【泡泡一分钟】复杂室内环境中声源定位的自监督增量学习
每天一分钟,带你读遍机器人顶级会议文章
标题:Self-Supervised Incremental Learning for Sound Source Localization in Complex Indoor Environment
作者:Hangxin Liu, Zeyu Zhang, Yixin Zhu, Song-Chun Zhu
来源:International Conference on Robotics and Automation (ICRA) 2019
编译:张建
审核:颜青松,陈世浪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

本文提出了一种在由多个房间组成的复杂室内环境中,利用麦克风阵列对人的声源进行定位的移动机器人增量学习框架。与利用到达方向(DOA)估计的传统方法不同,该框架允许机器人通过增量学习方案积累训练数据,并随着时间的推移提高预测模型的性能。
具体地说,我们使用从自动编码器获得的隐式声学特征以及地图上的几何特征进行训练。开发了一个自监督过程,该模型根据房间的优先级顺序来进行探索,对采集到的数据分配地面真值标签,实时更新学习模型。该框架不需要预先收集数据,可以直接应用于现实场景,而无需任何人工监督或干预。
在实验中,我们证明了使用大约20个训练样本,预测精度达到67%,最终在120个样本中达到90%的精度,超过了先前的基于分类的具有明显GCC-PHAT特征的方法。

图1 由多个房间组成的典型室内环境。根据用户的口头命令,提出的增量学习框架将以探索房间的优先级排序,由蓝色条的高度表示。在这个例子中,机器人最初沿着红色路径探索错误的房间,这是一个负样本。按照排名顺序,它继续探索绿色通道的第二个房间。对用户的检测会导致对训练数据进行正面标记。所有的正负数据都会被实时标记,以适应未知复杂室内环境中的新用户,并通过累积来完善当前模型,以提高未来的预测精度。
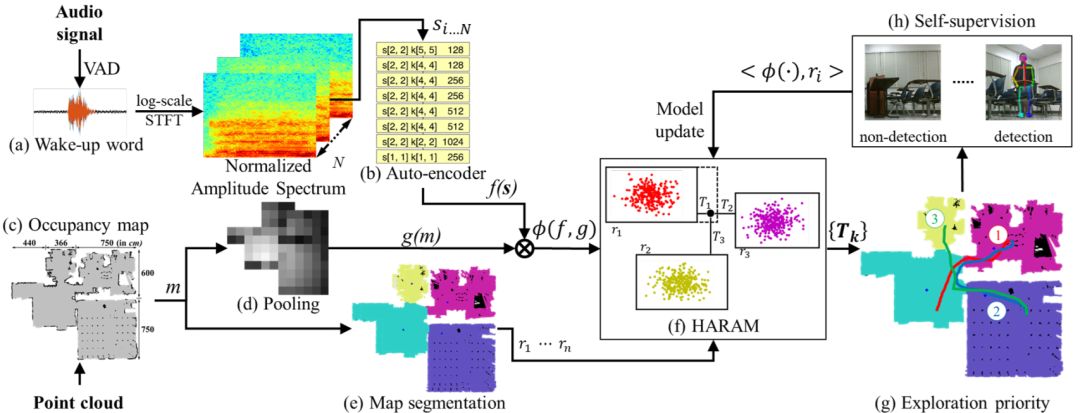
图2 提出的方法使用了自监督增量学习方案。

图3 人体姿势检测示例(上图);非检测示例(底部)。
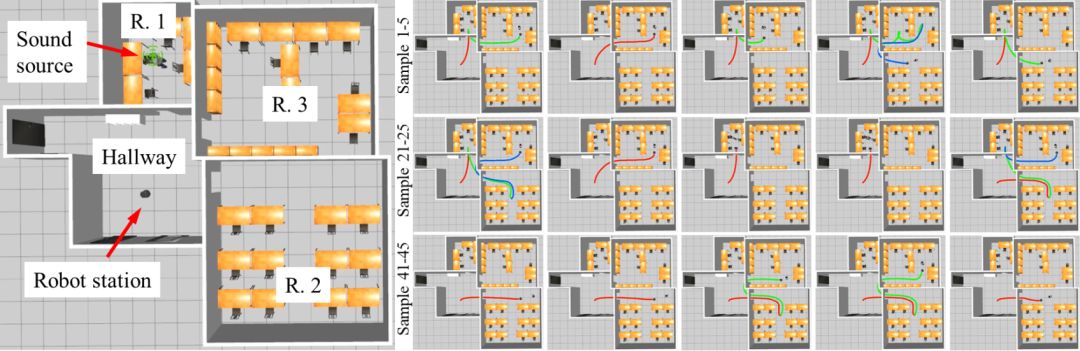
图4 模拟中增量学习过程的图示。声源在相应的现实世界中的位置被可视化。机器人随后按照模型预测的顺序访问房间。红色、绿色和蓝色轨迹表示机器人访问的第一、第二和第三个房间。行数描述了用于查找声源位置的轨迹数。

Abstract
This paper presents an incremental learning framework for mobile robots localizing the human sound source using a microphone array in a complex indoor environment consisting of multiple rooms. In contrast to conventional approaches that leverage direction-of-arrival (DOA) estimation, the framework allows a robot to accumulate training data and improve the performance of the prediction model over time using an incremental learning scheme. Specifically, we use implicit acoustic features obtained from an auto-encoder together with the geometry features from the map for training. A self-supervision process is developed such that the model ranks the priority of rooms to explore and assigns the ground truth label to the collected data, updating the learned model on-the-fly. The framework does not require pre-collected data and can be directly applied to real-world scenarios without any human supervisions or interventions. In experiments, we demonstrate that the prediction accuracy reaches 67% using about 20 training samples and eventually achieves 90% accuracy within 120 samples, surpassing prior classification-based methods with explicit GCC-PHAT features.
如果你对本文感兴趣,请点击点击阅读原文下载完整文章,如想查看更多文章请关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



