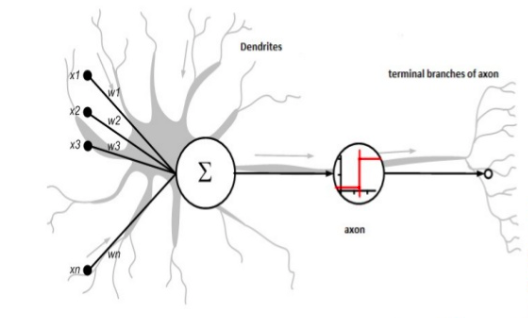
![]()
![]()
来源:北京智源人工智能研究院
我们习惯于用自己熟悉的工具来解决面临的问题。
例如,当想要去探索强人工智能的时候,计算机科学家们想到最直接的方式,便是创建知识图谱(计算机科学家所理解的“常识”),从而将常识与深度学习进行融合,来创造一个在他们看来有认知的智能体。
但是这种“认知”与神经科学家们所理解的“认知”是同一个概念吗?
知识图谱+深度学习,或许能够解决人工智能所面临的困境,但显然不是唯一解。
正如智源研究院“认知神经基础”重大方向的首席科学家刘嘉教授所说,科研领域的重大突破往往产生于交叉领域。因为在交叉地带,一个未知的领域,最可能产生新的东西。
因此,不同学科背景的学者,坐在一起,用着彼此可能并不互通的术语,进行探讨,可能会产生各种意向不到的事情。
在智源研究院,作为机器学习的领军人物颜水成,遇到了认知神经科学的领军人物刘嘉。于是,他们相约在一个午后,共同探讨了大量关于人工智能和生物智能的认知神经基础问题。
正如颜水成所说,这些问题可能并不只是代表他自己,可能许多做机器学习的人都或多或少有过类似的疑问,也希望能够从认知神经科学的研究成果中,获取灵感,从而设计更优的算法。刘嘉教授对此一一作答。
交叉,起于思想的碰撞,这只是开始。
颜水成:依图科技 CTO,智源“机器学习”重大研究方向首席科学家
刘嘉:清华大学教授,智源“人工智能的认知神经基础”重大研究方向首席科学家
颜水成:
今天我更多的是以一种小白的身份向刘嘉老师请教认知神经科学的一些问题,这些问题不只代表我自己,可能许多做机器学习的同学都很想知道,也希望能够从认知神经科学的一些研究成果中吸取灵感,从而能够设计出更好的机器学习算法。
我的第一个问题是,从认知神经科学的角度,GPT-3与人脑的思维方式一致吗?
刘嘉:
我也看了GPT-3,非常了不起。我觉得可能是深度学习巅峰式的成果。
但我也看到一个报道说,如果问它“蜘蛛有几只眼睛”,它会正确地回答“8只”;而如果问它“脚有几只眼睛”,它会回答“两只”。而人类,尽管大部分人不知道蜘蛛有几只眼睛,但绝对不会出现脚有两只眼睛这样明显的错误。由此可以看出,GTP-3和人的思维,在本质上是不一样的。
GTP-3的推理方式更多的是一种概率上的连接,可能在它训练的数据中,出现了“脚”与“眼睛”的某种关联,它就学习出两者之间一种概率链接,在这个过程中,它并没理解“脚”和“眼睛”是什么。而人类则是先理解后推理。
颜水成:那么你认为,如果将GPT与非常庞大的知识图谱进行融合,这会不会与我们大脑的运行机制越来越像?
刘嘉
:肯定会越来越像的。但有一个问题是,知识图谱能够做到什么程度?举个简单的例子,当我们看到一个人不小心踩到一颗钉子,那么知识图谱会产生“他会流血”、“会受伤”,但我们人的第一反应则是自己感到疼,这是一种共情能力,是基于我们对他人心理的一个推理,猜测他现在的感受。
颜水成:最近大家认为感知的问题已经做得差不多了。Bengio等人提出人工智能将从System 1 转向 System 2。我对这方面也做过一些了解,System 1大概相当于我们的潜意识,反应比较快,但不需要做推理;而System 2相当于显意识,需要一个推理、判断的过程。但我了解的这些只是一些皮毛,你能不能给我们分享一下,大脑内部是否有这样两套不同的系统?这对我们以后研究认知,会非常有价值。
刘嘉
:其实Bengio可能受丹尼尔·卡尼曼的《思考,快与慢》的启发。他其实是在说,我们人类有两套系统,一套我们称之为皮层下系统,对应我们脑干等中枢系统;一套是皮层系统,对应我们的大脑皮层。这种结构归因于我们人类的大脑是从低等动物一点点积累起来的。前者比较古老,主要掌管呼吸、心跳等比较初等但与我们生存有密切关系的活动,所以反应比较快,例如我们看到一个老虎出现,它会立刻加强肾上腺素,做出应激反应;而后者,更多的是去理解到底发生了什么事,然后做出推理和判断,例如我们发现原来这个老虎是人扮的,这时皮层系统就会告诉皮层下系统,从而调节原来的紧张。
颜水成:所以,在物理上这是两套完全独立的系统,是吗?
颜水成:我讲System 1和System 1的时候,喜欢讲开车的例子,这是我亲身体会。如果在一个我们熟悉的路,往往不需要做推理,到了某个地方该怎么打方向盘,自动就完成了。而到了一个相对陌生的路,就需要特别小心,去想怎么打方向盘,比较费时。但有意思的是,熟悉了之后,我又能自动完成了。这可以看成从System 1到System 2的转换吧,你能不能从神经科学的角度做一个解释。
刘嘉
:这是特别好问题。在我们学习的过程中,最开始我们不知道怎么去表征外部的世界,在这种情况下,大脑神经的反应模式基本上就是,让与它相关区域的所有神经元全都活动;但第二次可能就只有40%的神经元活动,因为其他的神经元活动已经没有任何意义了;经过反复的学习之后,最终可能只有4、5个神经元去反应,这就是所谓的Sparse Coding。经过Sparse Coding之后,系统会集中在一个特定的任务上,变得非常精准且高效。在这个过程中,开始时需要更多的意识参与,然后逐渐减少而变得自动化。
在这个过程中,其实我们还需要一个警觉系统。比如当我们学会走路后,我们根本不去关心应该先迈哪只脚,以及应该迈多远,完全可以一边走路一边脑袋里想着自己的事情。直到我们突然踩了一个坑,这时候我们的警觉系统就开始起作用了,它会快速启动System 2,对 System 1进行干涉,让你保持平衡而不会摔倒。然后你的视觉注意到原来前面是个大坑,于是马上反应过来改变路径。这个警觉系统就在我们大脑内侧,叫“前扣带回”。
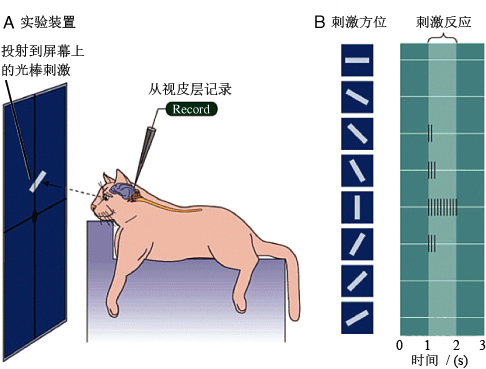
颜水成:计算机视觉从神经科学中借鉴了特别多。例如,人类视觉有V1区、V2区、V3区等,不同的区域处理的粒度不同。神经科学中,是怎么验证这个事情的呢?
刘嘉
:早在1968年,两个诺贝尔奖获得者Hubel和Wiesel他们对猫做实验,将细小的探针插入到神经元上去,然后给猫一个刺激,例如点、线以及其他复杂的图形,然后看不同的刺激会引起哪个脑区的兴奋。他们发现V1、V2、V3、V4等脑区,越往后面敏感的图形越复杂。这个研究说明,我们的大脑在处理视觉信息时,是将复杂的图像还原成局部元素,然后再进行合成的。这种方法事实上到现在仍然在用。
此外,他们还做了一系列关于猫的实验。例如在猫刚生下来的时候,把它的眼睛缝上,完全不给它看任何刺激,过一段时间后,再打开它的眼睛,这个时候再记录它大脑的神经元会有什么样的反应;猫出生后,只给它看横条,一直不让它看竖条,然后记录它的神经元会有什么反应等。这种方式叫做“单细胞记录”,现在的神经电生理研究还在用这种方法。
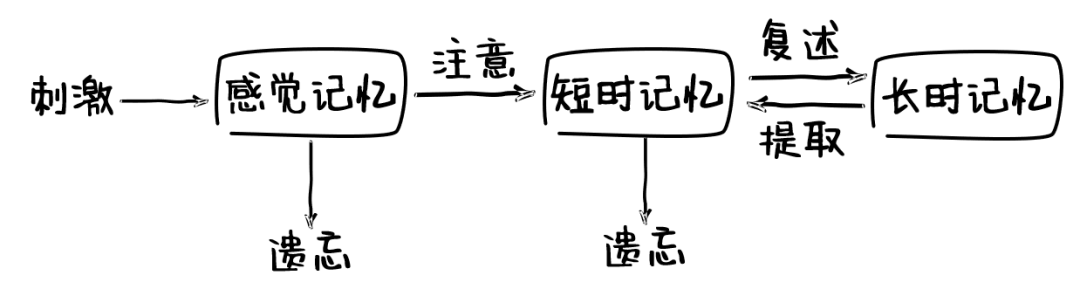
颜水成:我们知道,人会经常忘记一些事情,特别是老年人。那么我们的记忆是真的从脑子里完全消失了,还是被打包存储在记忆深处某个地方了?
刘嘉
:这两种情况都有。首先,我们不可能记得所有的事情,我们的大部分经历都会被忘掉。目前普遍认为人类记忆有三级加工模型,分别为感觉记忆、短时记忆和长时记忆。如果一个信息不能转化为长时记忆,即引起神经元突出的持久改变(例如相邻神经元突出结构的变化、神经元胶质细胞数量的增加和神经元之间突出连接数量的增加),那么它就会被我们彻底地遗忘掉。
另一种遗忘,是说这个记忆还在,但没有找到合适的途径把它提取出来。心理学中曾经有一个研究,他们在做脑外科切除肿瘤的手术时会把病人唤醒,通过微电流刺激相应脑区,来确定切除这块脑区是否会造成严重影响。据一个研究报道,一位六十多岁的老人在某个脑区受到刺激时,脑海里突然复现出他两三岁时母亲给他唱的摇篮曲。而事实上他的母亲很早就去世了,他从童年期到六十多从来都没有听过这支摇篮曲。这说明,这个信息还在那里,只是没有找到合适的方法把它提前出来。
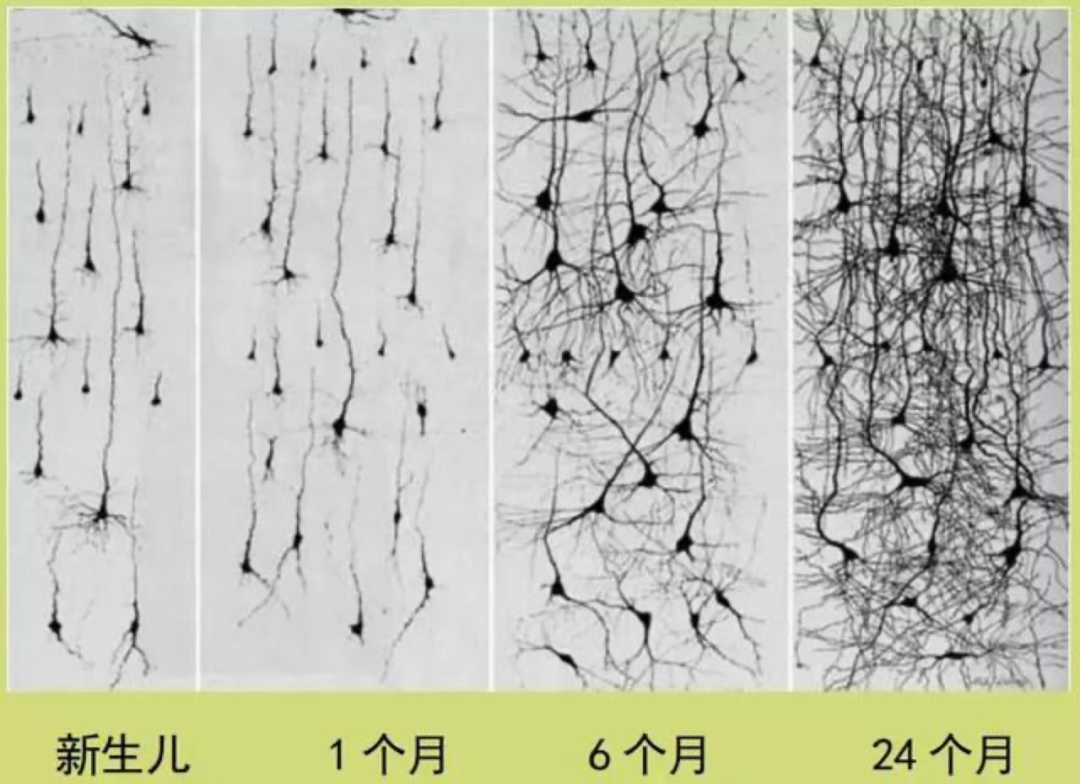
颜水成:我看到一个说法是,人脑神经元的数量从出生之后就不会再增长,是这样吗?
刘嘉
:对,我们出生后神经元的总数基本上就不会再变化,变化的是神经突触的数目以及神经元之间的连接。出生时,婴儿大脑皮层突触密度远低于成人;但出生后的几个月内,大脑皮层突触迅速增加,4岁左右,大脑皮层突触的密度会达到顶峰,约为成年人的150%。类比人工神经网络的话,你可以理解为一个全连接系统。随后,随着年龄和经验的增长,突触数目会慢慢减少,一些连接就会剪断。但也正是这样,我们反而变得更加聪明。
颜水成:我们所有人的神经元数目可能不一样。会因为神经元数量的多少,影响我们的智力水平不?
刘嘉
:不同的人,神经元数目也不同,但人类的智商似乎不受神经元数目的影响,或者至少可以说神经元数目不是决定智商的本质因素。
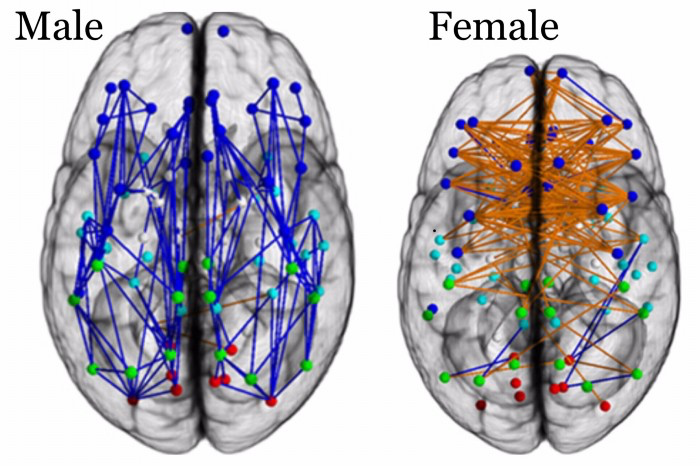
举例来说,男性的大脑平均而言要比女性重100克左右。但从来没有任何证据表明男性会比女性更聪明。从IQ上来讲,两者是一样的。
2013年宾夕法尼亚州立大学的Madhura Ingalhalikar等人发现男性和女性大脑在神经元连接上有较大差异。
参考
:Sex differences in the structural connectome of the human brain,
https://www.mit.edu/~6.s085/papers/sex-differences.pdf
事实上,我们人与人之间神经元数目也是不一样的,一个大致的估计认为,人类的神经元数量在800亿到1000亿之间,也即是说,不同的人之间相差100亿个神经元是一件很正常的事情。
所以一个猜测认为,真正决定我们人类智能的,不是我们神经元的数量,而是它们之间的连接。这些连接,很大程度上取决于我们后天的学习。
颜水成:人的神经元数目从出生后基本上是固定的。作为对比,人工智能却可以通过不断地加算力来提升它的运算规模,也可以把网络结构做的越来越复杂,从而使其性能不断增长。所以从这个角度来,人工智能反而有一定的优势。
刘嘉
:对。这是人工智能的优越性。我认为人工智能超越人类智能,只是一个时间问题,因为它有无限的算力、无限的存储能力,能够无限地扩展下去。
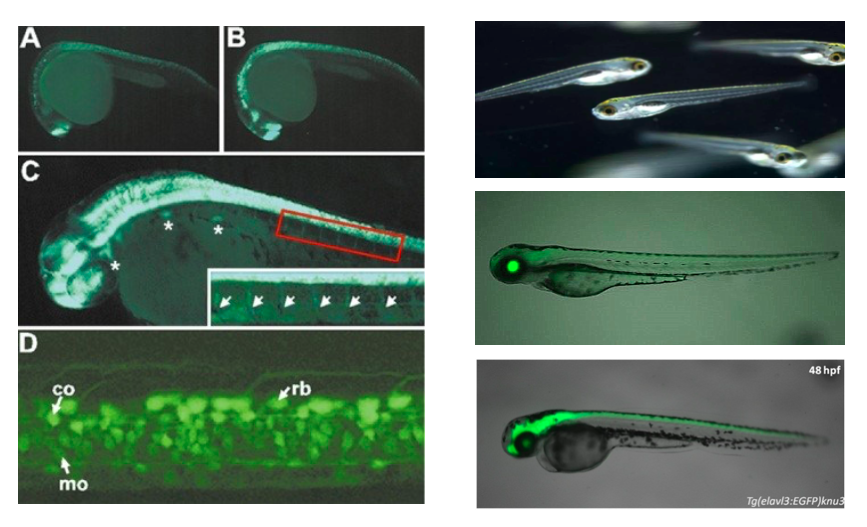
另一方面,你可以看到,通用智能其实不是人类所特有的,是所有生物体都有的。例如斑马鱼只有80万~100万个神经元;小鼠有1亿量级的神经元;狨猴神经元量级在10亿左右;恒河猴在百亿;而人类在千亿量级。但无论是斑马鱼也好,还是老鼠、狨猴、恒河猴,或者人类,它们都具有通用智能。
神经系统特异标记的斑马鱼,图片来自「国家斑马鱼资源中心」
所以,我猜测,生物智能应该有一套规则,这套规则本身与神经元数量无关,而正是这套规则使得我们生物具有了通用智能。也正是这样的规则使得斑马鱼与GPT-3有明显的区别。这套规则就是通用智能的基础。
人工智能的发展,一方面,我们可以增加它的规模(例如神经元数目、更复杂的参数、更大的算力等),这是一个方向。
另外一个方向,我们应该反过头来理解一下,对于那些比较简单的神经元系统——生物的神经元系统,例如斑马鱼,是怎么能够只用这么一小点神经元便可以获得通用智能的。目前我们搭建一个100万数量级的神经元仿真平台,在技术上已经不是一个太难的问题,所以我们可以看看能不能仿真出斑马鱼的智能。同样,我们也可以不断增加它的规模,去仿真老鼠、狨猴,甚至人类的大脑。
一旦我们把这种通用智能的规则搞清楚了,加上人工智能的无限可扩展能力,我觉得未来的人工智能发展,将不可限量。
颜水成:我们人类的学习过程,大多情况下是一种无监督学习,通过在物理世界中,跟环境接触/观察,从而引起突触的变化。这套机制与GPT-3有很大差别。我个人曾提出“Baby Learning”的概念,核心来说就是要摆脱现在依赖标签数据的现状,给一些数据,能够从数据中自动学习出一些知识来。现在人工智能里面也有两个方向,一个叫自训练,也即从数据中预测标签,然后用预测标签作为新的标签,来帮助训练模型;另一个叫自监督学习,也即通过pre-text tasks来训练。
我想了解一下,小孩子从出生之后,他/她的神经元突触之间到底经历了怎样一个过程,能够慢慢优化,变成一个饱含知识的智能系统的呢?这方面其实我也查了一些书,但没有找到太多有价值的信息。这方面的研究处于什么状态?
刘嘉
:从发育的角度来看人类智能的发展,现在还处于一个比较分离的状态。
大家目前的研究更多地集中在认知功能的变化上,但这些却缺少神经学上的证据。另一方面,我们对神经元突触之间的连接怎么搭建有了很好的研究,但却忽略了它功能上的变化,即为什么会这么搭,搭建之后发生了什么改变等,却不清楚。这是目前研究的一个空白点,背后的主要原因是伦理的约束。
颜水成:是什么因素让突触从原来连接状态变成不连接,或者反过来呢?
刘嘉
:针对这个问题,上世纪50年代,一位神经生理学家唐纳德·赫布曾提出一个理论“赫布理论”,描述了突触可塑性的基本原理。简单来说就是“Cells that fire together, wire together”,即当两个神经元同时发放时,它们就会产生连接。
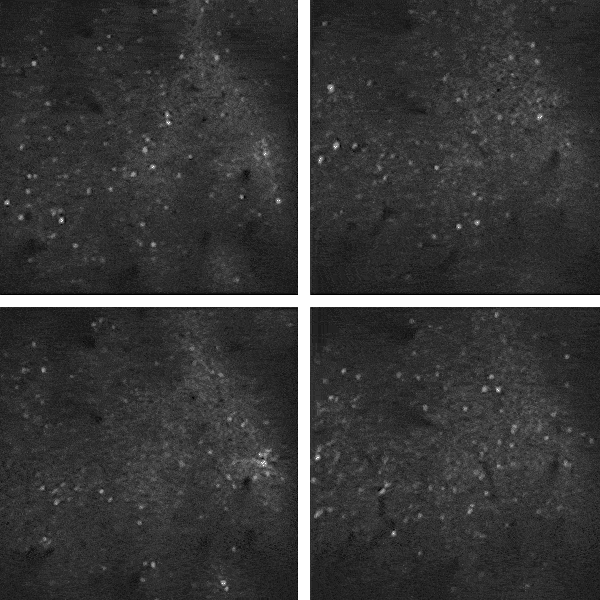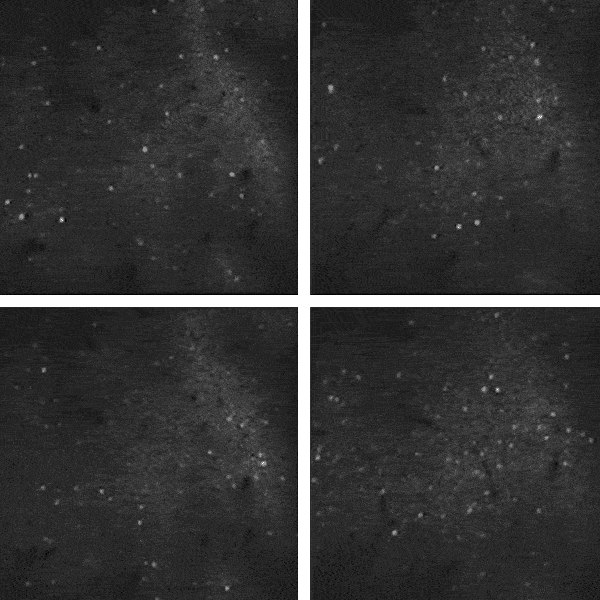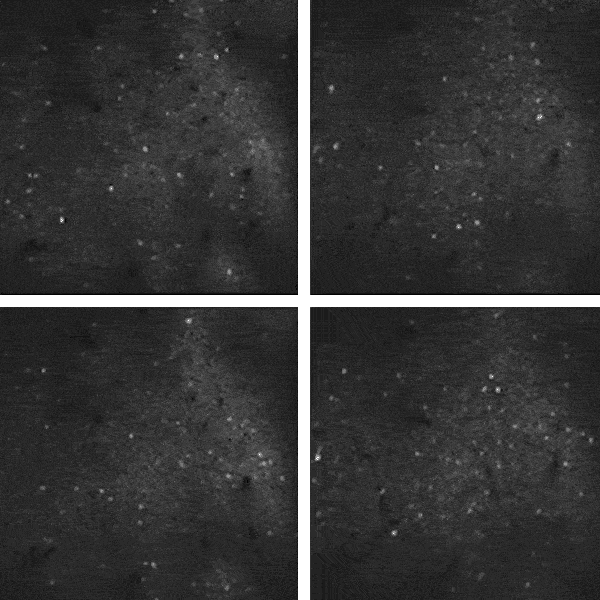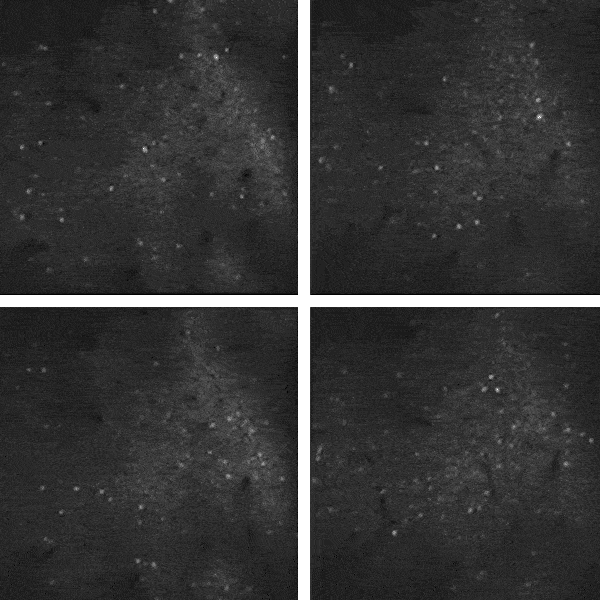
另外,我们大脑里有很多噪音,这些噪音是神经元一些自主地放电活动,即使我们处于静息状态也会有,这些噪音事实上消耗了大脑95%的能量。过去我们认为噪声就只是噪声。但大约在10年前,神经科学家们发现,其实这些噪音是有模式的,正是这种模式试图把不同的神经元进行沟通。
![]() 研究人员研究小鼠视觉皮层中1万多个神经元的自发活动,其中大量信息是“噪声”,与视觉活动无关。图中闪光代表神经元发送信号。
举例来说,两个神经元以同样的频率同步发放信号,那么他们就会保持一种连接状态;而如果它们是异步发放噪音,那么即使它们现在处于连接状态,这种连接也会慢慢衰退。
人们通过对这种静息状态的噪音进行研究,认为这可能与我们的学习有关系。首先即使我们现在可能没做任何事情,其实我们的大脑也没有停下来,它在不停地发放噪音;而如果两个神经元处于连接并同时发放信息,在下次学习时这两个神经元还能够同时发放,就会增强这种连接,逐渐形成稳定连接。
研究人员研究小鼠视觉皮层中1万多个神经元的自发活动,其中大量信息是“噪声”,与视觉活动无关。图中闪光代表神经元发送信号。
举例来说,两个神经元以同样的频率同步发放信号,那么他们就会保持一种连接状态;而如果它们是异步发放噪音,那么即使它们现在处于连接状态,这种连接也会慢慢衰退。
人们通过对这种静息状态的噪音进行研究,认为这可能与我们的学习有关系。首先即使我们现在可能没做任何事情,其实我们的大脑也没有停下来,它在不停地发放噪音;而如果两个神经元处于连接并同时发放信息,在下次学习时这两个神经元还能够同时发放,就会增强这种连接,逐渐形成稳定连接。
颜水成:另外一个方向我特别感兴趣。如果某个样本只出现少数几次的话,从机器学习的角度来讲,最好的策略就是直接把这个样本存储下来,而非再用它去训练模型;需要的时候直接查询匹配即可;而对那些经常出现的样本,则需要训练模型,通过模型来查找。那么在我们大脑中是否有类似的机制呢?
刘嘉
:有。其实我们大脑就是采用的这种机制,我们称它为“混合模型”。
举例来说,我们学习英语时,大部分动词的过去时都是在单词后面加“-ed”,这就是所谓的语法规则;但有一些动词,它的过去时是不规则的,学习这些动词时,干脆直接把它们放在记忆里,需要的时候直接从记忆中调用。按照乔姆斯基的说法,先走这套规则的系统(因为简单),然后再走记忆的部分。
我们的面孔识别,也是一个类似的混合模型。我们对人脸表情的识别,事实上是有一套规则的,例如“嘴角上扬”一般表示高兴;而“最佳下搭”或“嘟嘴”可能表示不满等。但除了这一部分外,我们还有“Theory of Mind”,我们会在心中推理在当前情景下你为什么做出这种表情,有可能是真的开心,也有可能只是装出来的开心,它其实和我们的经验有关。
颜水成:小孩子学习,视觉和听觉都很关键。那么在大脑里边,对视觉和听觉的处理是否会有显式分区呢?
刘嘉
:是的。从感知系统来讲,每一种感觉都有专门的处理区域,例如视觉在枕叶部分,听觉在颞叶,触觉在顶叶等,这些不同的感知信息会单独进行加工。但随后这些信息会进入一个联合区,进行整合,最终形成一个整体的感知反应。因此,我们经常会出现一些好玩的错觉,例如我们眼前有一个螺旋的同心圆,如果我们是站着看它,就会很容易发生偏倒,这说明视觉影响了我们的平衡觉。
另一方面,除了联合区之外,不同的感觉区也会相互影响。第一个例子是先天盲人,他生下来就没有看见任何东西,他的视觉其实完全没有用,但实验发现他的视觉皮层神经元,会对听觉信息进行编码,即参与了听觉信息的加工。
另外一个例子,在哲学上一直探讨了很多年,即假如一个先天盲人,从来没有看见过这个世界,那么当有一天他突然能够看到这个世界了,他会知道“圆”这种概念吗?以前主要是哲学思辨,但随着医学的进步,有一些先天盲人,例如先天白内障患者,可以通过手术来恢复视觉。MIT的一位教授于是做了一个研究,结论非常惊人。当这个人睁开眼睛看到这个世界时,问他哪个是“圆”,哪个是正方形,他会犹豫一会儿,但仅只要十几秒时间,患者就能准确地指出这些形状。这个实验说明,他能够在非常短的时间里将触觉经验转换为视觉经验。这个转换过程,在大脑里是怎么发生的呢?我们目前还不清楚,但至少有一点结论,即:不同的感知信息处理模块之间,并不是完全独立的,而是随时在发生相互影响。
颜水成:我们常常提到将常识加入到人工神经网络中,从而来提升模型的推理性能。那么在大脑中,常识是以什么样的方式存在呢?
刘嘉
:最开始,我们认为常识完全与后天经验有关,是一种知识。但现在我们逐渐意识到,常识可能不是一种知识,而是一套规则。我们普遍认为,没有常识,就没有推理。常识是我们对外部世界形成的一个认知模型,基于这个认知模型,我们去做推理,预测外部世界的运作。
对于其具体的机理,现在也有很多认知科学家搭建各种模型,包括经典的AI也尝试去回答常识到底是以什么方式存在这样的问题。但目前我们来看,这些模型都不太完美。
有两点是我们现在比较确定的。第一,常识主要存在于我们的前额叶部分。在过去300万年里,我们人类大脑体积增大了三倍,这里面最主要的增加的部分就是前额叶,我们认为人类对规则的理解和推理都发生在这里。
第二,有大量证据表明,我们许多常识来自于先天的基因。这种来自于基因的常识会让我们人类生下来就会习惯于用某种方式去做事,例如泛化能力,小孩子看到一只毛茸茸的猫,他会疯狂地泛化到其他毛茸茸的动物上,然后再慢慢修正这种泛化的结果。此外对于蛇的恐惧也是这样,我们先天的基因已经告诉我们这种又细又长危险。但是这种存于基因的常识是怎么来的?进化过程中是怎么做到的?我们大脑在进行这种推理时,神经机制到底是什么?我们都还不清楚。但我觉得孩子给我们提供了一个非常好的参考。
颜水成:我们常常会出现在这样一种情况,看到一位非常熟的人,但怎么也想不起他的名字,然后当有一个极小的线索出现的时候,一下子就想起来了。这个过程,在大脑中到底发生了什么?
刘嘉
:这个现象心理学家也很早就在研究了。他们提出了许多模型,一个比较有影响力的模型叫做“野火模型”(注:在心理学中常叫做“激活扩散模型”),从一点把火点起来,它就会往四周燃烧;一个线索的出现就会把相邻的东西给激活。
![]() 激活扩散模型示意图
这其实涉及到语义信息的存储和表征。名字通常是孤立存储的,但场景或其他信息却可能有更为广泛的联系。那么语义记忆(Semantic Memory)是在不同维度上是怎么存储的呢?比如场景的维度、情感的维度等,哪些维度该有哪些维度没有?目前比较统一的看法是,这更多的是和我们的经验有关系,这种存储更多的是为了便于我们去生存、社交等,然后将其中重要的因素作为存储维度。
但什么是重要,什么是不重要的?这就要回到一个最根本的问题了,即智能的目的是什么。从认知神经科学角度的一个理解认为,智能的目的就是对变化环境的适应。从这个角度来评价重要性问题。
激活扩散模型示意图
这其实涉及到语义信息的存储和表征。名字通常是孤立存储的,但场景或其他信息却可能有更为广泛的联系。那么语义记忆(Semantic Memory)是在不同维度上是怎么存储的呢?比如场景的维度、情感的维度等,哪些维度该有哪些维度没有?目前比较统一的看法是,这更多的是和我们的经验有关系,这种存储更多的是为了便于我们去生存、社交等,然后将其中重要的因素作为存储维度。
但什么是重要,什么是不重要的?这就要回到一个最根本的问题了,即智能的目的是什么。从认知神经科学角度的一个理解认为,智能的目的就是对变化环境的适应。从这个角度来评价重要性问题。
颜水成:有个小问题,人在学习新鲜事物时,是怎样一步步激活的?
刘嘉
:人类学习特别厉害的一点就是,当我们学习一个东西时,并非孤立地学习。以物体识别为例,我们首先会构建一个多维的物体空间(Object Space),当出现一个从来没有见过的事物时,我们首先会根据各个维度对它进行拆解,然后把这个物体映射到这个多维空间中,看它最终会和哪个东西比较接近,从而判断这两个是同类。例如我看到一个毛茸茸的东西,我知道它可能是皮毛;运动,是动物;在吃肉,是肉食哺乳动物等,然后我发现它与老虎的表征比较相近,于是我会判断它是老虎。尽管我似乎什么都没做,但实际上已经做了一大堆假设。这些假设来自于我过去的经验。验证这个事物是老虎后,它就形成了我的经验,当再次遇到这个事物,我就不用从零再学习它。
颜水成:当前的技术可以精确地测量每一个神经元的Action吗?
刘嘉
:以前不可以,现在已经可以通过双光子显微成像技术等精确记录一个神经元及它的发放过程了。现在准确记录大脑所有神经元的每一刻活动只是一个时间和技术问题。
刘嘉
:不需要,可以活体成像。我们“认知神经基础”方向有位陈良怡老师,他现在主要做的就是精确测量斑马鱼的神经元活动。斑马鱼神经元总数不多,且比较透明,容易成像。陈良怡做的不是只看一个神经元,而是看全部近百万的神经元,看它们怎么共同发放,它们的突触怎么变化等。这是一条活的斑马鱼的完整影像,对于机器学习的的研究也会是一种启发。我们随后准备把这些数据共享出来,让大家一起来看斑马鱼在做学习的过程中,80万个神经元是怎么连接、怎么分开以及怎么完成任务的。
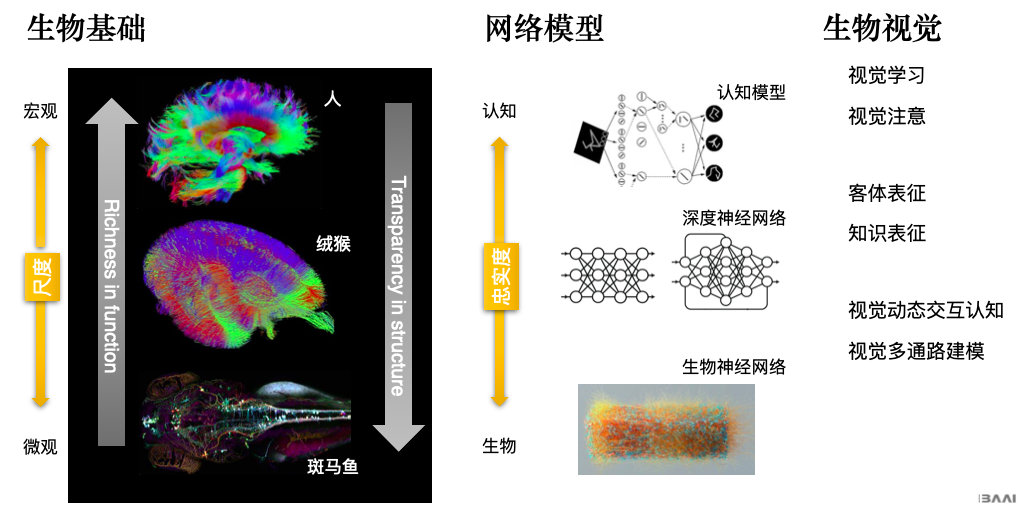
![]() 智源研究院认知神经基础方向的研究框架
再往高级一点走,我们现在准备做绒猴的大脑精细结构。狨猴大概有10亿量级的神经元。针对绒猴,我们首先可以用磁共振看它的整个大脑是怎么活动的;然后用钙成像,看它某个区域是怎么活跃的;然后用双光子成像,去看神经元层面上是怎么活动的。从这三个层面,我们可以把整个大脑、脑功能区一级神经元层面完整地重构出来。我们会基于这些数据建立一个生物智能的开源开放平台,所有数据可以开放使用。我们可以从这些数据中去了解狨猴是怎么识别一个物体、怎么快速反应等智能的本质。
智源研究院认知神经基础方向的研究框架
再往高级一点走,我们现在准备做绒猴的大脑精细结构。狨猴大概有10亿量级的神经元。针对绒猴,我们首先可以用磁共振看它的整个大脑是怎么活动的;然后用钙成像,看它某个区域是怎么活跃的;然后用双光子成像,去看神经元层面上是怎么活动的。从这三个层面,我们可以把整个大脑、脑功能区一级神经元层面完整地重构出来。我们会基于这些数据建立一个生物智能的开源开放平台,所有数据可以开放使用。我们可以从这些数据中去了解狨猴是怎么识别一个物体、怎么快速反应等智能的本质。
颜水成:不同的生物,它们的神经元内在的机理是否有差别呢?
刘嘉
:基本上是类似的。神经元本身有很多种类型,但在动物中,大家的神经元类型基本上是差不多的;有可能在人脑的某个区域,某类神经元会多一些或少一些,但并不存在什么神经元是人类或其他动物独有的。
所以,从这一点上讲,其实无论是斑马鱼也好,老鼠、猴子,还是人也好,他们其实都有通用智能,都能够适应自然的开放环境。
既然大家在物理实现层次上都是一样的,尽管在量级上不一样,但却最终都能够完成通用智能。这说明,背后一定有一个规则来产生通用智能。因此,我觉得通过这种跨物种的对比研究,我觉得我们能够把这个规则找出来。这也是我们现在正在努力的一个方向。
颜水成:很多科幻片中都在讲,把一个人所有的记忆全部copy下来,复制到机器人上(最典型的一个电影《Chappie》)。你觉得随着技术的发展,在未来二三十年里,认知神经科学的技术上有可能达到这样的程度么?或者我们在电脑或超级计算机里,能否近似地模拟大脑?
首先,我们来问:我们的记忆是否能够下载到一台计算机中呢?这个问题是非常吸引人的,如果可以,那就意味着永生,因为记忆是我们最核心的东西。但事实上,其实大家满怀疑的,因为有观点认为,我们的记忆是靠突触之间的连接而存储的,但这并不是说我某两个突触连接就代表某个记忆,而是很多突触的一种分布式连接,然后才是某个记忆。我们必须完整地、不出现任何差错地copy所有连接,才能恢复这些记忆。这种想法,本身是一种还原论的思想,还原到每一个突触连接。
假设我们技术上可以做到这一步,把大脑切片,切得足够精细,重现所有连接。但它会产生同样的功能吗?我认为不会。在大脑中,神经元存在的环境和计算机中 0 1 代码的环境是不一样的,你还得去通过某种方式复现大脑所存在的整个复杂环境,否则的话,即使连接相同,参数不同,它也会产生完全不同的后果。所以我觉得是比较困难的,针对复制大脑来实现永生这个梦想,我是悲观的。
颜水成:人们认为人在睡觉的时候,其实大脑仍然在工作,它会清洗掉一些信息,以便第二天继续工作。关于梦,从神经科学的角度怎么解释?
因为人可能是动物中唯一一种有深度睡眠的动物。像鸟、马等,它们在睡觉的时候,其实不是两个半球同时沉睡,而是交替入睡。例如我家养的猫,轻轻一碰它,它就会醒;而如果我睡着的话,即使把我抬扔了,我都完全不知道。人类睡眠的这个特点,很可能是因为我们在进化时利用了洞穴,后来建立了城邦,有了这种安全的环境,使得我们可以放心大胆地睡觉。
大家认为人类的这种睡眠模式,对人类智力的提升可能起到一个非常关键的作用。为什么呢?我们人类在睡觉的时候,其实大脑并没有完全休息,他在重放我们白天所经历的一些事情,把其中关键的信息提取出来,并遗忘掉哪些不重要的东西。我们白天所感知到的信息都是具象的,但经过我们大脑这种睡眠时的重放,就能够变成一种抽象的东西。这个过程,我们现在知道它发生在海马体,海马体与我们的记忆和学习有关。
刘嘉
:其实梦的定义就是一种学习;其次它也在不断地做不同的假设。人的学习是一种主动学习,学习之后会做一些预测,当然这些推测很多时候是不靠谱的,所以你会觉得梦稀奇古怪的,没有任何逻辑目的。
颜水成:有些时候人在梦境中是知道自己在做梦的。这是怎么回事?
刘嘉
:这是因为我们的意识在随时在监视我们的大脑,这个时候,我们会感知到自己在做梦。
颜水成:所以我们的显意识能够知道,哪一部分信息是通过外部感知逐步分析出来的,哪些是由我们大脑自己产生的?
刘嘉
:很多时候,我们会分不清哪些来自真实,哪些我们的想象或梦境。举例来说,几个人同时目睹了一场凶杀案,作为没有任何利益关系的目击者,我们会发现他们对现场的回忆并不一致。这是因为他们已经对这个现场做了许多自己的猜测、推理等。这个过程是不由自主的,不受个人控制。所以常常我们在说一个事实,实际上,你只是在解释一个事实。
睡眠的重要性就体现在这里,它能够对我们白天所经历的事情进行重构。
曾经有一个剥夺做梦实验。在前一天让被试学习一些东西,然后在当天晚上睡觉时,每当他进入“快速眼动”阶段(这是我们正做梦的信号),就把他叫醒。实验发现,这些被剥夺梦境的被试在第二天的成绩相比没有剥夺的被试,成绩要差很多。
颜水成:神经元的胞体和突触都在进行信息处理,它们的复杂度在量级上哪个为主?
刘嘉
:他们的复杂度都比较高,主要还是胞体更高一些,但是很难说它们在数量级上有差别。神经元有很多树突,既有兴奋的,也有抑制的,既有远端的,也有近端的,当很多因素合成在一起时,胞体就需要做很多信息的整合,这形成了一个非常复杂的动态系统。
我比较想特别强调的一点是,在我们现有的DNN里面,更多的仿真突触,其实没有神经元胞体,感知器是一个哑神经元,没有任何结构。
颜水成:那在里面加的threshold或非线性函数,可以看做神经元的一个功能吗?
刘嘉
:Threshold是神经元的一个功能,但这里强调的是,目前的DNN是没有神经元胞体的成分的。
提到这一点,我觉得你当时做的一个非常有影响力的工作:Network in Network,真的是把神经元的功能加进去了,因为你有一个局部计算。而主流的DNN其实没有局部计算,只是在改变网络之间的连接强度,顶多也就加了一个threshold这样一个功能。
颜水成:我们当时提出我们的工作时,也是这样一个动机,就是神经元不应该这么简单。现在,比较火的图神经网络,似乎能够做更好的知识表示、学习和推理。它有信息的传递,同时在内部还有单层/多层的网络。所以图神经网络是不是非常接近你说的拥有神经元胞体内部处理机制?
刘嘉
:我是这么认为的。从你们的Network in Network开创这个方向,我觉得就是从和人的相似性来讲,图神经网络是一个非常有生命力和前途的方向。
目前在这个世界上,人类的大脑是最好的智能体。我们应该去看它怎么工作。现在人工智能的研究有两种方式,一种是不管人脑怎么干,我们凭经验设计一套规则来做;另一种是看人的智能是怎么产生的,然后进行类比或仿真。我觉得后者成功的概率会更大一些。





 研究人员研究小鼠视觉皮层中1万多个神经元的自发活动,其中大量信息是“噪声”,与视觉活动无关。图中闪光代表神经元发送信号。
研究人员研究小鼠视觉皮层中1万多个神经元的自发活动,其中大量信息是“噪声”,与视觉活动无关。图中闪光代表神经元发送信号。
 激活扩散模型示意图
激活扩散模型示意图
 智源研究院认知神经基础方向的研究框架
智源研究院认知神经基础方向的研究框架