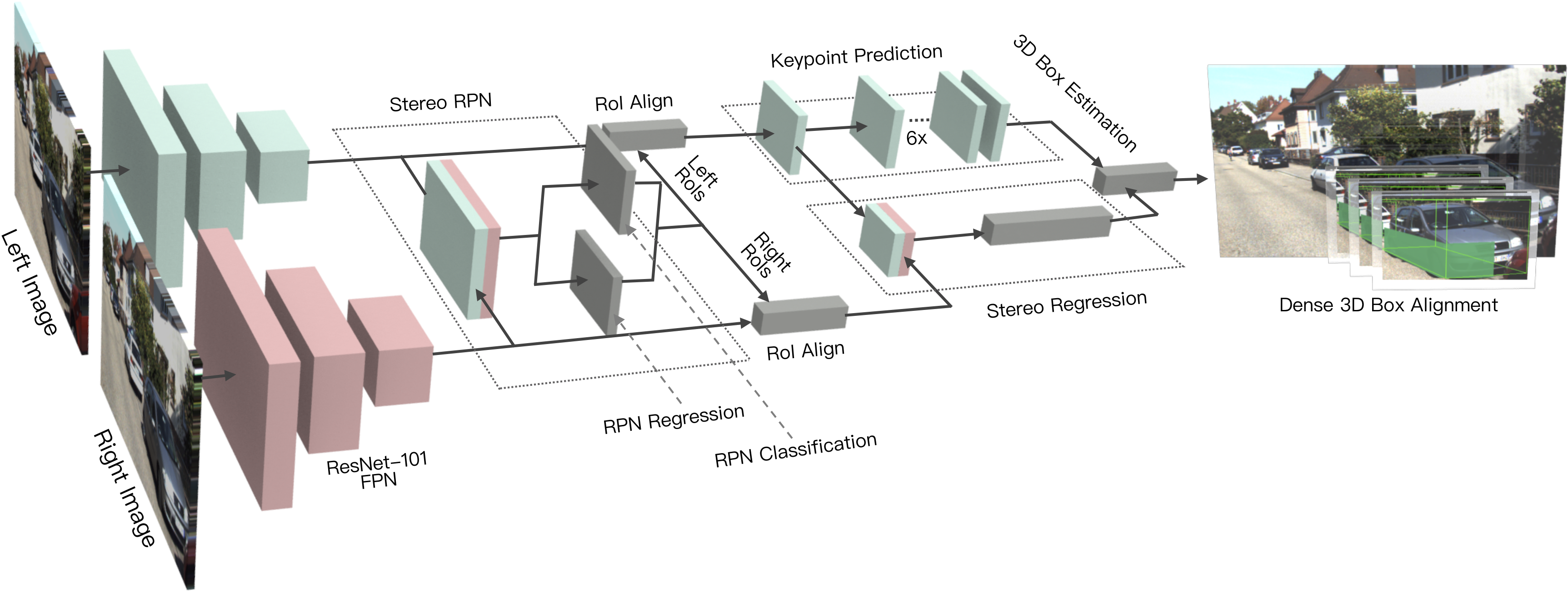
We propose a 3D object detection method for autonomous driving by fully exploiting the sparse and dense, semantic and geometry information in stereo imagery. Our method, called Stereo R-CNN, extends Faster R-CNN for stereo inputs to simultaneously detect and associate object in left and right images. We add extra branches after stereo Region Proposal Network (RPN) to predict sparse keypoints, viewpoints, and object dimensions, which are combined with 2D left-right boxes to calculate a coarse 3D object bounding box. We then recover the accurate 3D bounding box by a region-based photometric alignment using left and right RoIs. Our method does not require depth input and 3D position supervision, however, outperforms all existing fully supervised image-based methods. Experiments on the challenging KITTI dataset show that our method outperforms the state-of-the-art stereo-based method by around 30% AP on both 3D detection and 3D localization tasks. Code will be made publicly available.
翻译:我们建议了一种3D物体自动驾驶探测方法,充分利用立体图像中的稀薄和稠密、语义和几何信息。 我们的方法叫做Stereo R-CNN, 将立体输入的更快R-CNN扩展为立体输入, 以同时检测和连接左面和右面图像中的物体。 我们在立体区域建议网络之后增加了额外的分支, 以预测稀疏的键点、 观点和物体尺寸, 与 2D 左侧框相结合, 以计算粗糙的 3D 物体捆绑盒。 然后我们用以区域为基础的光度校准, 利用左面和右面的RoIs 来回收精确的 3D 捆绑框。 我们的方法不需要深度输入和 3D 定位监督, 但是, 优于所有现有的完全受监督的基于图像的方法 。 在挑战的 KITTI 数据集上进行的实验显示, 我们的方法在3D 探测和 3D 本地化任务中, 大约 30% AP 都比基于立体立体法 。