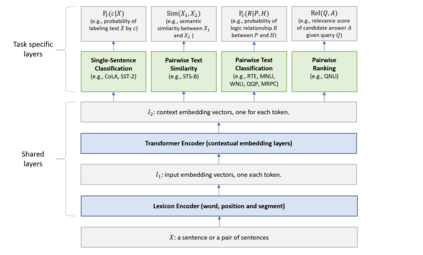
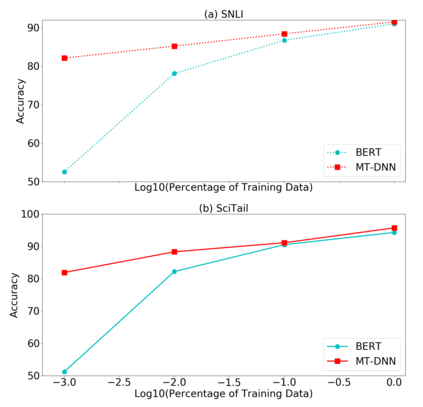
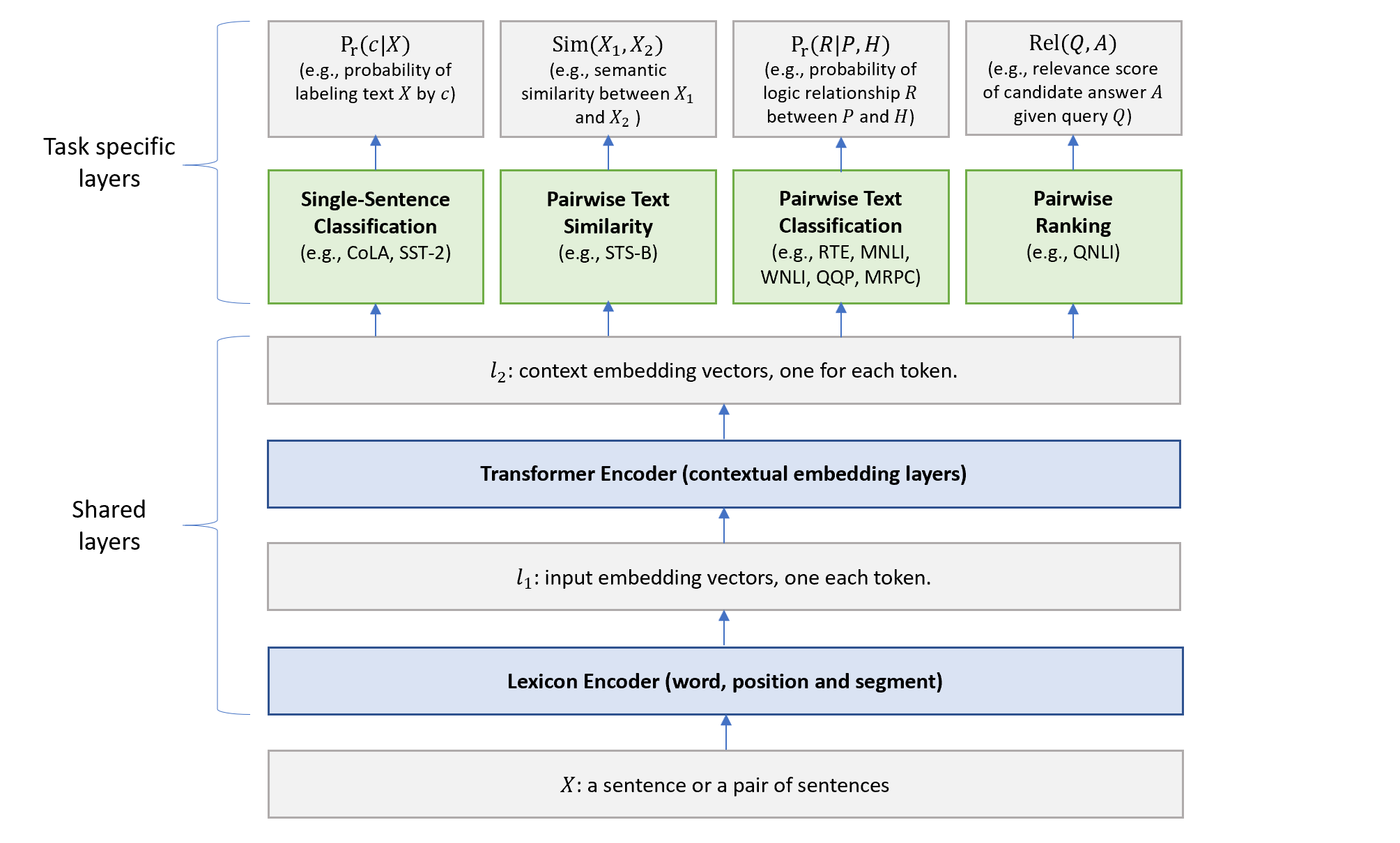
In this paper, we present a Multi-Task Deep Neural Network (MT-DNN) for learning representations across multiple natural language understanding (NLU) tasks. MT-DNN not only leverages large amounts of cross-task data, but also benefits from a regularization effect that leads to more general representations in order to adapt to new tasks and domains. MT-DNN extends the model proposed in Liu et al. (2015) by incorporating a pre-trained bidirectional transformer language model, known as BERT (Devlin et al., 2018). MT-DNN obtains new state-of-the-art results on ten NLU tasks, including SNLI, SciTail, and eight out of nine GLUE tasks, pushing the GLUE benchmark to 82.2% (1.8% absolute improvement). We also demonstrate using the SNLI and SciTail datasets that the representations learned by MT-DNN allow domain adaptation with substantially fewer in-domain labels than the pre-trained BERT representations. Our code and pre-trained models will be made publicly available.
翻译:在本文中,我们提出了一个多任务深心神经网络(MT-DNN),用于在多种自然语言理解(NLU)任务中进行学习。MT-DNN不仅利用大量跨任务数据,而且还受益于正规化效应,这种效应导致更普遍的代表性,以便适应新的任务和领域。MT-DNN通过纳入事先培训的双向变压器语言模式,即BERT(Devlin等人,2018年),扩展了刘等人(Li等人)(2015年)中提议的模式。MT-DNNN在NLU的10项任务中获得了新的最新结果,包括SNLI、SciTail和GLUE九项任务中的八项任务,将GLUE基准推至82.2%(1.8%的绝对改进率 )。我们还表明,使用SNLI和SciTail数据集,M-DNN所学的表示允许域内调用比事先培训的BERT说明少得多的标签。我们的代码和预先培训模型将公开提供。