何分类器的基础架构。由于你的文本数据可能与维基百科的编写方式不同,因此你可以对语言模型的参数进行微调。然后在此语言模型的顶部添加分类器层,仅仅对此层进行训练。
Howard和Ruder建议向下逐层“解冻”,逐步对每一层进行训练。他们还在之前关于学习速度(周期性学习)的研究成果基础上,提出了他们自己的三角学习速率(triangular learning rates)。
用100个标记数据,达到用20000个标记数据从头训练的结果
这篇文章得出的神奇结论是,使用这种预训练的语言模型,让我们能够在使用更少的标记数据的情况下训练分类器。尽管网络上未标记的数据几乎是无穷无尽的,但标记数据的成本很高,而且非常耗时。
下图是他们从IMDb情感分析任务中报告的结果:
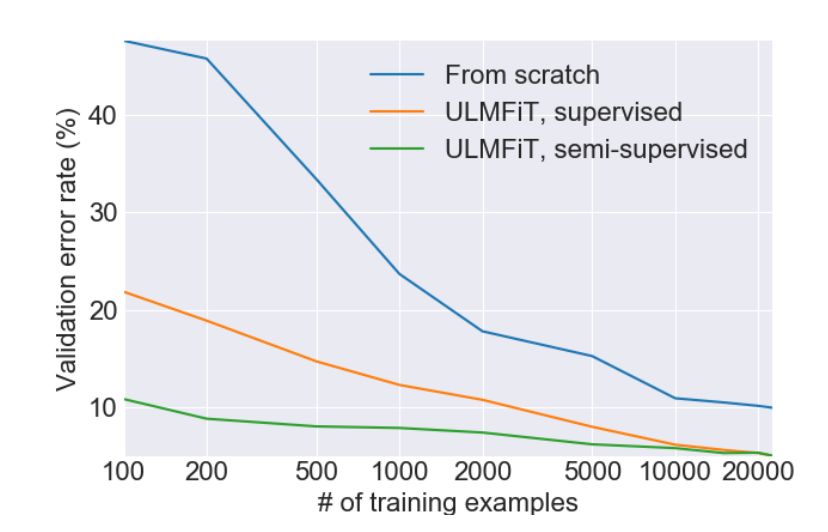
该模型只用了100个示例进行训练,错误率与20000个示例从头到尾进行完全训练的模型相仿。
此外,他们在文中还提供了代码,读者可以自选语种,对语言模型进行预训练。由于维基百科上的语言多种多样,因此我们可以使用维基百科数据快速完成语种的转换。众所周知,公共标签数据集更难以使用英语以外的语言进行访问。在这里,你可以对未标记数据上的语言模型进行微调,花几个小时对几百个至几千个数据点进行手动标注,并使分类器头适应您预先训练的语言模型,完成自己的定制化任务。
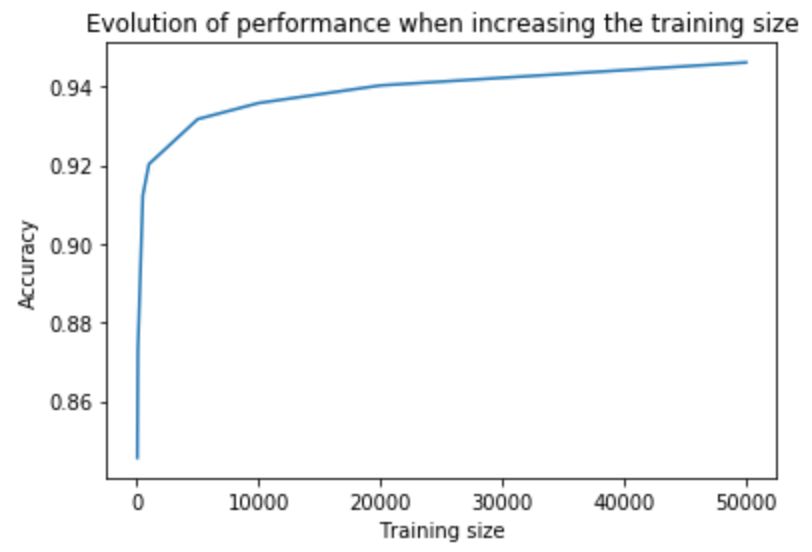
为了加深对这种方法的理解,我们在公共数据集上进行了尝试。我们在Kaggle上找了一个数据集。它包含400万条关于亚马逊产品的评论,并按积极/消极情绪(即好评和差评)加上了标记。我们用ULMfit模型对这些评论按好评/差评进行分类。结果发现,该模型用了1000个示例,其分类准确度已经达到了在完整数据集上从头开始训练的FastText模型的水平。甚至在仅仅使用100个标记示例的情况下,该模型仍然能够获得良好的性能。
所以,语言模型了解的是语法还是语义?
我们使用ULMFit模型进行了监督式和无监督式学习。训练无监督的语言模型的成本很低,因为您可以在线访问几乎无限数量的文本数据。但是,使用监督模型就很昂贵了,因为需要对数据进行标记。
虽然语言模型能够从自然语言的结构中捕获大量相关信息,但尚不清楚它是否能够捕捉到文本的含义,也就是“发送者打算传达的信息或概念”或能否实现“与信息接收者的交流”。
我们可以这样认为,语言模型学到的更多是语法而不是语义。然而,语言模型比仅仅预测语法的模型表现更好。比如,“I eat this computer“(我吃这台电脑)和“I hate this computer”(我讨厌这台电脑),两句话在语法上都是正确的,但表现更优秀的语言模型应该能够明白,第二句话比第一句话更加“正确”。语言模型超越了简单的语法/结构理解。因此,我们可以将语言模型视为对自然语言句子结构的学习,帮助我们理解句子的意义。
由于篇幅所限,这里就不展开探讨语义的概念(尽管这是一个无穷无尽且引人入胜的话题)。如果你有兴趣,我们建议你观看Yejin Choi在ACL 2018上的演讲,深入探讨这一主题。
微调迁移学习语言模型,大有前景
ULMFit模型取得的进展推动了面向自然语言处理的迁移学习研究。对于NLP任务来说,这是一个激动人心的事情,其他微调语言模型也开始出现,尤其是微调迁移语言模型(FineTuneTransformer LM)。
我们还注意到,随着更优秀的语言模型的出现,我们甚至可以完善这种知识迁移。高效的NLP框架对于解决迁移学习的问题是非常有前景的,尤其是对一些常见子词结构的语言,比如德语,经过词级训练的语言模型的表现前景非常好。
怎么样?赶紧试试吧~
参考链接:
https://blog.feedly.com/transfer-learning-in-nlp/
Github相关资源:
https://github.com/feedly/ml-demos/blob/master/source/TransferLearningNLP.ipynb
相关论文:
Universal Language Model Fine-tuning for Text Classification(ULMFiT)
https://arxiv.org/pdf/1801.06146.pdf





