百面机器学习!算法工程师面试宝典!| 码书


本文部分内容经授权节选自《百面机器学习》
责编 | 胡巍巍
去年年底到今年年初,整个互联网圈,都笼罩着裁员的阴霾。

以至于很多程序员,都不敢看新闻了。
但是,昨天SOHO中国董事长潘石屹,在出席活动时,被问到怎么看待当前的这个裁员潮时表示,“未来最需要创造性的人才,能够为社会、为城市创造美的人,数学好的人,这些人不会被裁掉。”


图源见水印
数学好的人?
咦,这说的不就是程序员吗?
试问,哪个程序员不得懂点数学呢?
而,机器学习设计到很多数学面试题,今天就跟大家分享两个超级高频的机器学习面试题!

LDA (线性判别分析) 和 PCA 的区别与联系
首先将LDA 扩展到多类高维的情况,以和问题1 中PCA 的求解对应。假设有N 个类别,并需要最终将特征降维至d 维。因此,我们要找到一个d 维投影超平面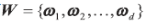
回顾两个散度矩阵, 类内散度矩阵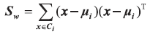
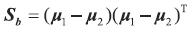
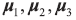
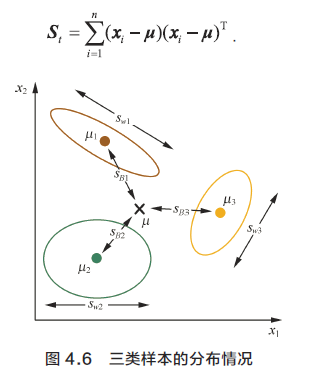
如果把全局散度定义为类内散度与类间散度之和,即St=Sb+Sw,那么类间散度矩阵可表示为
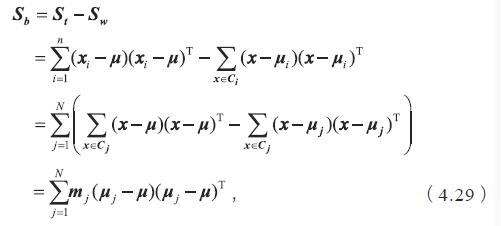
其中mj 是第j 个类别中的样本个数,N 是总的类别个数。从式(4.29)可以看出,类间散度表示的就是每个类别中心到全局中心的一种加权距离。我们最大化类间散度实际上优化的是每个类别的中心经过投影后离全局中心的投影足够远。
根据LDA 的原理,可以将最大化的目标定义为
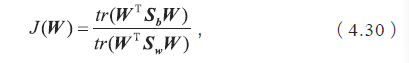
其中W是需要求解的投影超平面,WTW=I,根据问题2 和问题3 中的部分结论,我们可以推导出最大化J(W) 对应了以下广义特征值求解的问题

求解最佳投影平面
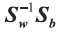
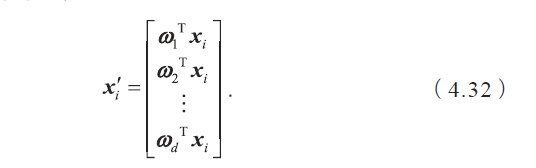
(1)计算数据集中每个类别样本的均值向量μj,及总体均值向量μ。
(2)计算类内散度矩阵Sw,全局散度矩阵St,并得到类间散度矩阵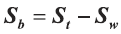
(3)对矩阵
(4)取特征值前d 大的对应的特征向量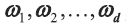
从PCA 和LDA 两种降维方法的求解过程来看,它们确实有着很大的相似性,但对应的原理却有所区别。
首先从目标出发,PCA 选择的是投影后数据方差最大的方向。由于它是无监督的,因此PCA 假设方差越大,信息量越多,用主成分来表示原始数据可以去除冗余的维度,达到降维。而LDA 选择的是投影后类内方差小、类间方差大的方向。其用到了类别标签信息,为了找到数据中具有判别性的维度,使得原始数据在这些方向上投影后,不同类别尽可能区分开。
举一个简单的例子,在语音识别中,我们想从一段音频中提取出人的语音信号,这时可以使用PCA 先进行降维,过滤掉一些固定频率(方差较小)的背景噪声。但如果我们的需求是从这段音频中区分出声音属于哪个人,那么我们应该使用LDA 对数据进行降维,使每个人的语音信号具有区分性。
另外,在人脸识别领域中,PCA 和LDA 都会被频繁使用。基于PCA 的人脸识别方法也称为特征脸(Eigenface)方法,该方法将人脸图像按行展开形成一个高维向量,对多个人脸特征的协方差矩阵做特征值分解,其中较大特征值对应的特征向量具有与人脸相似的形状,故称为特征脸。Eigenface for Recognition 一文中将人脸用7 个特征脸表示(见图4.7),于是可以把原始65536 维的图像特征瞬间降到7 维, 人脸识别在降维后的空间上进行。然而由于其利用PCA 进行降维,一般情况下保留的是最佳描述特征(主成分),而非分类特征。如果我们想要达到更好的人脸识别效果,应该用LDA 方法对数据集进行降维, 使得不同人脸在投影后的特征具有一定区分性。
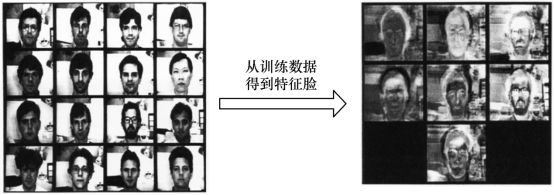
从应用的角度,我们可以掌握一个基本的原则—对无监督的任务使用PCA 进行降维,对有监督的则应用LDA。

K-均值算法收敛性的证明
首先,我们需要知道K 均值聚类的迭代算法实际上是一种最大期望算法(Expectation-Maximization algorithm),简称EM 算法。EM 算法解决的是在概率模型中含有无法观测的隐含变量情况下的参数估计问题。假设有m 个观察样本,模型的参数为θ,最大化对数似然函数可以写成如下形式:
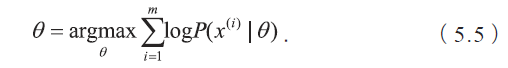
当概率模型中含有无法被观测的隐含变量时,参数的最大似然估计变为:
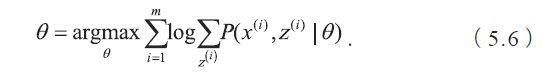
由于z(i) 是未知的, 无法直接通过最大似然估计求解参数, 这时就需要利用EM 算法来求解。假设z(i) 对应的分布为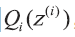
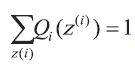
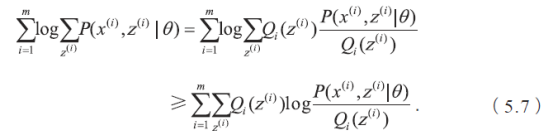
要使上式中的等号成立,需要满足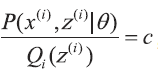
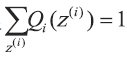
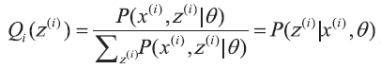
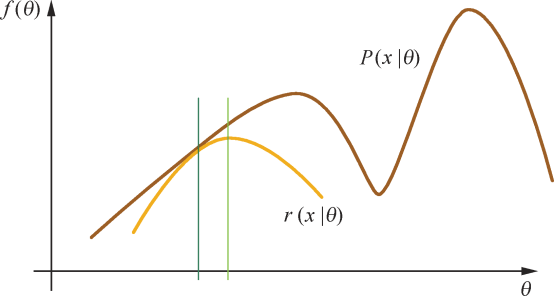
图5.5 是一个θ 为一维的例子,其中棕色的曲线代表我们待优化的函数,记为f(θ),优化过程即为找到使得f(θ) 取值最大的θ。在当前θ 的取值下(即图中绿色的位置),可以计算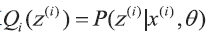
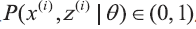
由上面的推导,EM 算法框架可以总结如下,由以下两个步骤交替进行直到收敛。
(1)E 步骤:计算隐变量的期望

(2)M 步骤:最大化
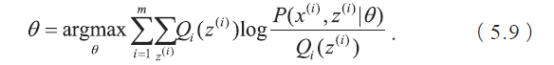
剩下的事情就是说明K 均值算法与EM 算法的关系了。K 均值算法等价于用EM 算法求解以下含隐变量的最大似然问题:
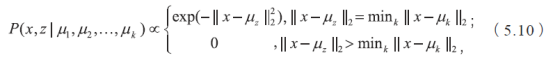
其中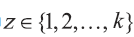
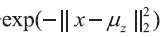
在E 步骤,计算
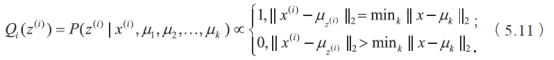
这等同于在K 均值算法中对于每一个点x(i) 找到当前最近的簇z(i)。
在M步骤,找到最优的参数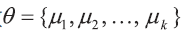
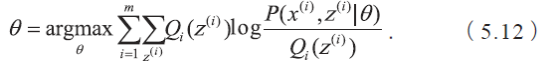
经过推导可得
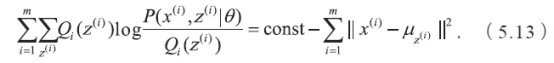
因此,这一步骤等同于找到最优的中心点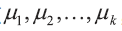
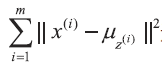
......
以上是人民邮电出版社的书籍《百面机器学习:算法工程师带你去面试》中的部分精华。
那么,这到底是怎样的一本书?
看看编者们为它付出的汗水、
和出版后的战绩就知道啦↓
15位一线算法工程师,
来自全球顶尖视频流媒体公司hulu,
在面试过数百名候选人后,
公开124道基于真实场景的原创面试题,
历时6个月集体编著,
上市首日即位列京东计算机新书榜第1名。


作者群像
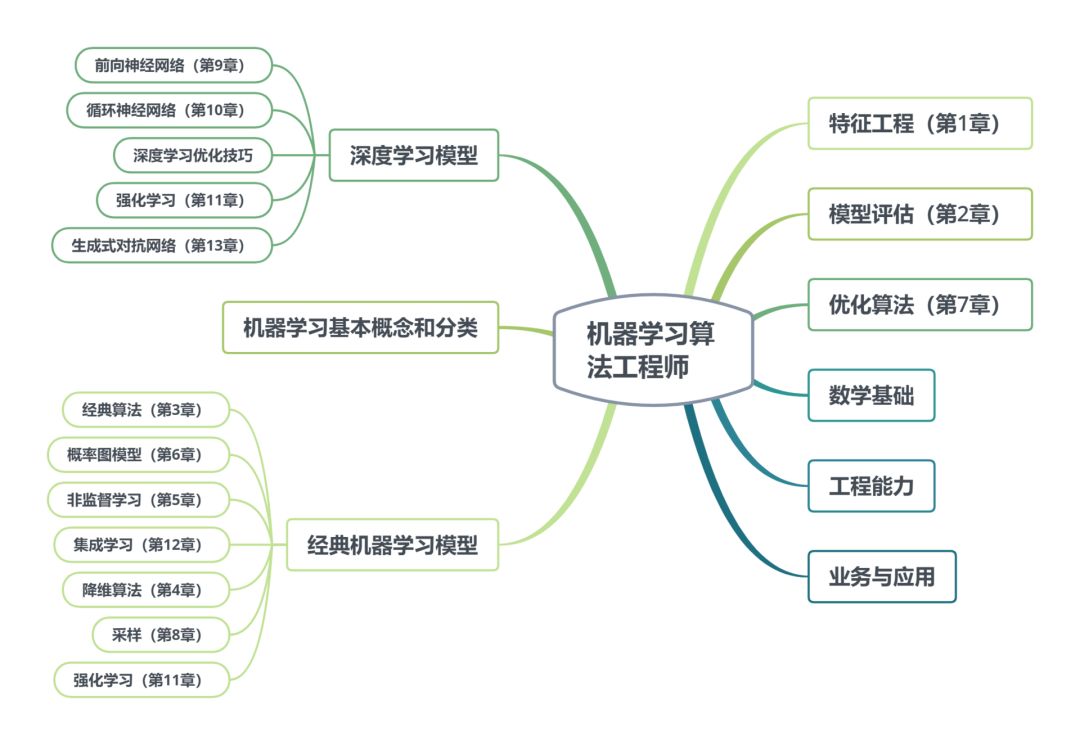
《百面机器学习》学习脉络图
微软全球执行副总裁、美国工程院院士沈向洋,高度认可这本书:“这本书致力于普及人工智能和机器学习,帮助每个软件工程师成为自信的AI实践者,每个数据科学家成为优秀的AI研究者。”
《浪潮之巅》《数学之美》作者吴军亦很美誉此书:“这本书教授大家如何搭建计算机理论和算法与具体应用之间的桥梁。它可以让计算机的从业者对理论的认识有一个飞跃,也可以让非计算机专业的工程人员了解计算机科学这个强大的工具。”
这么好的书,会不会很贵?
以及怎样才可以买到?
一点都不贵!
并且在这篇文章里就能买到!
程序人生(ID:coder_life)联合人民邮电出版社,
面向程序人生用户
推出7.5折包邮拼团优惠价,
2人即可成团!
赶快扫描下面二维码、
或者点击阅读原文购书吧!
截止时间为3月4日下周一晚上19:00,
欲购从速哦!

春招胜利,
就看《百面机器学习:算法工程师带你去面试》!
点击阅读原文,也可进入购物页面哦!




