TF1 到 TF2, 你的在线推理很可能内存爆炸

1. 从 TF1 到 TF2, 线上内存爆炸了
最近我们团队使用的框架从 TF1 升级到了 TF 2。升级之后,线上的 Tensorflow Serving 发生了爆内存的现象。具体现象如下图所示:16G 的内存不到半个小时全部耗尽,内存耗尽之后服务挂掉,然后服务管理平台重新拉起服务;不到半个小时,16G 内存又耗尽,服务挂掉又拉起;这个过程反复进行。TensorFlow Serving 进程因 Out-of-Memory 多次重启。
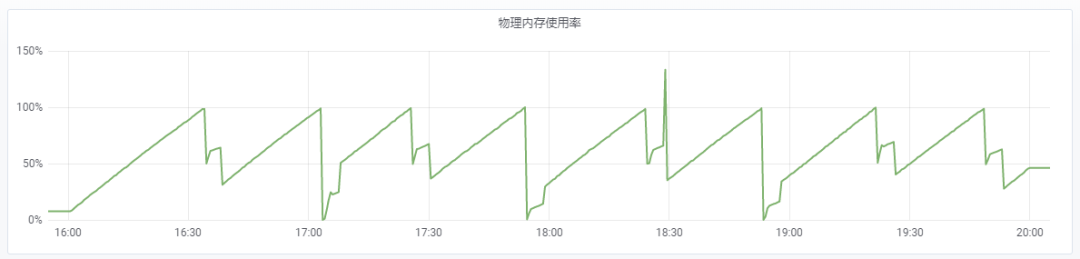
之前,团队使用 TF1 tf.feature_column + tf.estimator 的组合编写训练代码,并基于 TensorFlow Serving 搭建模型推理服务。团队采用这一技术方案,有效地满足了诸如企鹅电竞、王者营地、掌上英雄联盟等业务的需求。
近日,团队将 Tensorflow 升级到 2 版本。考虑到在 TF2 版本中官方更推荐使用 tf.keras API。于是编写训练代码时,也将 tf.estimator 替换成了 tf.keras。训练完成后,导出 SavedModel 格式的模型文件,使用 TensorFlow Serving 部署上线。
2. 空间换时间的遗祸
对于 TensorFlow Serving 进程内存占用暴涨这一问题,我们从排查 TensorFlow 内存泄漏的角度做了些许尝试,但都无果而终。幸运的是,我在 GitHub 上查阅相关的 issues 时,无意间发现了一个最近的 Pull requests [3]。里面提到,如果模型有 n 个输入,那么,有可能产生 n! 种可能的 key,从而导致占用大量内存。
带着这个问题,我阅读了 direct_session.cc 中的 [GetOrCreateExecutors] 函数[1]和 predict_util.cc 中的 [PreProcessPrediction] 函数[2]。
原来,Session 在初次执行时,会对模型输入、输出的 key_name 做排序并拼接,得到 sorted_key,然后创建相应的 Executor,并将 <sorted_key: executor> 这一映射保存到 <key: executor> 字典中。后续 Session 在执行时,会先判断是否已经存在与模型输入、输出对应的 Executor,若存在,则重复使用这个 Executor;若不存在,则创建一个新的 Executor。
但是,TensorFlow Serving 是通过遍历一个 Map 来从 PredictRequest 中抽取模型输入、输出的 key_name,因此,每次遍历的顺序都不尽相同。理论上,假如模型有 n 个输入,那么有 n! 种可能的遍历结果。
而 TensorFlow 恰巧在查找 Executor 上做了以空间换时间的“优化”。它并不会每次都对输入、输出的 key_name 做排序、拼接,而是先直接拼接,得到 unsorted_key,并查找 <key: executor> 这个字典,若未找到,再对输入、输出做排序、拼接, 然后查找。同时,将 <unsorted_key: executor> 这一映射保存到 <key: executor> 字典中,以提高后续查找 Executor 时的“命中率”,避免排序。
那么为什么在 TF1 的时候,没有这个问题呢?因为不同于 TF1 的 tf.feature_column + tf.estimator 的组合,使用 TF2 的 tf.feature_column + tf.keras 的组合导出的模型有多个输入。下面的截图分别展示了两种组合的(部分)输入。
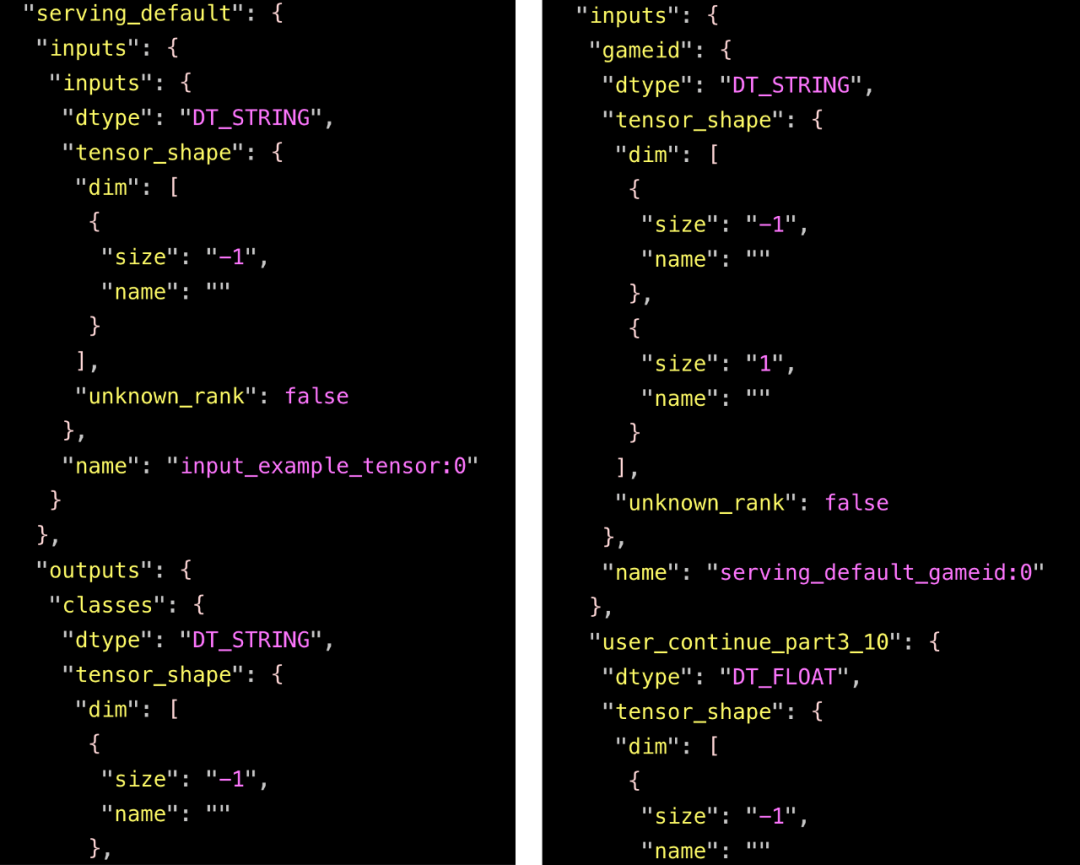
左边对应 TF1 的 tf.feature_column + tf.estimator,模型仅有一个输入(protobuf序列化后的tf.Example);右边对应 TF2 的 tf.feature_column + tf.keras,模型有多个输入(每个输入对应一个特征)。考虑到我们模型的输入特征数量接近 400 ,400! 是一个天文数字,足以塞爆内存。
基于上面调查的结果,我按照上述 [Pull requests][3] 修改 [PreProcessPrediction] 函数[2]的源码,每次获得输入、输出的 key_name 后都对其进行排序。重新编译 tensorflow_model_server 程序,再次对服务做压力测试,下面的截图给出了压测过程中内存使用率的变化曲线。
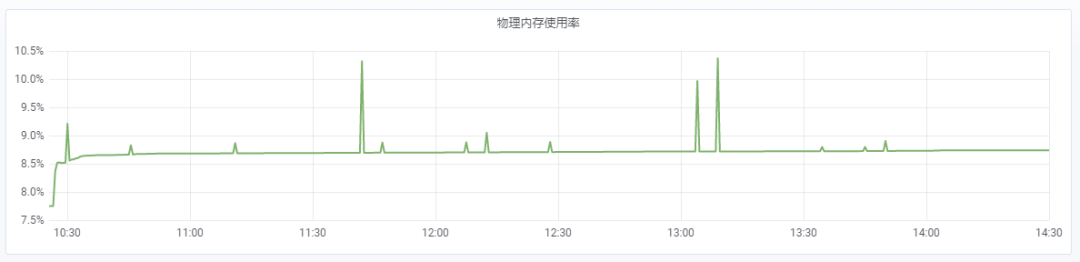
可以看到,除了压测刚开始的一段时间,其余时间 TensorFlow Serving 内存占用保持平稳。
3. 不够恰当的优化
空间换时间是很好的优化方法。但 TF 用空间换时间来优化输入(特征) 的排序,却很无厘头。如果输入(特征)少,比如只有 10,省掉排序能省下多少时间呢?如果输入(特征)稍微多一点,比如20,50 和 100,省掉排序能省下的时间多了一点,但 20!= 2432902008176640000,50!和 100 ! 都是天文数字,很容易塞爆内存。
空间换时间本身是一个很好的方法,但使用的时候需要特别注意,会不会使用很多内存从而爆内存。如果使用很多的内存,则需要采取一定的限制措施。比如在 TF 输入(特征) 的排序场景。如果能用一个容量上限的 map,并且超过这个 map 容量上限就将最近最少使用的 key 淘汰 ,那么既不会爆内存,时间也能得到优化。
4. 结论
首先膜拜下 Pull requests [3] 的作者。对 TF 足够深入的理解,才能有这种发现。
应该不少团队准备或者正在将 TF1 升级到 TF2,而使用的模型有多个输入(特征),就很有可能碰到内存爆涨的问题。毕竟一个模型超过 20 个输入(特征)是非常正常的事情,20! = 2432902008176640000 已经是一个足以塞爆内存的天文数字。
不要等 TF 官方合并Pull requests [3] ,我们自己把这个 Pull requests [3] 的改动引入之后重新编译 TF Serving,就能解决问题。或者自己实现一个 “用一个固定容量的 map,并且超过这个 map 容量就将最近最少使用的 key 淘汰 ”,然后给 TF 再提一个 PR。
5. 链接
[1] https://github.com/tensorflow/tensorflow/blob/463c3055ecd3bba92d7e1da3ebe48e7e8394a0c1/tensorflow/core/common_runtime/direct_session.cc#L1455
[2]
https://github.com/tensorflow/serving/blob/99dfd14c11cfd500ff3beda0c8f1b99094e9d88d/tensorflow_serving/servables/tensorflow/predict_util.cc#L89
[3]
https://github.com/tensorflow/serving/pull/1638
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





