【泡泡一分钟】促使LSTMs非常早期地预期动作(ICCV2017-27)
每天一分钟,带你读遍机器人顶级会议文章
标题:Encouraging LSTMs to Anticipate Actions Very Early
作者:Mohammad Sadegh Aliakbarian, Fatemeh Sadat Saleh, Mathieu Salzmann, Basura Fernando, Lars Petersson, Lars Andersson
来源:International Conference on Computer Vision (ICCV 2017)
播音员:zzq
编译:张建
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

与被广泛研究的从完整序列中识别动作的问题相反,动作预期旨在从只有部分可用的视频中识别出动作。因此,它是那些要求尽早做出反应的计算机视觉应用成功的关键,例如自主导航。
在本文中,我们提出了一种新的动作预期方法,即使在很小百分比的视频序列中也能达到很高的预测精度。为此,我们利用上下文感知和动作感知的特征,开发了一个多级LSTM架构,并介绍了一种新的损失函数,促使模型尽早地预测出正确的类别。
我们对标准的基准测试数据集的实验证明我们的方法的好处;我们在早期预测方面超越了目前最先进的动作预期方法,相对精度方面在JHMDB-21上提高22.0%,UT-Interaction上提高14.0%,UCF-101上提高49.9%。
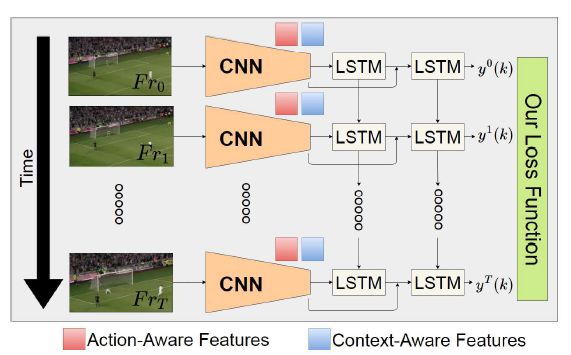
图1 我们的方法概述。给定一小部分连续数据,我们的方法能够非常高性能地预测出动作类别。例如,在UCF-101上,只给定前1%的视频,用我们的方法预测行为可以获得高于80%的准确率。为了实现这一点,我们设计了一个模型,它利用动作和上下文感知的特征,以及一个新的损失函数,促使模型尽早做出正确的预测。
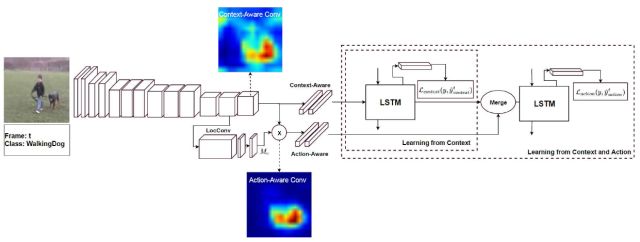
图2 我们的方法概述。我们提议提取上下文感知的特征,编码关于场景的全局信息,并将它们与关注于动作本身的动作感知特征相结合。为此,我们引入了一个多级LSTM架构,利用两种特征来预测或预报动作。需要注意的是,可视化的缘故,彩色地图是通过一个超过512通道的平均池化操作从三维张量(512×W×H)得到的。
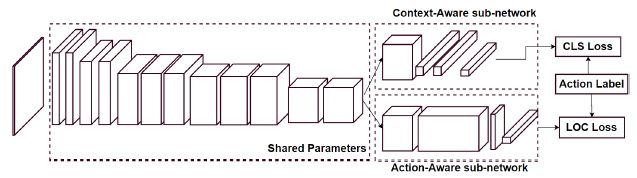
图3 我们的特征提取网络。我们特征提取的CNN模型是基于VGG-16结构进行一些修改。直到conv5-2,网络与VGG-16相同。此层的输出连接到两个子模型。第一种方法通过提供全局图像表示提取上下文感知的特征。第二个依赖于另一个网络来提取动作感知特征。
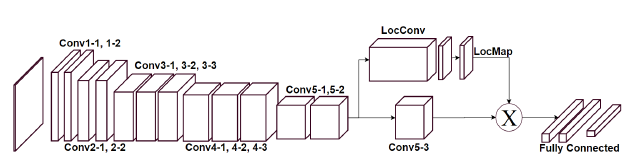
图4 动作感知特征提取。给定微调的特征提取网络,我们引入一个新的层,改变conv5-3输出。这让我们过滤掉不相关的conv5-3特点,关注于动作本身。我们的动作感知特性被作为最后一个完全连接层的输出。

Abstract
In contrast to the widely studied problem of recognizing an action given a complete sequence, action anticipation aims to identify the action from only partially available videos. As such, it is therefore key to the success of computer vision applications requiring to react as early as possible, such as autonomous navigation. In this paper, we propose a new action anticipation method that achieves high prediction accuracy even in the presence of a very small percentage of a video sequence. To this end, we develop a multi-stage LSTM architecture that leverages context-aware and action-aware features, and introduce a novel loss function that encourages the model to predict the correct class as early as possible. Our experiments on standard benchmark datasets evidence the benefits of our approach; We outperform the state-of-the-art action anticipation methods for early prediction by a relative increase in accuracy of 22.0% on JHMDB-21, 14.0% on UT-Interaction and 49.9% on UCF-101.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
点击“阅读原文”,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



