【泡泡点云时空】PointNetVLAD:基于点云检索的场景识别(CVPR-13)
泡泡点云时空,带你精读点云领域顶级会议文章
标题:PointNetVLAD:Deep Point Cloud Based Retrieval for Large-Scale Place Recognition
作者:Mikaela Angelina Uy, Gim Hee Lee
来源:CVPR 2018
编译:孔令升
审核:吕佳俊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

与基于二维图像的派生表示(二维投影)不同,基于点云检索的场景识别仍然是一个尚未解决的问题。这主要是因为难以从点云中提取局部特征描述子,随后将这些特征描述子编码为检索任务的全局描述子。在本文中,我们提出了PointNetVLAD,利用最近成功的深度网络来解决基于点云检索的场景识别。具体而言,我们的PointNetVLAD是对现有PointNet和NetVLAD的组合/修改,它允许端到端的训练和引导,从给定的三维点云中提取全局描述子。此外,我们提出“懒惰三元组和四元组”损失函数,可以实现更具区分性和可扩展性的全局描述子来解决检索任务。我们创建基于点云的基准数据集,用于地点识别,并且这些数据集上的实验结果显示了我们的PointNetVLAD的可行性。代码和基准数据集下载链接可在下列链接中找到:
https://github.com/mikacuy/pointnetvlad
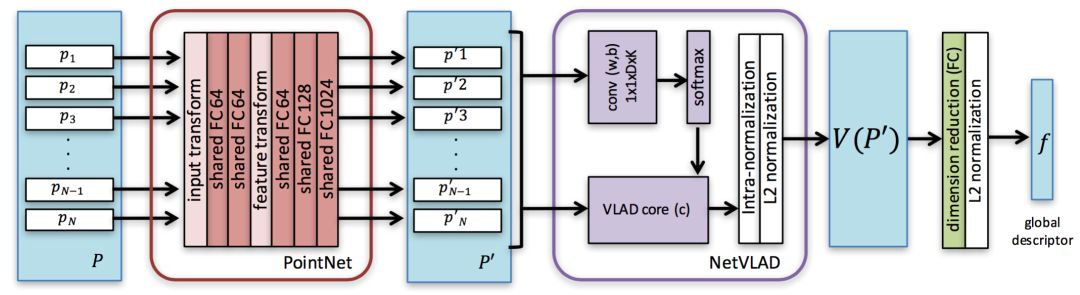
上图展示了PointNetVLAD的网络体系结构。它由三个主要组件(1)PointNet (2)NetVLAD 和(3)全连接网络组成。
详细分析:第一部分采用PointNet,在在最大池化聚合层之前裁剪。网络的输入与PointNet相同,PointNet是由一组3D点P={p1,p2...pN} 组成的点云。在这里,将P表示为应用了滤波器之后的固定大小的点云;为了简洁起见,我们在P上删除了条形符号。PointNet的作用是将输入点云中的每个点映射到更高维空间,即P到P',其中。在这里,PointNet可以被看作是从每个输入3D点提取D维局部特征描述子的组件。
将Point Net的输出局部特征描述子作为输入提供给NetVLAD层。NetVLAD层最初设计用于将从VGG / AlexNet学习到的本地图像特征聚合到VLAD词袋全局描述子向量中。通过将点云的局部特征描述子提供给图层,创建了一个机制,为输入点云生成全局描述子矢量。NetVLAD层学习K个聚类中心,并输出(D,K)维向量V(P')。输出向量是局部特征向量的聚合表示。
NetVLAD层的输出是输入点云的VLAD描述子。然而,VLAD描述符是高维矢量,即(D,K)维矢量,其使得其对于最近邻搜索而言在计算上多余。为了缓解这个问题,使用一个完全连接的层将向量压缩成一个紧凑的输出特征向量,然后将其L2正则化以产生最终的全局描述子向量,其中点云P可进行有效的检索。
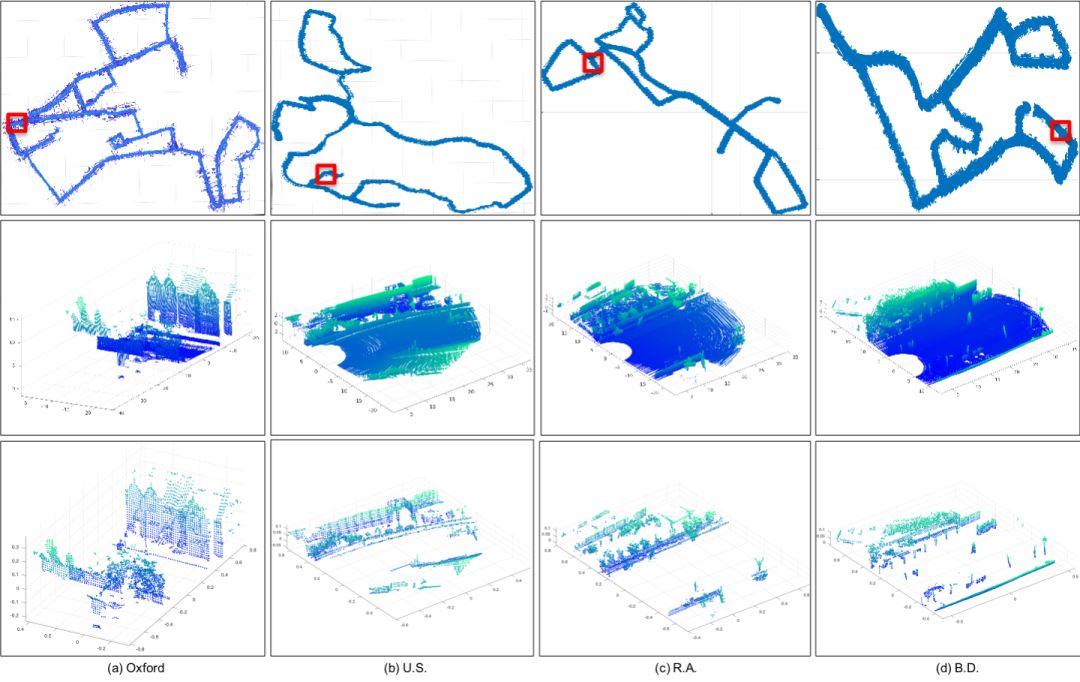
上图顶行显示了来自(a) Oxford, (b) U.S., (c) R.A and (d) B.D.的样本参考图。中间行显示来自每个区域的示例子图,表示参考图上红色框标记的局部区域。底行显示了中间行本地区域的相应预处理子图。作者在NVIDIA GeForce GTX 1080Ti上利用TensorFlow上实验使用大约9毫秒,通过子图数据库检索时间复杂度为O(log n),这适用于实时机器人系统。

Abstract
Unlike its image based counterpart, point cloud based retrieval for place recognition has remained as an unexplored and unsolved problem. This is largely due to the diffculty in extracting local feature descriptors from a point cloud that can subsequently be encoded into a global descriptor for the retrieval task. In this paper, we propose the PointNetVLAD where we leverage on the recent success of deep networks to solve point cloud based retrieval for place recognition. Specically, our PointNetVLAD is a combination/modication of the existing PointNet and NetVLAD,which allows end-to-end training and inference to extract the global descriptor from a given 3D point cloud. Furthermore, we propose the “lazy triplet and quadruplet” loss functions that can achieve more discriminative and generalizable global descriptors to tackle the retrieval task. We create benchmark datasets for point cloud based retrieval for place recognition, and the experimental results on these datasets show the feasibility of our PointNetVLAD. Our code and datasets are publicly available on the project website1.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



