KDD21 | 如何纠正推荐系统中的流行度偏差

题目:Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in Recommender System
发表地:KDD 2021
论文解读人:中国科大 魏天心
一、摘要
推荐系统的总体目标是为用户提供个性化的建议,而不是推荐热门物品,然而正常的训练范式,即拟合一个推荐模型来重建观测到的用户行为数据,会使得训练模型偏向于推荐流行商品,从而导致马太效应,即流行的物品被更频繁地推荐,并变得更加流行。
该论文从一个全新的视角——因果关系的角度来探讨推荐系统中的流行度偏差问题。该文章指出,流行度偏差存在于因果图中物品节点对排名分数的直接影响之中,也就是说物品的内在属性是错误地赋予某些物品过高排名分数的原因。文章认为为了纠正这种偏差,有必要考虑一个反事实的问题,即如果推荐模型只输入物品相关信息,那么它的排名分数将是多少。为此,该论文用因果图来描述推荐过程中的重要因果关系,在模型训练过程中,论文采行多任务学习的方式,建模每一项因果关系对于推荐得分的贡献,并在模型测试过程中采用反事实推理的方法来消除流行度对于推荐的影响。
二、研究背景
个性化推荐改变了无数的在线应用程序,大量不同的推荐算法也都被设计和部署,这些算法的默认优化选择都是重建历史中的用户-物品交互,然而在真实数据中,物品的分布频率并不均匀,它受到曝光度机制、口碑效应、促销活动、物品质量等诸多因素的影响,从而造成在绝大多数情况下,物品的分布频率是长尾的,即少数的流行物品包含了大多数的交互。这使得模型发现频繁地推荐流行物品可以简单地拟合训练数据,从而向该方向更新参数并更倾向于推荐流行的物品,这种流行度偏差会阻碍推荐系统准确理解用户的偏好,减少推荐的多样性。
目前针对这个问题的去偏算法主要可以分成三类:(1)逆权重分数:估计物品流行度的倾向性权重,并对每条数据样本利用逆权重分数进行加权。(2)加入无偏数据:通过从额外的无偏数据中学习来纠正流行度偏差。(3)分解嵌入表示:将兴趣和流行度分解为两套嵌入模型,并调整使得模型学习到更鲁棒的模式。
这些方法能起到一定的去偏效果,但也有一定的局限性,这些方法缺乏对物品流行度如何影响每个特定交互的细粒度考虑,也缺乏对流行度偏差机制的系统理解。文章认为,消除流行度偏差的关键是了解物品流行如何影响每次交互,而不是盲目地将增加长尾物品的权重。
三、方法介绍
方法介绍共分为三部分:因果图的建立、建模因果效应、消除流行度影响。
【因果图的建立】
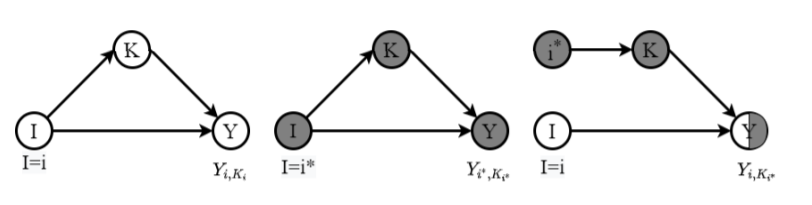
图1:因果图的例子
文章首先介绍了因果图和因果效应的概念,因果图是有向无环图,其中包含随机变量集合,和随机变量之间的因果关系。在因果图中,用大写字母表示变量,小写字母表示其观测值。因果图中的有向边意味着其祖先节点是一个原因,后继节点是一个结果。以图1为例,
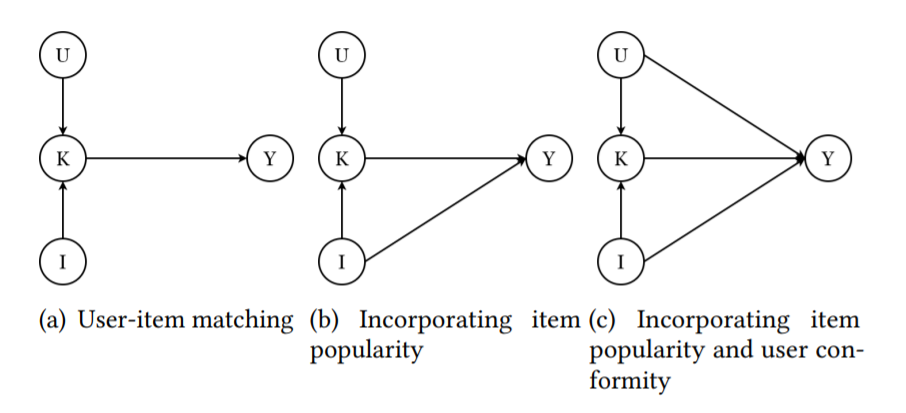
图2:推荐系统中的因果图
介绍完因果图的概念,接下来就可以为推荐系统来构建因果图,它代表着历史交互数据的生成过程,其中
【建模因果效应】
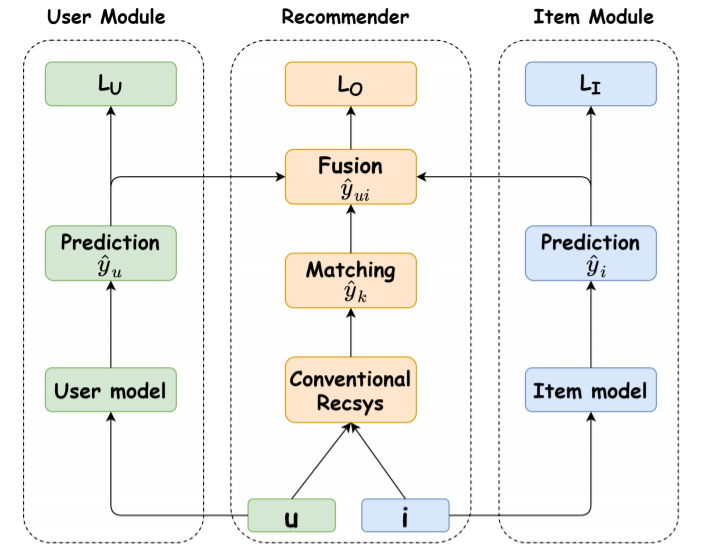
图3:MACR模型框架
大多数的推荐系统模型之所以受到流行偏见的影响,是因为这些模型建模了用户和物品之间的交互,而这些交互是从训练数据估计出的,从而会导致模型不可避免地偏向流行物品。从因果关系的角度来看,物品的流行程度直接影响推荐得分,因此消除了从物品流行程度到推荐得分的直接影响就可以消除流行度偏差,为此首先需要在训练时建模因果图中的因果效应。
文章设计了一种消除推荐系统中流行度偏差的反事实推理方法框架(
首先是用户-物品匹配模块:这代表着传统推荐系统,
物品建模模块:
用户建模模块:
模型训练目标是拟合真实历史交互
在模型训练过程中,文章应用
其中
其中
【消除流行度影响】
消除流行偏见的关键是通过消除物品对于模型的直接影响,因此文章将训练时的预测分数(总因果效应
其中
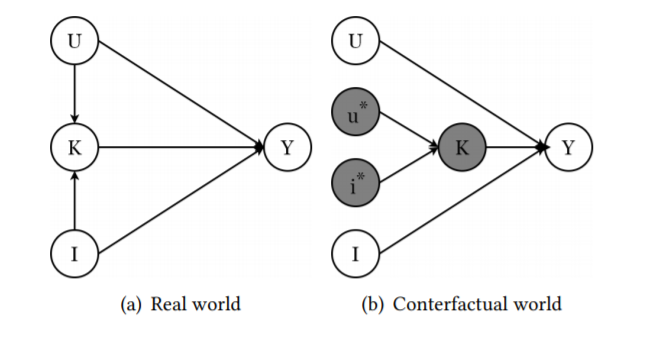
图4:反事实推理消除偏差
四、实验结果
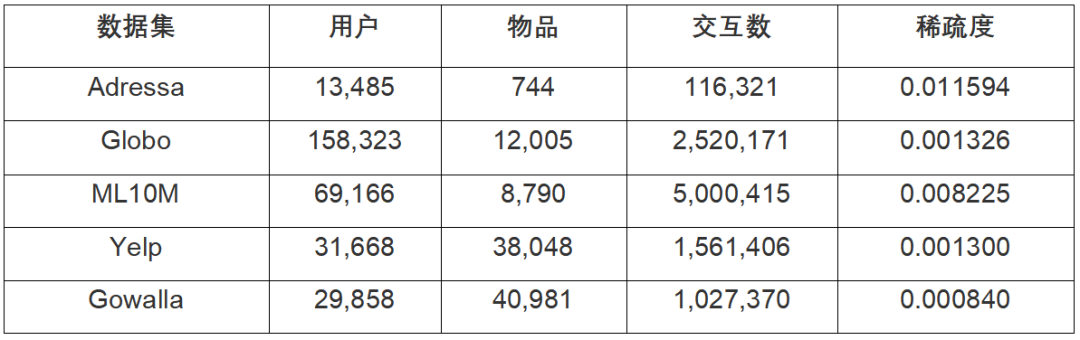
【整体效果】表1展示了五个公开数据集的数据统计情况,图1展示了这些数据集下因果去偏算法和当前最先进的算法的对比,可以看出在无偏的用户物品交互场景中,因果去偏算法的性能显著优于最先进的基线,在两个经典基准模型(
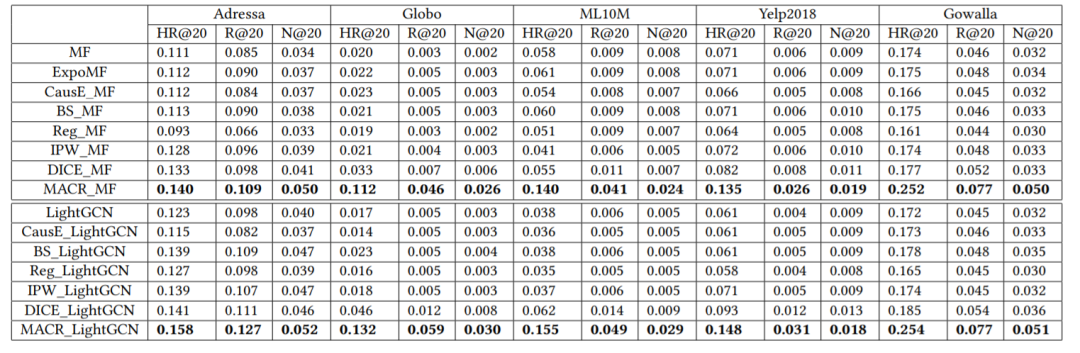
图5:整体推荐效果
【消融实验】图6使用在
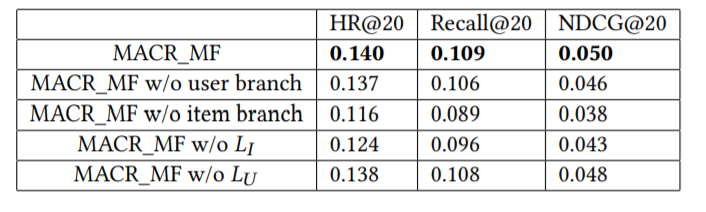
图6:消融实验
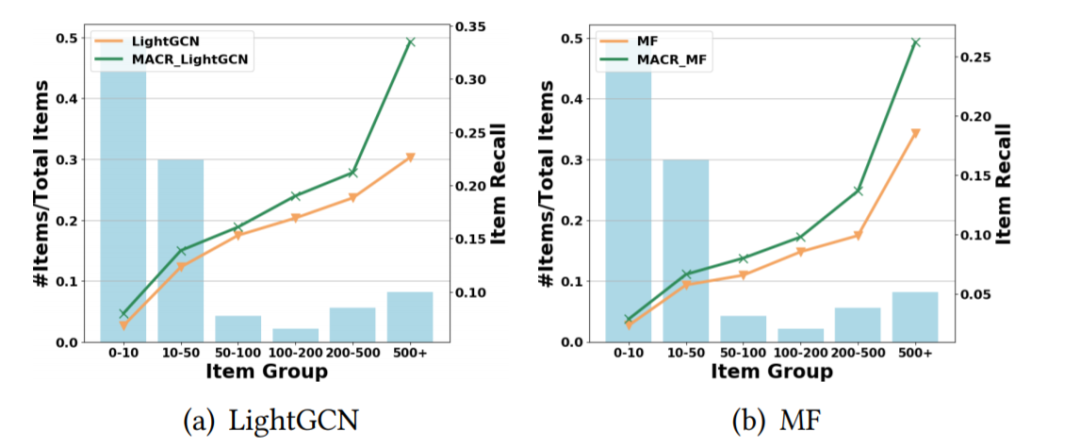
图7:不同物品分组上的推荐效果
【推荐结果分析】文章将物品根据在训练集中的流行度划分成不同的分组图,并计算这些物品在测试时的平均推荐准确度,从图7中可以发现对于不同分组,因果去偏的方法均取得较大提升,并且流行度越高,提升越大,说明了因果去偏的有效性。
五、实验结果
该文从因果推理的角度去消除推荐系统中的流行度偏差,设计出了模型无关的去偏框架
六、往期推荐
ACM TOIS | 社交关系感知的多模态视频人物检索
AAAI 2021 | 由时空轨迹预训练上下文与时间敏感的地点嵌入

国内数十位NLP大佬合作,综述预训练模型的过去、现在与未来


