Gaussian YOLOv3:一个更强的YOLOv3,现已开源!
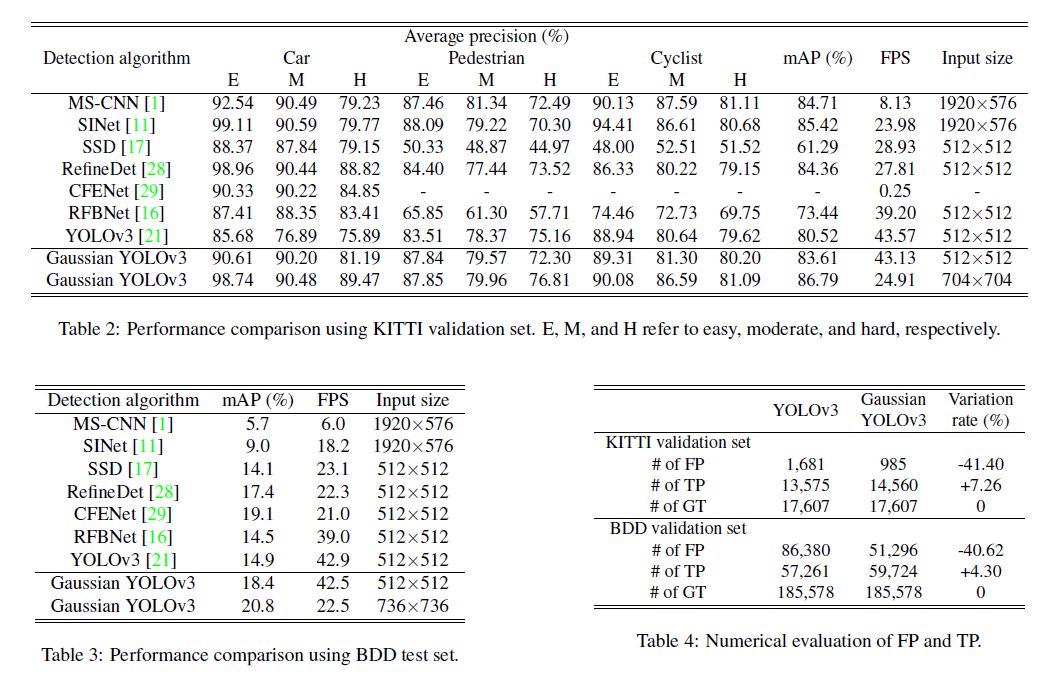
在目标检测的落地项目中,实时性和精确性的trade-off至关重要,而YOLOv3是目前为止在这方面做得最好的算法。本文通过高斯分布的特性,改进YOLOv3使得网络能够输出每个检测框的不确定性,从而提升了网络的精度。
https://arxiv.org/abs/1904.04620
https://github.com/jwchoi384/Gaussian_YOLOv3
YOLOv3
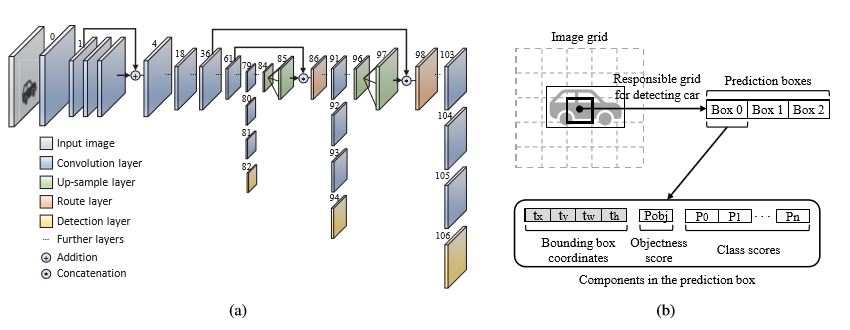
YOLOv3使用了skip shotcut的操作方式网络过深而引起的梯度消散。
YOLOv3使用了up-sample操作,并将大特征图和小特征图upsample后的特征图进行concat,使网络能够拥有既包含丰富的高层抽象特征和精确的位置信息特征的融合特征层。
YOLOv3使用了特征金字塔结构,使得网络能够在三个不同的尺度特征下做目标检测,能够适应与多种不同大小的目标检测任务。
如上图(b)所示,为利用YOLOv3进行目标检测时的网络输出。
-
RGB3通道图像作为YOLOv3网络的输入,检测结果会在三个不同的尺度分别输出,包含了目标的坐标位置,目标是正样本还是负样本的概率,目标属于某个类别的置信度。对于每个尺度分支而言,在每个grid cell中会预测出三个结果(每个尺度下会有三个anchor)。将三个尺度的结果合并,进行非极大值抑制(NMS)后,输出最终的检测结果。
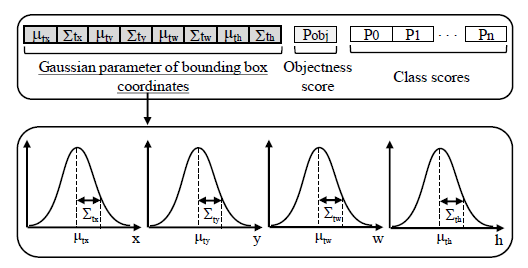
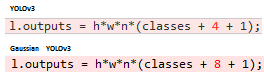
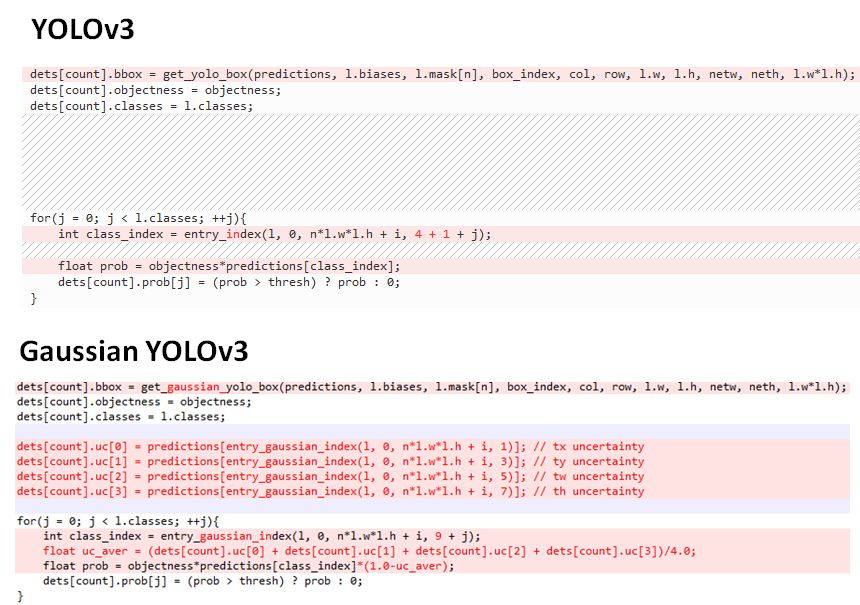
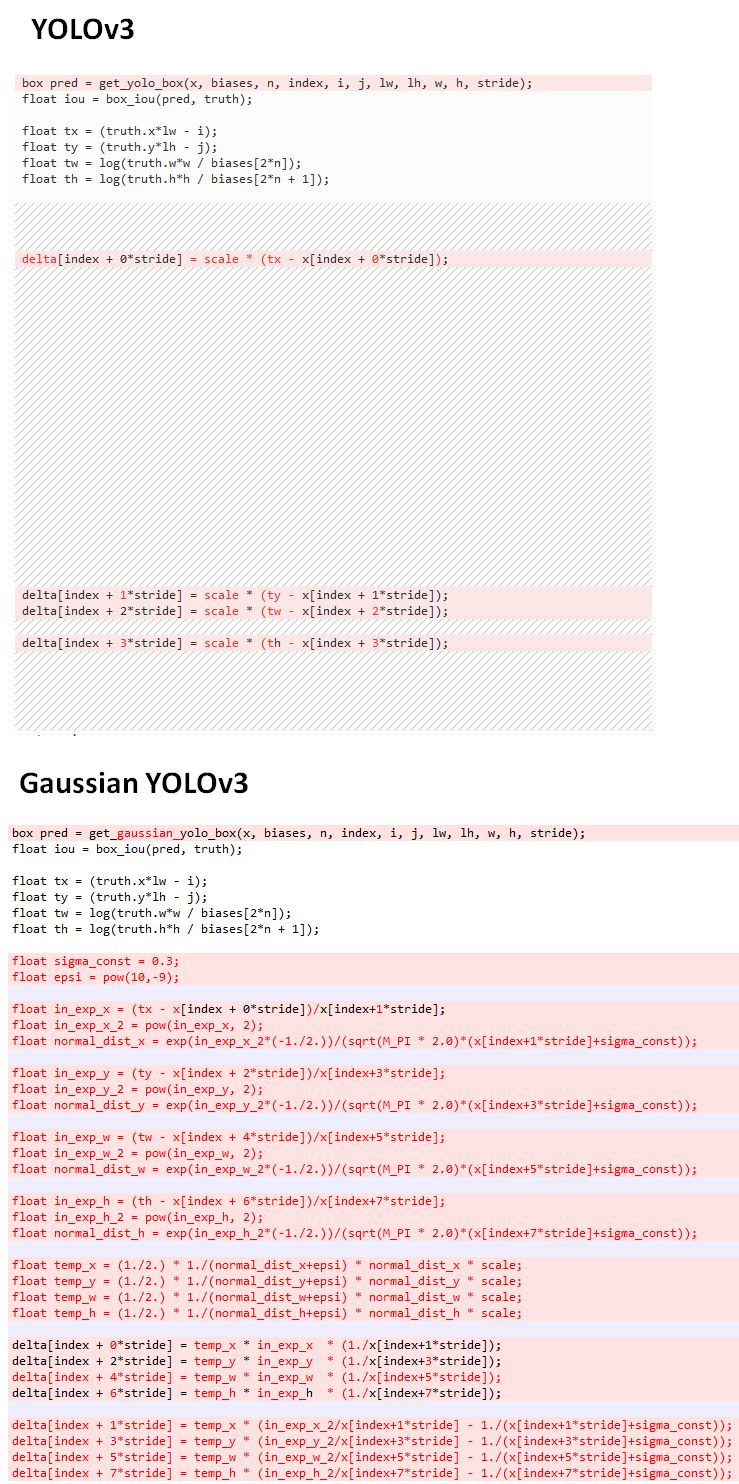
Gaussian YOLOv3的损失函数如下:
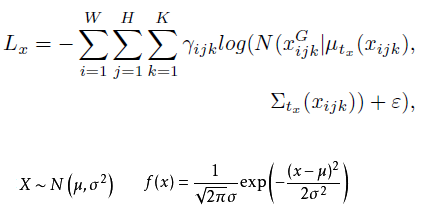
重磅!CVer-目标检测交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪&去雾&去雨等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!
登录查看更多
相关内容

Arxiv
3+阅读 · 2019年3月20日




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年3月20日