【泡泡点云时空】3DMV:联合三维多视图预测的三维语义场景分割(ECCV2018-7)
泡泡点云时空,带你精读点云领域顶级会议文章
标题:3DMV: Joint 3D-Multi-View Prediction for 3D
Semantic Scene Segmentation
作者:Angela Dai, Matthias Nieβner
来源:ECCV 2018
播音员:卜德飞
编译:赵传
审核:郑森华
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

我们提出了一种利用三维多视点联合预测网络进行室内RGB-D扫描的三维语义场景分割的新方法—3DMV。与现有的使用几何或RGB数据作为此任务输入的方法相比,我们将这两种数据模式组合在端到端的联合网络架构中。我们不是简单地将颜色数据投影到体网格中并且只以三维的方式操作{这将导致细节不足},而是首先从相关的RGB图像中提取特征映射。然后使用可微后向投影层将这些特征映射到3D网络的体素特征网格中。由于我们的目标是可能具有许多帧的3D扫描场景,因此我们使用多视图池化方法来处理数量不同的RGB输入视图。通过我们的联合2D-3D网络架构学习到的RGB和几何特征得到的结果显著优于现有基准。例如,我们将ScanNet 3D分割基准测试的最终结果精度从现有的体素架构的52.8%提高到了75%。
整体流程
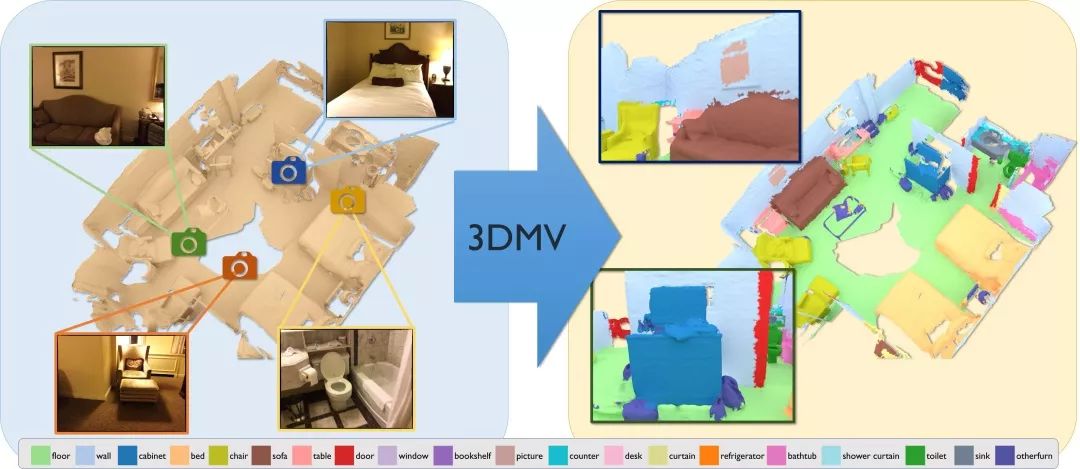
图1 3DMV(三维多视图)以RGB-D扫描及其彩色图像(左)的重建作为输入,并以每个体素标签(映射到网格,右)的形式预测3D语义分割。我们的方法的核心是利用几何特征和颜色特征之间的协同作用的联合3D-多视图预测网络。
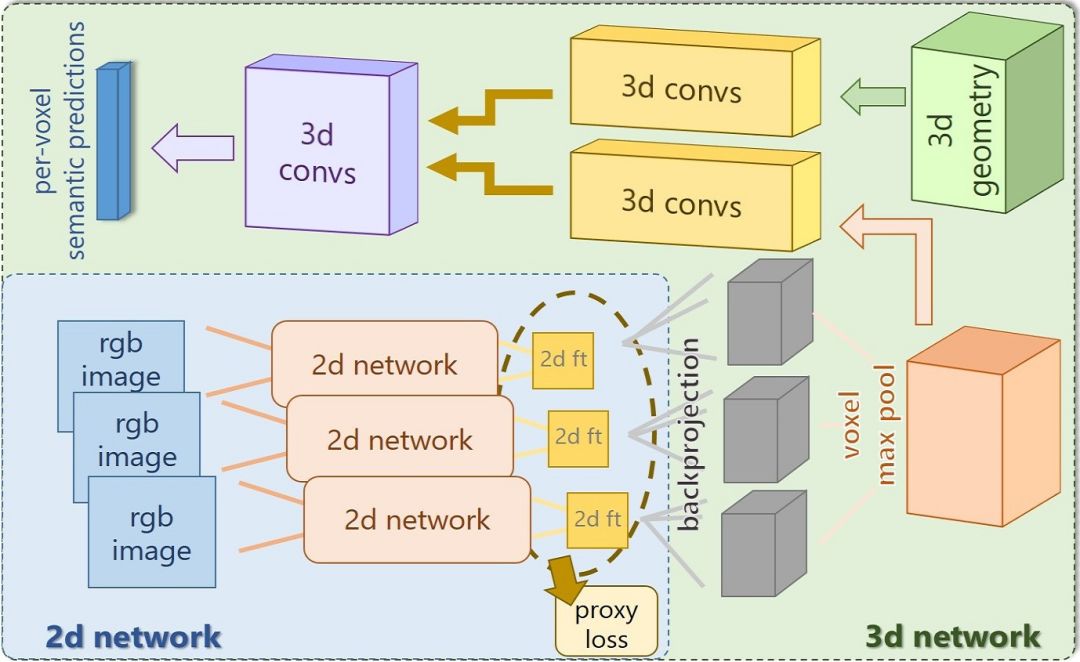
图2 网络概述:我们的架构由2D和3D两部分组成。2D侧将多个对齐的RGB图像作为输入,从这些特征中学习具有代理丢失的特征。这些使用可微反投影层映射到3D空间。将每个体素中从多个视图提取的特征通过最大池化进行汇集,并馈送到3D卷积流中。同时,我们将3D几何输入到另一个3D卷积流中。然后,连接两个3D流,并且预测每个三维体素的标签。整个网络以端到端的方式进行训练。
实验结果

图3 在ScanNet测试集上的定性语义分割结果。我们对比了基于3D的ScanNet、ScanComplete、PointNet+++的方法。注意,参考标准场景中包含一些未标注区域,用黑色表示。我们的联合3D多视图方法实现更准确的语义预测。

表6 我们通过将预测的3D标签投影到相应的RGB-D帧来评估我们的方法在2D语义分割任务上的性能。这里,我们对在NYU2上的密集像素分类精度进行了比较。注意,表中ScanNet分类是11类分类任务的精度统计结果。
不足与未来的工作
虽然我们的联合3D-多视图方法在三维语义分割方面比先前的技术水平取得了显著的性能提升,但仍然存在几个重要的局限性。我们的方法在密集的体积网格上操作,这对于高分辨率RGB-D数据来说不切实际;例如,RGB-D扫描方法通常产生具有亚厘米体素分辨率的重构;稀疏方法,例如OctNet[17],可能是一个好的补救方法。另外,目前我们只联合预测场景中每一列的体素,而每一列是独立预测的,因此会由于选择不同的RGB视图而导致在最终的预测中可能会引起某些标签不一致;但是,注意,由于卷积特性,在3D网络中,几何保持空间相干。
对于未来,我们仍然在这个领域看到许多开放的问题。首先,三维语义分割问题还远未解决,三维中的语义实例分割仍处于起步阶段。第二,实现三维卷积神经网络的场景表示以及如何处理混合稀疏-密集数据表示存在许多基本问题。第三,我们也看到了在三维重建中结合多模态特征用于生成任务的巨大潜力,例如扫描补全和纹理化。

Abstract
We present 3DMV, a novel method for 3D semantic scene segmentation of RGB-D scans in indoor environments using a joint 3D multi-view prediction network. In contrast to existing methods that either use geometry or RGB data as input for this task, we combine both data modalities in a joint, end-to-end network architecture. Rather than simply projecting color data into a volumetric grid and operating solely in 3D-which would result in insufficient detail-we first extract feature maps from associated RGB images. These features are then mapped into the volumetric feature grid of a 3D network using a differentiable backprojection layer. Since our target is 3D scanning scenarios with possibly many frames, we use a multi-view pooling approach in order to handle a varying number of RGB input views. This learned combination of RGB and geometric features with our joint 2D-3D architecture achieves significantly better results than existing baselines. For instance, our final result on the ScanNet 3D segmentation benchmark increases from 52.8% to 75% accuracy compared to existing volumetric architectures.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



