深入浅出线性判别分析(LDA),从理论到代码实现


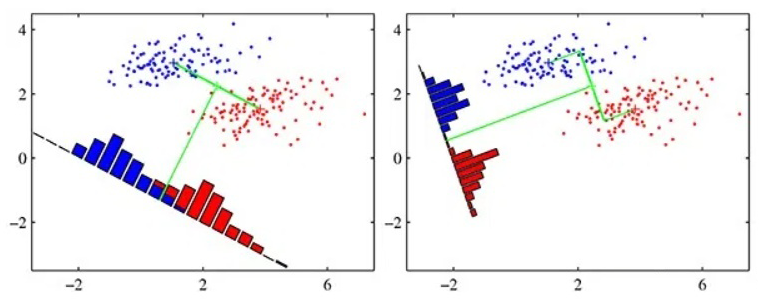
基本概念和目标

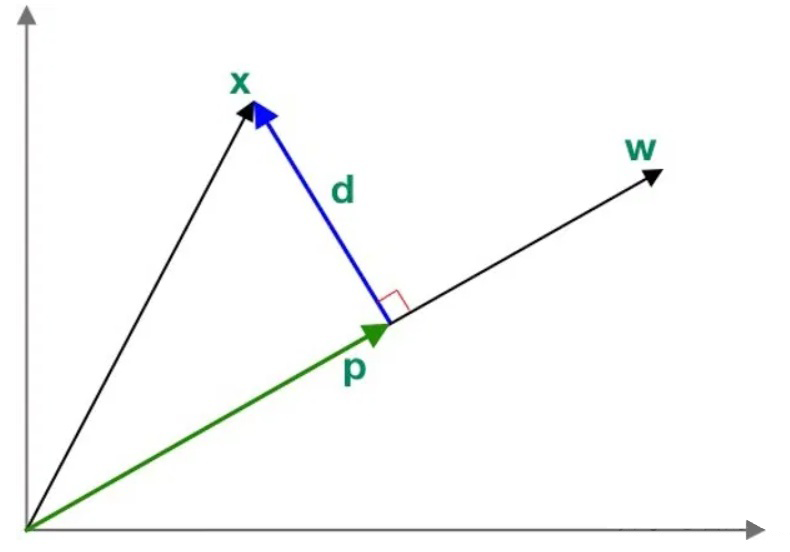
正交投影
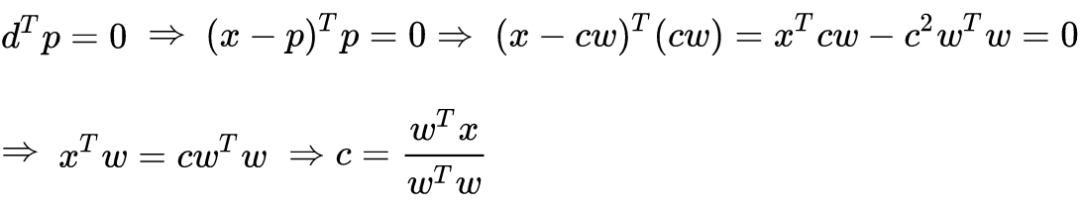
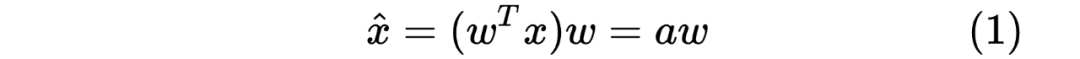
 是一个常数。
是一个常数。
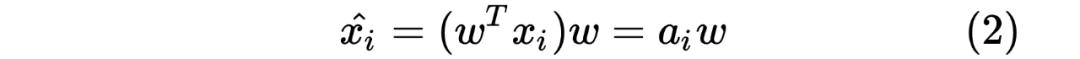

投影数据的均值
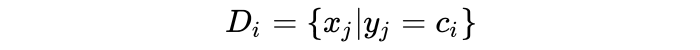
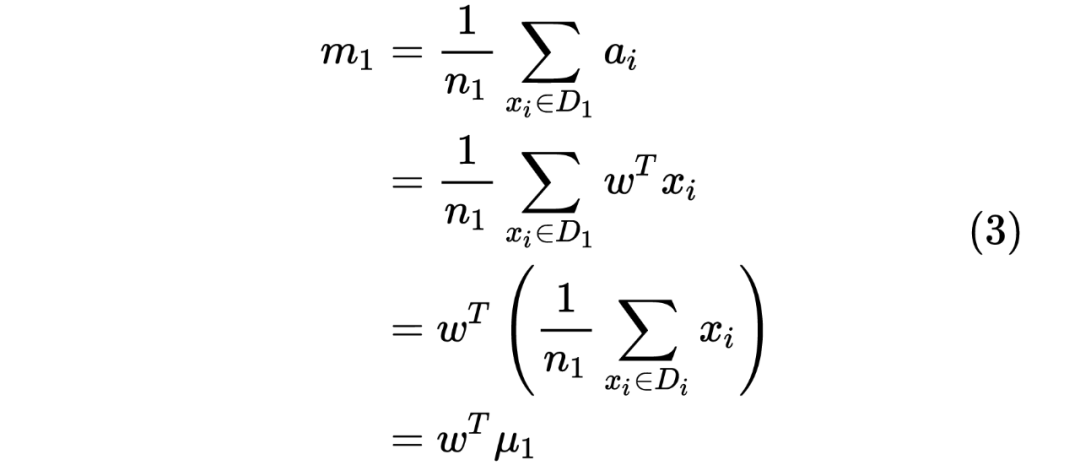
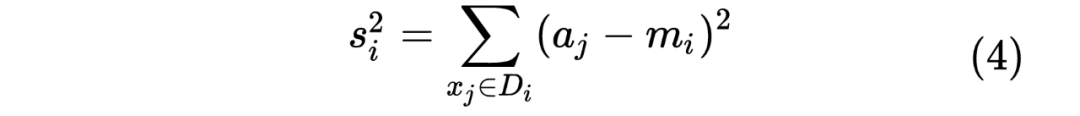
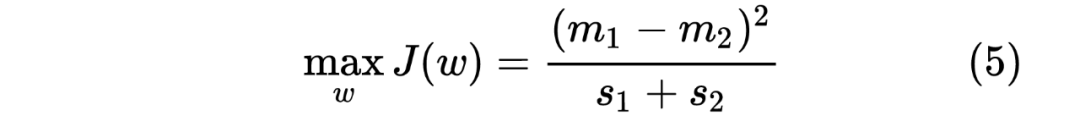
 最优化上述的公式。我们重写上述公式如下:
最优化上述的公式。我们重写上述公式如下:
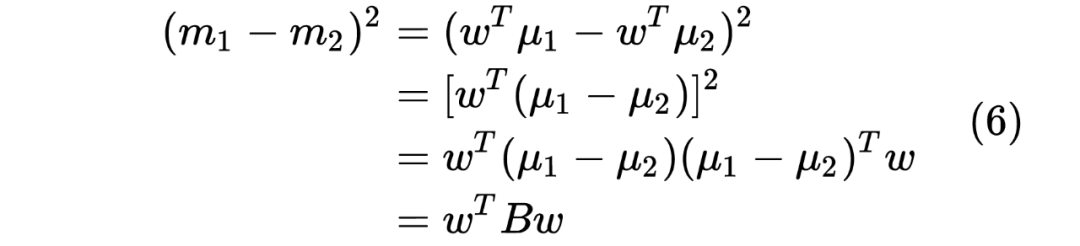
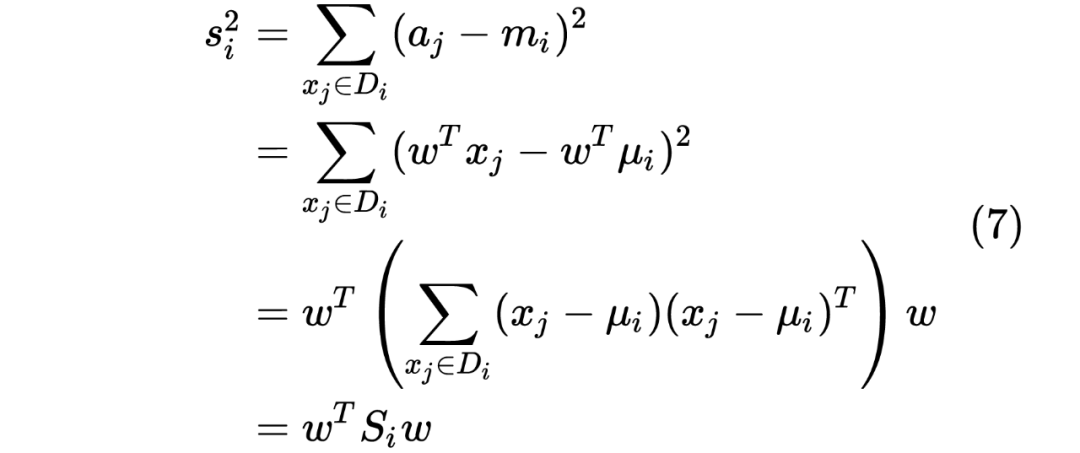
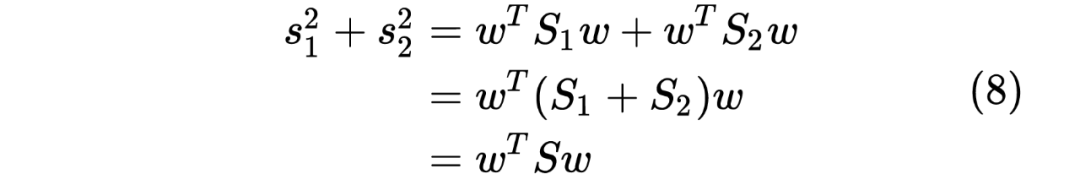
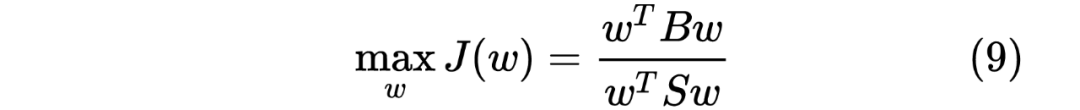 求导,并令其导数为 0,可得:
求导,并令其导数为 0,可得:
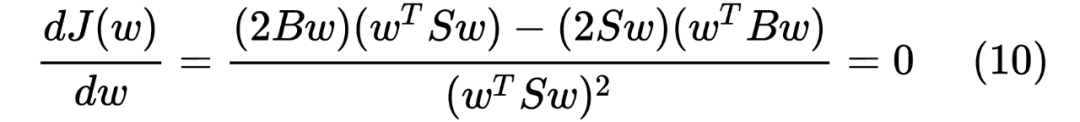
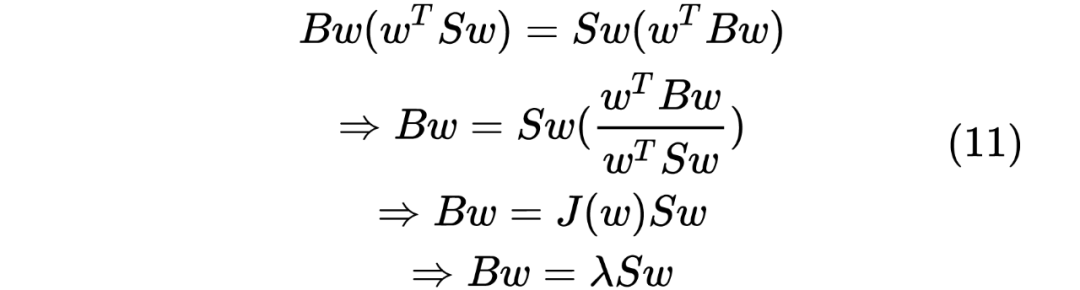
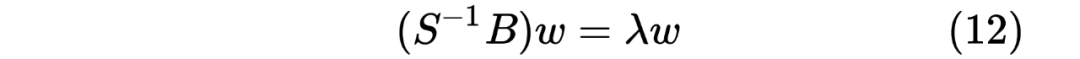
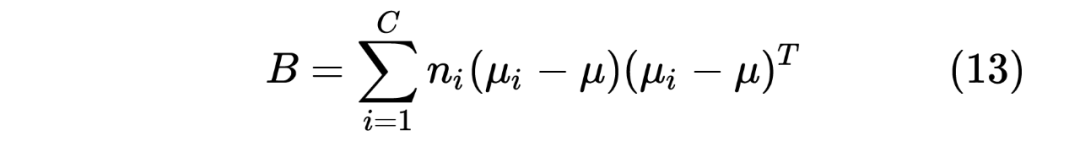
https://zhuanlan.zhihu.com/p/24709748
https://zhuanlan.zhihu.com/p/24863977

代码实现
import numpy as np
from sklearn import datasets
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
class MyLDA:
def __init__(self):
pass
def fit(self, X, y):
# 获取所有的类别
labels = np.unique(y)
#print(labels)
means = []
for label in labels:
# 计算每一个类别的样本均值
means.append(np.mean(X[y == label], axis=0))
# 如果是二分类的话
if len(labels) == 2:
mu = (means[0] - means[1])
mu = mu[:,None] # 转成列向量
B = mu @ mu.T
else:
total_mu = np.mean(X, axis=0)
B = np.zeros((X.shape[1], X.shape[1]))
for i, m in enumerate(means):
n = X[y==i].shape[0]
mu_i = m - total_mu
mu_i = mu_i[:,None] # 转成列向量
B += n * np.dot(mu_i, mu_i.T)
# 计算S矩阵
S_t = []
for label, m in enumerate(means):
S_i = np.zeros((X.shape[1], X.shape[1]))
for row in X[y == label]:
t = (row - m)
t = t[:,None] # 转成列向量
S_i += t @ t.T
S_t.append(S_i)
S = np.zeros((X.shape[1], X.shape[1]))
for s in S_t:
S += s
# S^-1B进行特征分解
S_inv = np.linalg.inv(S)
S_inv_B = S_inv @ B
eig_vals, eig_vecs = np.linalg.eig(S_inv_B)
#从大到小排序
ind = eig_vals.argsort()[::-1]
eig_vals = eig_vals[ind]
eig_vecs = eig_vecs[:, ind]
return eig_vecs
#构造数据集
def make_data(centers=3, cluster_std=[1.0, 3.0, 2.5], n_samples=150, n_features=2):
X, y = make_blobs(n_samples, n_features, centers, cluster_std)
return X, y
if __name__ == "__main__":
X, y = make_data(2, [1.0, 3.0])
print(X.shape)
lda = MyLDA()
eig_vecs = lda.fit(X, y)
W = eig_vecs[:, :1]
colors = ['red', 'green', 'blue']
fig, ax = plt.subplots(figsize=(10, 8))
for point, pred in zip(X, y):
# 画出原始数据的散点图
ax.scatter(point[0], point[1], color=colors[pred], alpha=0.5)
# 每个数据点在W上的投影
proj = (np.dot(point, W) * W) / np.dot(W.T, W)
#画出所有数据的投影
ax.scatter(proj[0], proj[1], color=colors[pred], alpha=0.5)
plt.show()
if __name__ == "__main__":
X, y = make_data(2, [1.0, 3.0]) #rint(X.shape)
lda = MyLDA()
eig_vecs = lda.fit(X, y)
W = eig_vecs[:, :1]
colors = ['red', 'green', 'blue']
fig, ax = plt.subplots(figsize=(10, 8))
for point, pred in zip(X, y):
# 画出原始数据的散点图
ax.scatter(point[0], point[1], color=colors[pred], alpha=0.5)
# 每个数据点在W上的投影
proj = (np.dot(point, W) * W) / np.dot(W.T, W)
#画出所有数据的投影
ax.scatter(proj[0], proj[1], color=colors[pred], alpha=0.5)
plt.show()
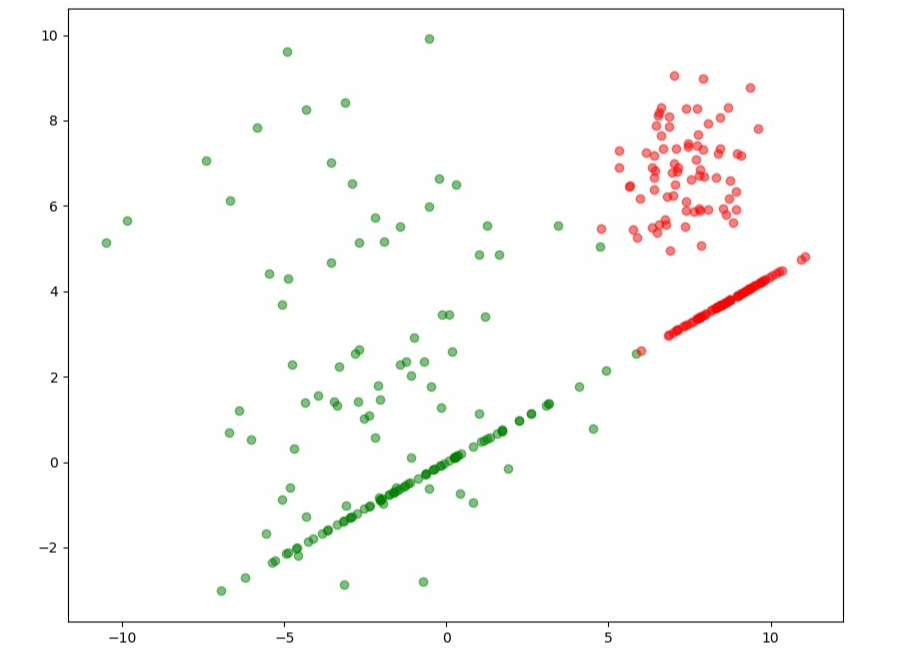
if __name__ == "__main__":
# 3类
X, y = make_data([[2.0, 1.0], [15.0, 5.0], [31.0, 12.0]], [1.0, 3.0, 2.5])
print(X.shape)
lda = MyLDA()
eig_vecs = lda.fit(X, y)
W = eig_vecs[:, :1]
colors = ['red', 'green', 'blue']
fig, ax = plt.subplots(figsize=(10, 8))
for point, pred in zip(X, y):
# 画出原始数据的散点图
ax.scatter(point[0], point[1], color=colors[pred], alpha=0.5)
# 每个数据点在W上的投影
proj = (np.dot(point, W) * W) / np.dot(W.T, W)
#画出所有数据的投影
ax.scatter(proj[0], proj[1], color=colors[pred], alpha=0.5)
plt.show()
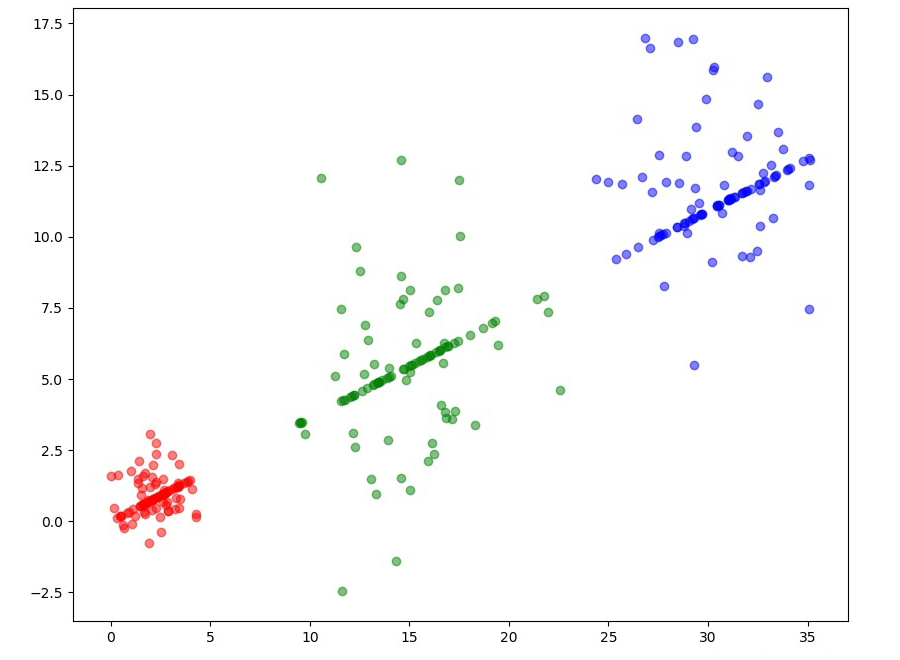
if __name__ == "__main__":
#X, y = load_data(cols, load_all=True, head=True)
X, y = make_data([[2.0, 1.0], [15.0, 5.0], [31.0, 12.0]], [1.0, 3.0, 2.5], n_features=4)
print(X.shape)
lda = MyLDA()
eig_vecs = lda.fit(X, y)
# 取前2个最大特征值对应的特征向量
W = eig_vecs[:, :2]
# 将数据投影到这两个特征向量上,从而达到降维的目的
transformed = X @ W
plt.subplots(figsize=(10, 8))
plt.scatter(transformed[:, 0], transformed[:, 1], c=y, cmap=plt.cm.Set1)
plt.show()
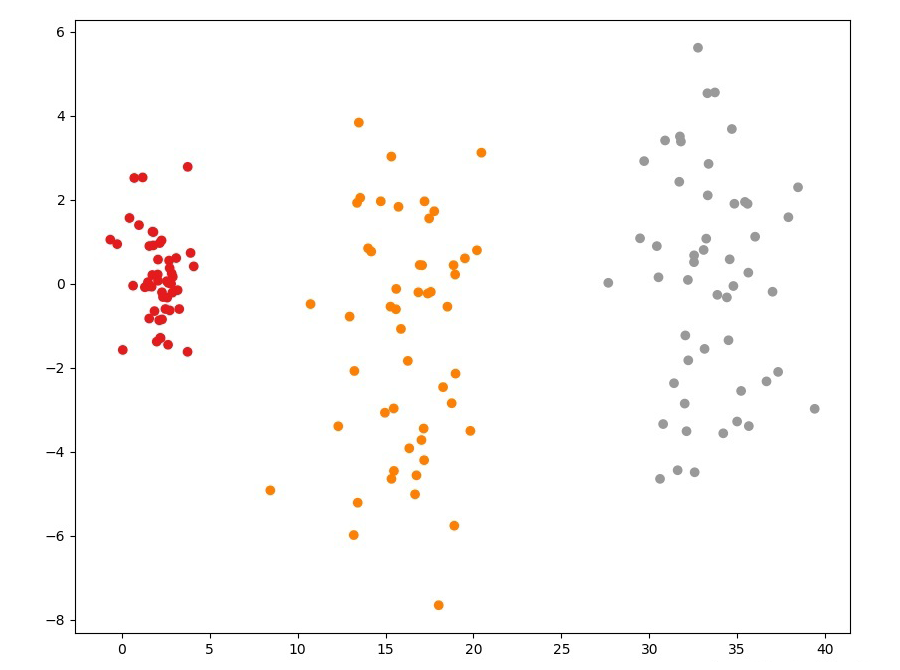
if __name__ == "__main__":
X, y = make_data([[2.0, 1.0], [15.0, 5.0], [31.0, 12.0]], [1.0, 3.0, 2.5], n_features=4)
print(X.shape)
lda = MyLDA()
eig_vecs = lda.fit(X, y)
# 取前2个最大特征值对应的特征向量
W = eig_vecs[:, :2]
# 将数据投影到这两个特征向量上,从而达到降维的目的
transformed = X @ W
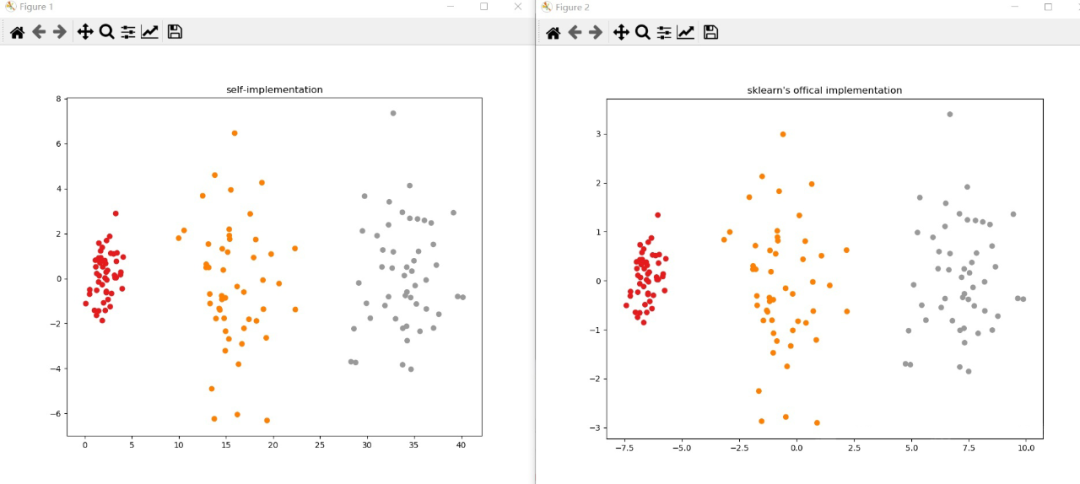
plt.subplots(figsize=(10, 8))
plt.scatter(transformed[:, 0], transformed[:, 1], c=y, cmap=plt.cm.Set1)
plt.title('self-implementation')
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
sk_lda = LinearDiscriminantAnalysis()
sk_lda.fit(X, y)
transformed = sk_lda.transform(X)
plt.subplots(figsize=(10, 8))
plt.scatter(transformed[:, 0], transformed[:, 1], c=y, cmap=plt.cm.Set1)
plt.title("sklearn's offical implementation")
plt.show()

总结
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


登录查看更多
相关内容

Arxiv
3+阅读 · 2018年2月20日



相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年2月20日