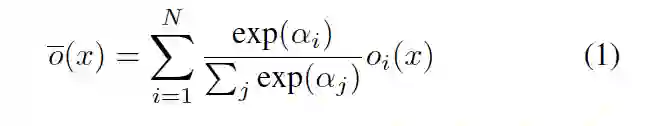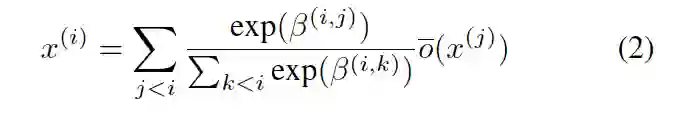本文介绍了由创新奇智公司联合密歇根州立大学合作开发的高效神经网络架构搜索算法 HM-NAS。该论文近日发表于 2019 国际计算机视觉大会(ICCV)Neural Architects Workshop,并获得最佳论文提名。通过使用多层级网络架构编码以及多层级掩码的方法,HM-NAS 解决了现今神经网络架构搜索算法中基于人工启发式生成候选网络结构的限制。实验结果表明: HM-NAS 在 CIFAR-10 和 ImageNet 数据集中都在保证准确率的同时提升了搜索效率并减少了模型参数。
![]()
论文地址:http://openaccess.thecvf.com/content_ICCVW_2019/papers/NeurArch/Yan_HM-NAS_Efficient_Neural_Architecture_Search_via_Hierarchical_Masking_ICCVW_2019_paper.pdf
作者提供 HM-NAS 方法,一个高效神经网络架构搜索方法,这个方法破除了现在存在的基于权值共享的搜索方法的限制。
作者提出了一个多层级的编码结构,这个结构能够使候选网络结构能够对任意数量的边和操作赋予不同的权重。同时提供一个分层屏蔽方案,这个方案不仅能通过学习的方式来学习到最优的边数量和操作的权重关系,而且帮助矫正搜索网络在训练中由于优化函数引起的偏差。
大量实验证明,与最先进的权值共享的 NAS 方法相比,HM-NAS 方法能够更好地搜索出模型的网络结构和更具有竞争力的准确率。
摘要
最近,神经网络架构搜索(NAS)在神经网络结构设计自动化方面的成效引起人们极大的关注。由于其搜索成本低的优点,基于权值共享的 NAS 方法备受青睐。然而,这些方法仍然采用人工启发式来生成候选网络结构,使网络搜索结果达到局部最优。在这篇论文里面,作者提出了一个有效的 NAS 方法: HM-NAS。HM-NAS 提出两个创新点来解决这个限制。第一点:HM-NAS 结合了多级结构编码方案,可以搜索更灵活的网络结构。第二点:抛弃了人工启发式搜索方法,结合一个可以自动学习并能决定最优的结构的层级编码方案, 同时用来矫正训练过程中的由优化函数导致的偏差。和目前先进的权重共享的方法相比,HM-NAS 能够获得更好的神经结构搜索表现和在准确率表现具有竞争性。没有人工启发式方法的禁锢,HM-NAS 的搜索方法能够发现更加灵活和有意义的结构。
介绍
神经网络架构搜索方法 (NAS),由于它具备自动设计神经网络的功能和它在许多重要的任务上优秀的表现,例如:图像分类,图像检测,图像的语义分割等,引起了极大的关注。
在早期的 NAS 方法中,候选结构是在搜索空间中采样得到的,每一个候选结构的权值是独立学习得到的,如果这个候选架构效果不好的话,会被舍弃。尽管这个方法取得了很大的成功,但是由于每一个候选结构都需要一个完全训练的过程,这些都是非常耗费计算资源的方法,需要耗费成百甚至上千个 GPU 训练一天来寻找高质量的结构。
为了克服这个瓶颈,基于权值共享的 NAS 方法应运而生。基于权值共享的 NAS 方法不再单独地训练每个候选结构。网络结构的搜索空间被编码在一个包含超级参数的大网络里面,这个大网络被称为父类网络,这个父类网络包含所有可能的连接和操作(例如:卷积,池化,恒等)。这个父类网络只被训练一次。所有候选的网络结构直接继承这个父类网络的权值,通过这样的操作,训练 NAS 的计算消耗资源被明显地减少了。
不幸的是,尽管父类网络包含了所有可能的候选网络,现在基于权值共享的 NAS 方法往往采用的是人工启发式方法。DARTS 就是一个很好的例子。
在 DARTS 的方法里,这个父类网络组织为堆叠的单元,每个单元包含多个与边连接的节点。但是,当从父类网络中提取候选结构时,每个候选都被 hard coded 过,使得每个节点具有两个相同权重的输入边,并将每个边与某一个操作相关联。因此,候选结构的空间被约束成所有可能空间的一部分,造成这个结构搜索方法只能产生局部最优解。
为了解决基于权值共享的 NAS 方法的限制,本文作者提出了一个名为 HM-NAS 的高效网络结构搜索方法。
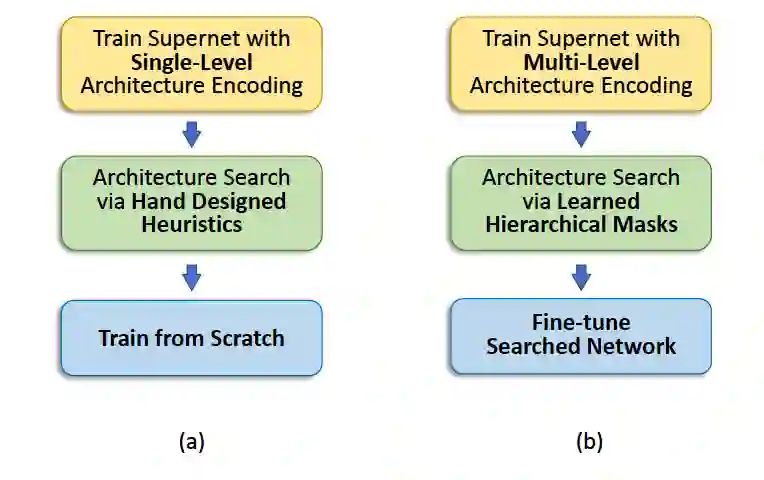
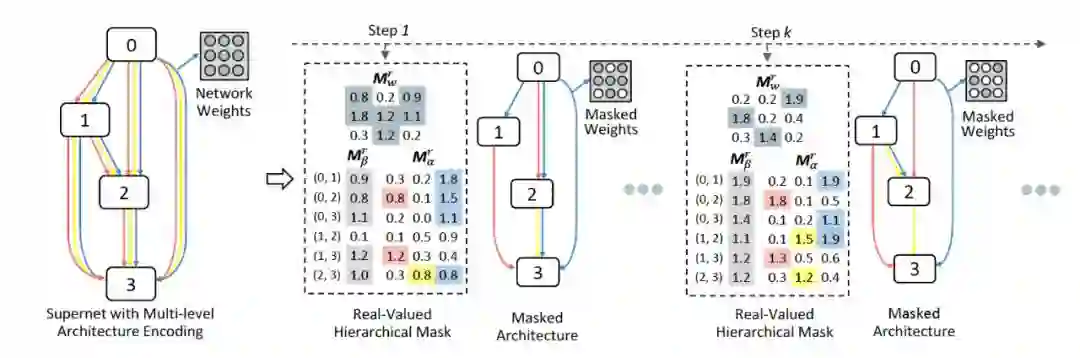
例如图 1 的指出的那样,为了解绑这个限制,HM-NAS 结合一个层级的结构来使候选结构从父类网络中抽取时,可以拥有任意数量的边和操作进行连接。而且,它允许每一个操作和边拥有不同的权值来反应它们的相对关系。根据这个多层的编码网络,HM-NAS 将神经结构搜索问题转化为模型修剪问题。它抛弃了人工启发式方法,采用分层屏蔽方案来自动学习边和操作的最佳数量及其相应的权重,并掩盖不重要的网络权重。而且,在这些基础之上增加了可以学习的层次掩码,多层次编码还提供了一种机制来帮助纠正父类网络的体系结构参数和网络权重训练产生的偏差。因为这些好处,HM-NAS 能够直接利用搜索出来的子网络继续训练而不是从零开始重新训练, 来减少搜索和验证过程的网络结构差异并加速网络的训练过程。
![]()
图 1 :
结构对比图。
(a)表示的是现在通用的权重共享的 NAS 搜索方法,例如 DARTS,(b) 表示的是 HM-NAS 方法。
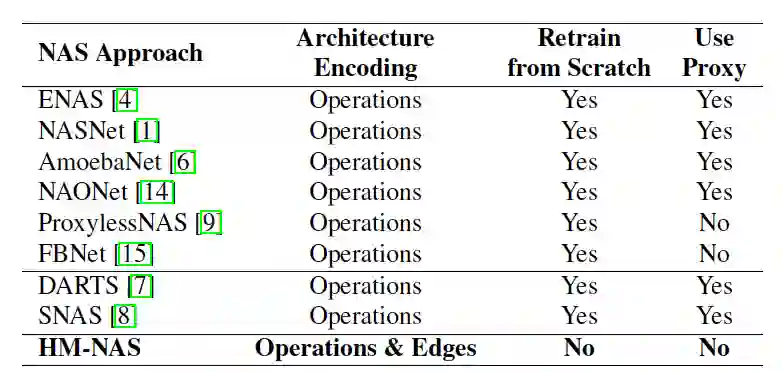
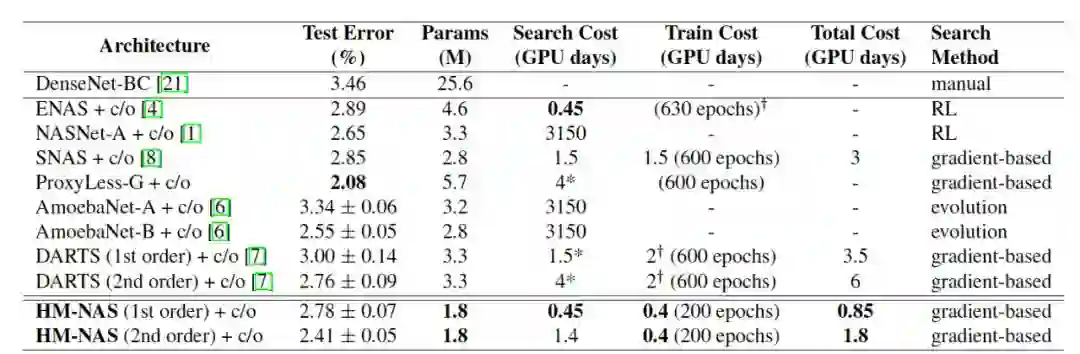
我们在知名的数据集 CIFAR-10 和 ImageNet 上来评价我们的 HM-NAS 方法。HM-NAS 方法在 CIFAR-10 数据集上面,能够使用少于 1.6 倍到 1.8 倍的参数量和少于总体 2.7 倍的训练量获得同样精度的模型。类似的结果同样在 ImageNet 数据集上表现一样。表格 1 展示了 HM-NAS 算法和其他 NAS 算法关于重要尺寸的对比。
![]()
表格 1:HM-NAS 算法和其他 NAS 算法重要尺寸对比
父类网络是由许多从上到下堆叠起来的单元组成,每个单元都使用一个有向无环图 (DAG),在这个 DAG 中的 x 节点是一个潜在的代表 (比如代表网络的特征图等)。每个单元拥有两个输入节点,一个或者多个中间节点,一个输出节点。这个单元的两个输入节点是上两个单元的输出节点,这个单元的输出节点是下个单元的输入节点。
为了尽可能地包含所有可能的结构在搜索空间中,作者在 DAG 中使用了可以学习的候选操作的变量组合,这个变量组合能够表明候选操作的重要性。
![]()
上述的公式定义了一个边上的多个节点操作的重要性。但是如果想要整个有向无环图 DAG 中不同边的权重,在 HM-NAS 的父类网络中,作者采用了分离的可以学习的变量来分别代表 DAG 中每个边的权重。这样就能够打破原来 NAS 算法的限制,在更广泛的空间中搜索架构。
![]()
通过上述的算法设计,作者将网络架构搜索问题转化为模型剪枝问题,图 2 详细地说明了层次掩码对一个单元的操作。
![]()
![]()
作者在 CIFAR-10 和 ImageNet 数据集上对 HM-NAS 算法和先进的 NAS 算法做对比实验,验证 HM-NAS 算法的具备竞争力的表现。
![]()
图 3:
HM-NAS 算法在 CIFAR-10 上的表现
从图 3 中可以看出来 HM-NAS 在所有的 NAS 算法中,在类似测试精度的情况下,参数只使用 1.8M 参数,比其他的 NAS 算法少 1.4-3.2 倍的参数。
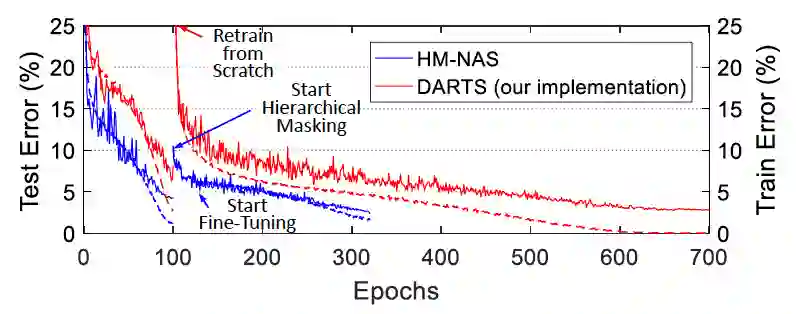
图 4 表示的是训练 HM-NAS 算法和其他 NAS 算法的训练难易程度的对比
![]()
从图中可以看出来 HM-NAS 算法找到最优的架构,从搜索过程到验证过程一共使用 0.85 到 1.8 个 GPU 一天的训练量,同时算法的收敛速度最快。
![]()
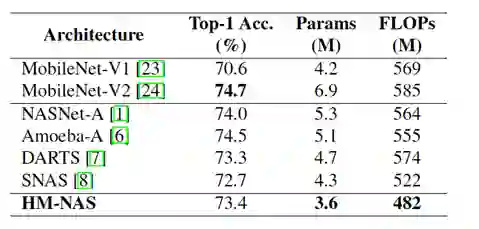
图 5:
HM-NAS 算法在 ImageNet 数据集上的表现
从图 5 可以看出来在同等的算法准确率下,HM-NAS 算法生成的模型参数更少。
不同的边可以学习不同的权重
可学习边权重的鲁棒性
更加灵活的架构
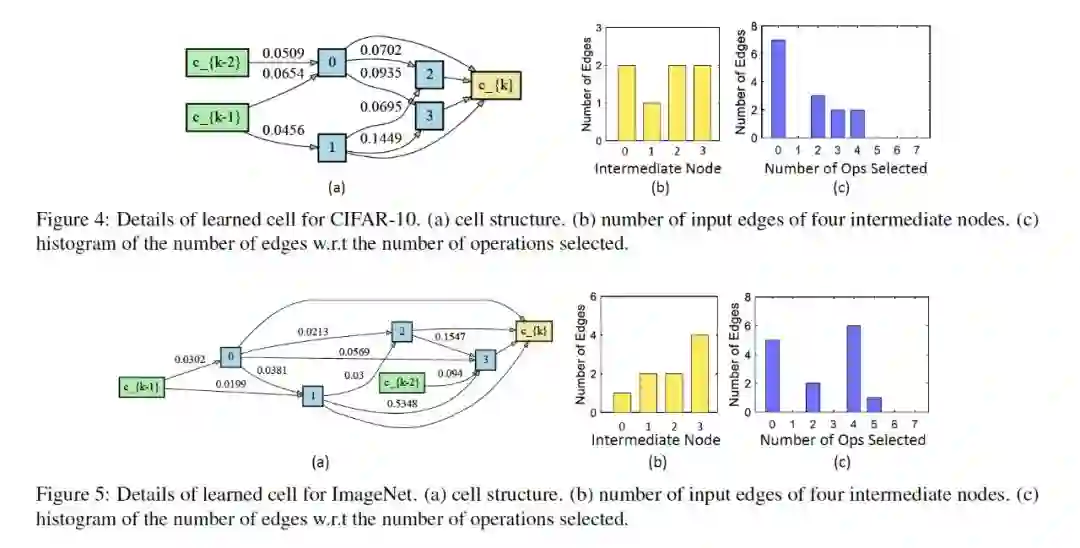
图 6 表现出根据 HM-NAS 算法生成的模型,(a) 表现出不同的边可以学习到不同的权重,(b)(c)可以看出来模型可以有更加灵活的架构。
![]()
![]()
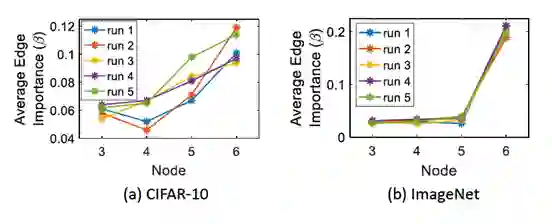
图 7 中表示不同的边有不同权重,不会随着不同的初始值的改变而改变,从侧面表现出可学习边权重的鲁棒性。
本文作者提出一种高效的 NAS 算法名字为 HM-NAS。HM-NAS 算法融合了一个多层级的架构保证候选架构拥有任意数量的边和操作,同时这些边和操作拥有对应的权重。同时提出了一个可以学习得到的层级掩码不仅能够选出最优的边数量,同样能够矫正训练过程中的由优化函数引起的偏差。在 CIFAR-10 和 ImageNet 数据集中都在保证准确率的同时提升了搜索效率。