图谱实战 | 阿里周晓欢:如何将实体抽取从生成问题变成匹配问题?
转载公众号 | DataFunSummit

分享嘉宾:周晓欢 阿里巴巴 算法专家
编辑整理:刘香妍 中南财经政法大学
出品平台:DataFunSummit
导读:实体抽取或者说命名实体识别 ( NER ) 在信息抽取中扮演着重要角色,常见的实体抽取多是对文本进行子信息元素的抽取,但对语音的实体抽取当前应用也比较广泛。
今天很高兴邀请到来自阿里巴巴天猫精灵事业部人工智能部的周晓欢,来和大家分享天猫精灵在娱乐播放助手中关于实体抽取的一些创新与实践。本次分享的主题为天猫精灵在实体抽取中的创新与实践,主要内容包括:① 天猫精灵业务背景介绍;② 端到端的语义理解模型;③ 基于内容库的端到端的实体抽取模型Speech2Slot;④ 无监督语音语义预训练。
首先和大家分享下天猫精灵内容点播的业务背景。
1. 业务背景介绍

天猫精灵它作为一个智能音箱,内容点播是它最重要的功能之一。当一个用户他有具体的点播意图的时候,比如说他说:天猫精灵,我想听刘德华的忘情水。这个时候就会进入内容点播场景。
2. 传统语音点播链路与问题
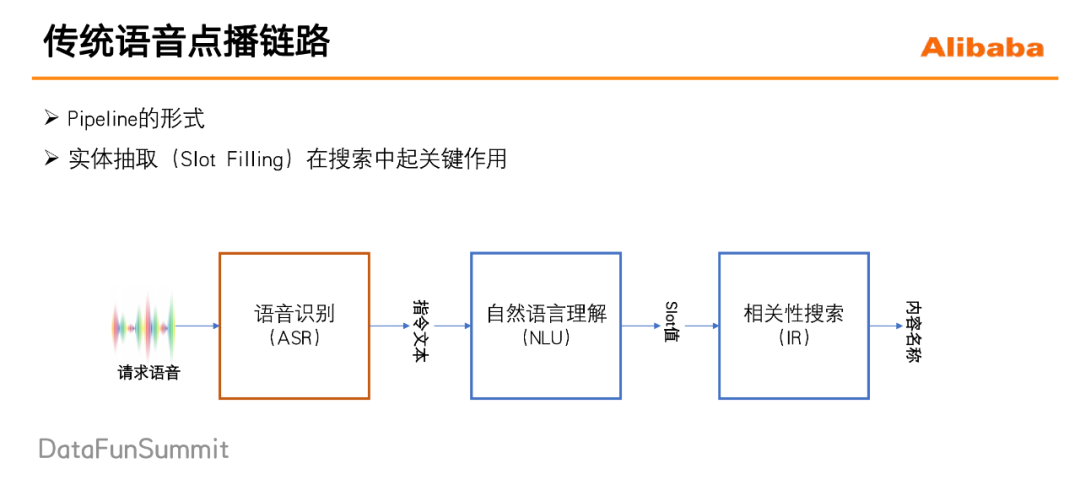
天猫精灵的内容点播场景跟传统的搜索不一样的地方就在于:用户是通过语音交互,并且是以自然语言请求的方式来进行点播的。面对这种语音的并且是自然语言请求的自然语言的方式的这种请求,传统的做法为pipeline式:
一段用户语音首先进入到语音识别ASR模块,识别出相应的文本信息;
将文本信息送到自然语言处理NLU模块当中进行实体抽取;
将识别到的实体(例如歌手名)送入相关性搜索IR模块当中进行内容检索,具体查找出用户想要得到的内容。
但这种做法缺陷是:每一个模块对于整个系统的性能都起着关键的作用,一旦前面的某个模块出现了错误,后续的模块可能就会出现连续的错误。具体而言这种方法存在的问题如下:
① 首先是曝光偏差的问题。NLU模型在训练的过程中基于准确的文本信息去进行训练,但是在测试阶段,它却是基于ASR的输出文本来进行预测的,这就导致NLU模型在训练和测试过程中,它面临的输入分布是不一致的,这就是曝光偏差问题。曝光偏差问题会使得NLU模型在ASR结果出现错误的时候变得非常脆弱。
② 其次训练目标不一致的问题。在pipeline当中,各个模块它的训练目标没有办法和整个系统的训练目标保持一致,例如语音识别ASR模块,它的训练目标是去降低所识别文本的字错误率。但是对于整个请求的达成来说,一个请求当中不同位置的字错误率对于最终请求的达成影响是不一样的:比如说用户他说我想听刘德华的忘情水,这个时候识别错了”我想听“,和识别错”忘情水“,对最终整个请求的达成影响是不一样的,识别错了”忘情水“对最终整个请求的达成影响会更大一些。
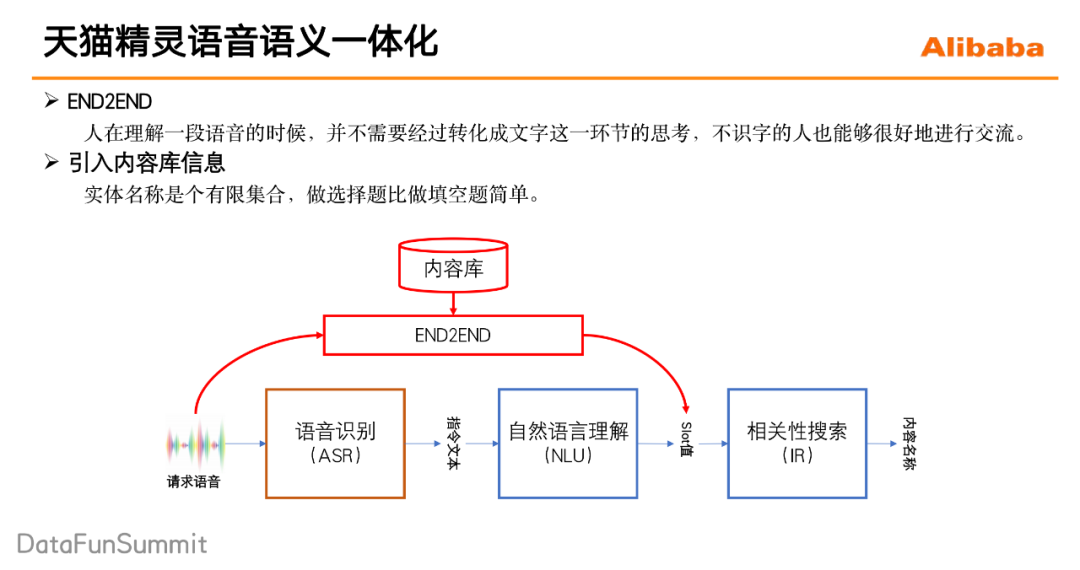
针对这种pipeline形式存在的问题,在学术界展开了广泛的研究和讨论,他们提出了构建一个端到端的语音语义理解的模型,也就是说要直接基于原始的声音信号去做语义的理解。
端到端的语音语义理解模型,主要应用在语义理解任务中的分类任务和生产任务上。
1. 分类任务
分类任务主要是应用在领域识别和意图识别上,直接基于语音的信号构建一个端到端的语音语义理解模型,训练目标就是意图理解或者是领域识别的训练目标。端到端的模型避免了之前那种pipeline形式的中间信息传递的损失,从而也能得到更好的一个效果。

2. 生成任务
生成任务上主要是应用在实体抽取上,端到端的实体抽取模型主要目前主要有两种结构形式。
第一种,采用的是一种流式处理的模型结构,跟端到端流式处理的ASR模型的模型结构其实是一致的,但是不同的地方在于,它在输出的文本序列中间加入了一些特殊的标志符号,去标示出它所识别的实体名称所在的位置,比如左图中加了两个“$”符号去标志出歌手“刘德华”的位置,以及加了“#”去标志出歌名“忘情水”所在的位置。

另外一种模型结构是采用的这种encoder-decoder的翻译模型的模型结构,它是直接基于的原始声音信号,直接去翻译出所要抽取的实体名名称的文本序列。
这里将整个端到端的实体抽取模型抽象成这样的两个过程,分别是声学建模过程和语言建模过程。声学建模过程是指对原始的声音信息进行一个处理和建模,而语言建模过程是指对输出的文本用一个语言模型去学习它的语法规律。在天猫精灵内容点播场景里,所要识别的视频实体名称多是一些歌手名,歌名等等。同时在点播内容库里存在着海量的歌手名和歌名。这些海量的歌手名和歌名,对于语言模型来说,要去建模是非常困难的。困难之处如下:
① 内容实体名称存在一音多字的情况,比如雷雨心的《记念》和蔡健雅的《纪念》,使得模型对于一些长尾的内容实体名称的识别并不能做得特别好。
② 同时语言模型对于内容实体名称的泛化能力并不够,这是主要是因为内容实体名称通常不具备有语法的约束,甚至是反语言模型的,毫不相关的几个字拼凑在一起都可能是一个歌名,因此语言模型很难对内容实体名称去进行一个建模。
③ 此外用户还经常存在口音的问题。
因此,针对内容实体名称存在的困难,在天猫精灵的语音与一体化中,不仅仅希望引入一个端到端的语音语义理解模型来减少以前的那种pipeline方式带来的信息损失,还希望能够引入更多的信息来帮助模型去做好内容实体名称的识别。最直接的想法就是考虑的是引入内容库的信息。已知内容库里已经有一首陈奕迅的《圣诞结》,这个时候去识别“she4ng da4n jie2”这个发音就会变得简单了很多。同时,用户请求的这些歌手歌名其实都是存在于内容库里,所要识别这些实体名称其实是在一个有限的集合内,因此可以把实体抽取从生成问题变成一个匹配的问题,做选择题总是比做填空题简单。
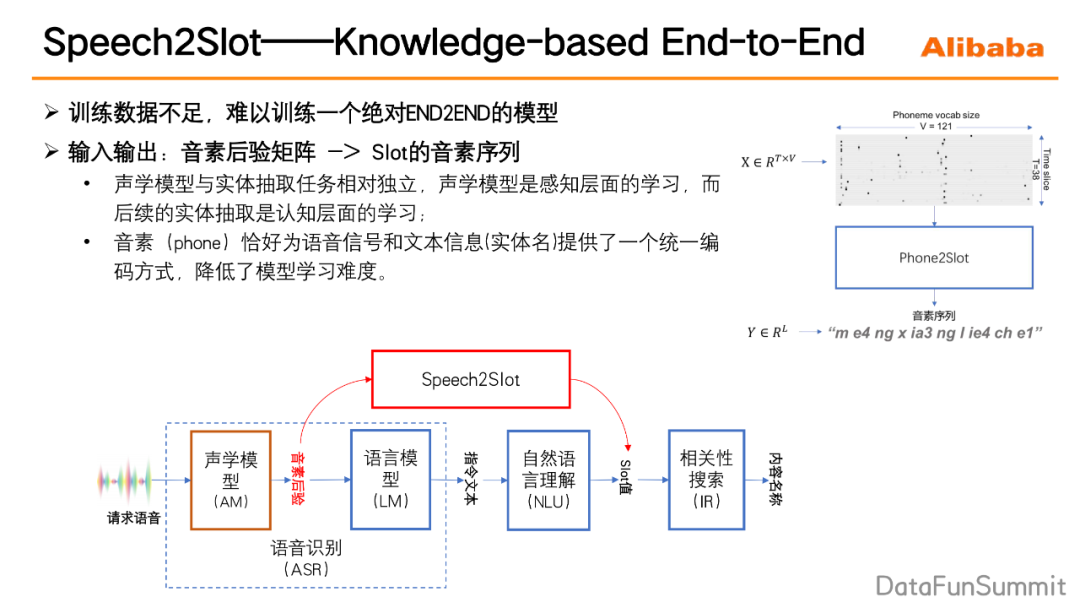
1. 模型的输入和输出
输入的是用户请求的音素后验矩阵(音素它类似于拼音的序列),输出的是slot的音素序列。音素后验矩阵是ASR模型的一个中间的输出结果矩阵,可以理解为是一个时间步数乘以音素词典大小的这样一个矩阵,在每一个时间步上都有一个音素的概率分布。为什么要选取ASR的中间结果音素后验来作为输入?这主要是因为我们认为声学建模与实体抽取任务其实是两个相对独立的任务,声学建模可以认为它是一个感知层面的学习,而后续的实体抽取的任务,可以认为它是一个认知层面的一个学习,将感知学习和认知学习进行分离,对最终整个系统的效果的影响应该不会太大。另外,选择音素后验矩阵作为输入,然后slot的音素序列作为输出,通过这种选择,音素可以恰好为语音信号和文本信号提供了一个统一的编码方式,使得整个模型的训练难度大大的降低。
2. 模型结构
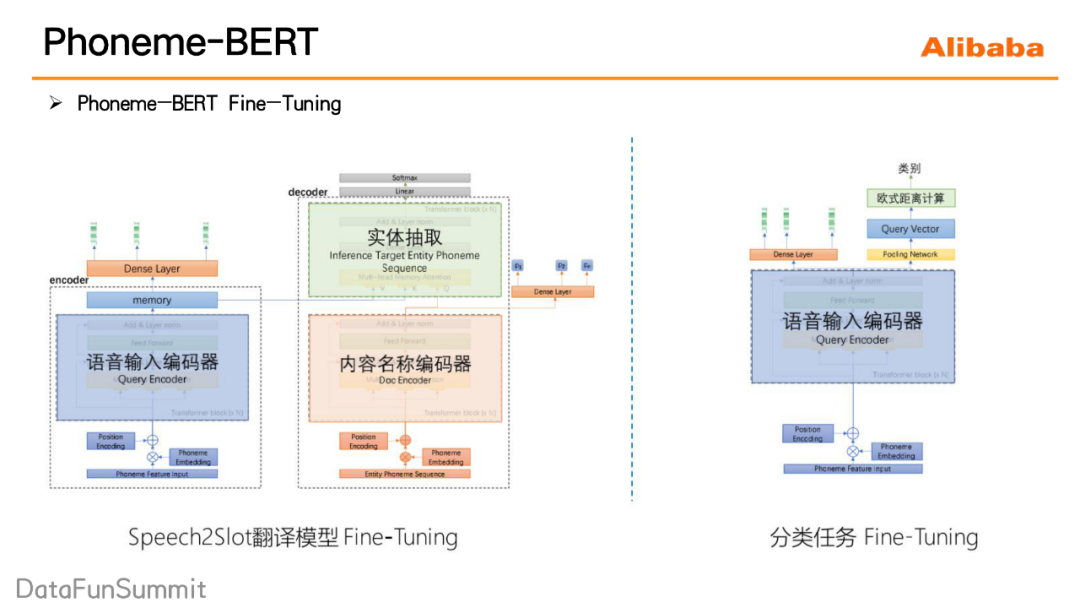
我们的模型希望去建模这样一个过程:首先在一段请求语音中截取实体名称所在的声音切片,然后再对这个声音切片进行一个特征的抽取和处理,最后基于抽取处理后的特征进行一个分类,看它到底是属于内容库里的哪一个实体名称。这里需要注意的一点是,实体名称在声音特征上并不具备特殊性,因此在进行一个语音实体名称的声音切片的定位时,还需要引入一些上下文的知识,比如内容库的知识等来辅助实体名称的定位。所以最终的整个的模型结构就如下图所示,主要分三部分来介绍:Speech encoder、Knowledge encoder、Bright layer。
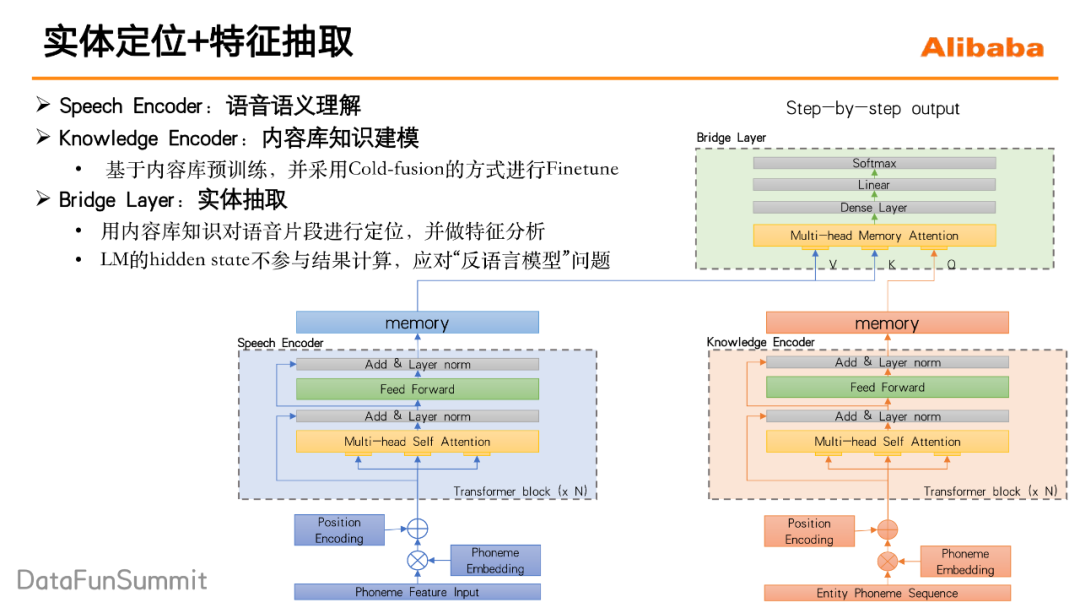
① Speech encoder(图中蓝色部分)。我们对请求语音进行一个语音语义的理解,然后生成一个memory的矩阵,这里就是常规transformer结构,它可以帮助捕捉到重点的语义信息。
② Knowledge encoder(图中橘色部分)。通过预训练的方式来将内容库的知识建模在knowledge encoder当中,它的预训练方式采用的是语言模型的预训练的方式,训练语料是内容库中的所有的实体名称,通过这种方式,knowledge encoder能够提前看到内容库里都存在哪些实体名称,同时去记住这些实体名称。
③ Bright layer(图中绿色部分)。它实现的是一个实体定位和实体分类的这样一个作用。首先将的knowledge encoder每一个step的输出,来对Speech encoder的memory矩阵做attention,然后定位出内容实体的声音切片所在的位置,同时还会对抽出来的相应的这些信息做一个处理,最终输出它接下来这一帧应该输出哪一个音素。注意这里knowledge encoder的输出只去参与了attention的过程,并不参与最后音素概率的计算,这保证模型不过分依赖语音模型的结果。
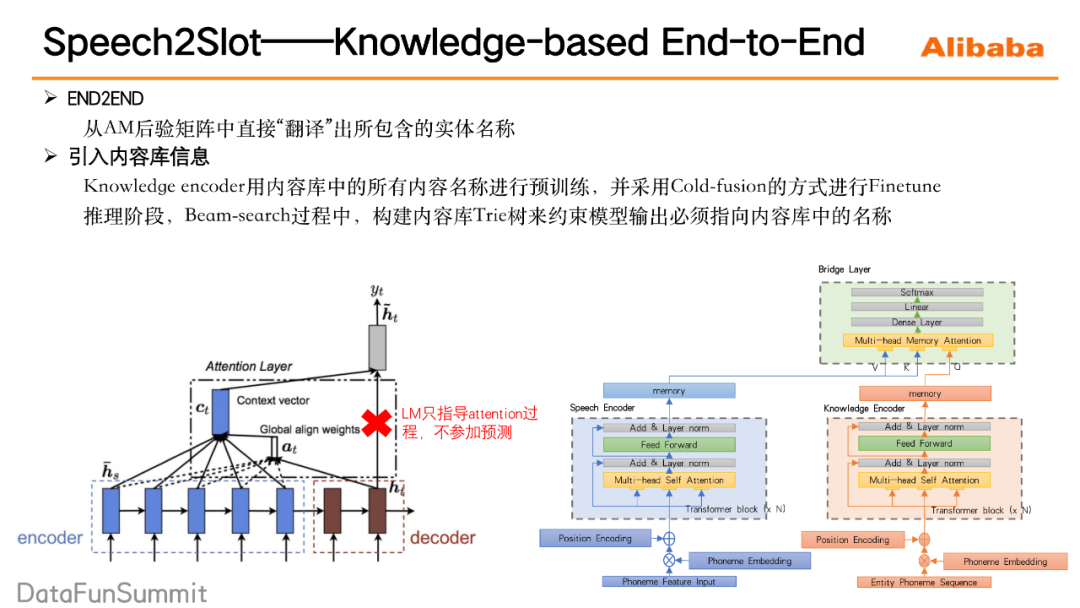
3. 引入内容库信息的方法
在模型中,通过以下两点来引入内容库信息:Knowledge encoder用内容库中所有的内容名称进行预训练,并采用Cold-fusion的方式进行Finetune。另外在推理阶段,会提前的把内容库里所有的内容名称构建成一个Trie树,在Beam-search过程中,构建的Trie树用来约束模型输出必须指向内容库中的某一名称。
4. 模型效果

1. 为什么要进行无监督语音语义预训练
训练数据不足。
语义理解能力,对于整个端到端的实体抽取模型非常重要。在天猫精灵的模型中抽取实体时:主要是encoder的语义理解能力,以及knowledge encoder对内容库的一个匹配能力,同时应用这两个能力来对实体名称进行定位的。
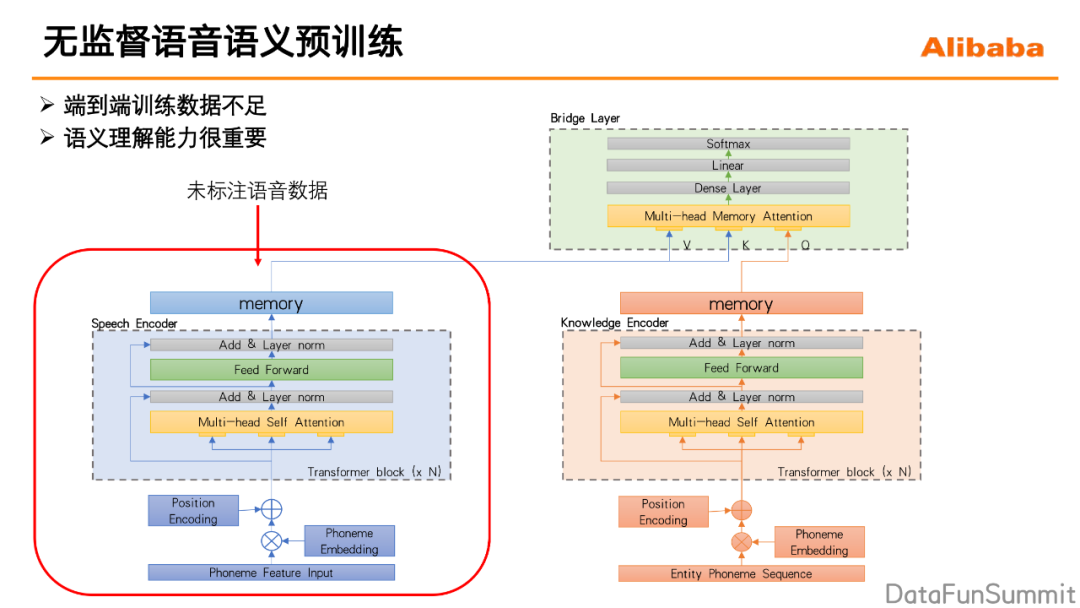
2. 如何进行语音语义的无监督预训练
具体的就是直接基于音素的后验,利用大量的无标签的语音数据来进行对于语音语义理解的这一模块进行预训练,之后这一个模块也能够快速地应用于语音语义理解模型里(分类任务、生成任务)的finetune。那么关于训练在文本领域其实已经有的大量的应用,比如BERT,通过随机的mask一些输入的token,然后去做一个预测,通过这种方式来进行预训练。那么我们的基于音素的无监督预训练也可以采用的类似的方式,我们提出Phoneme-BERT一种基于音素的无监督预训练方式。
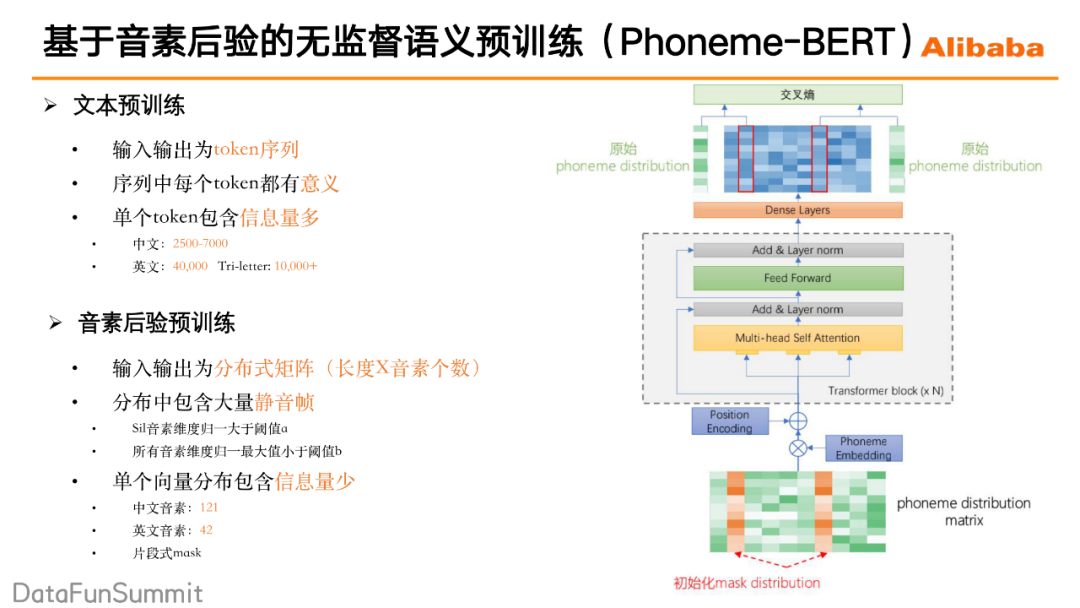
3. 文本预训练和音素后验预训练的区别
① 输入输出不同
文本预训练模型的输入输出都是token组成的序列,而在音素后验的模型当中,输入输出的是概率分布矩阵(音素后验矩阵)。因此,在mask操作时,Phoneme-BERT采用的方式是选取音素后验矩阵中任意的几帧,对相应帧上的整个概率分布进行mask,计算loss时将预测的概率分布和原始的被mask的概率分布进行一个交叉熵计算,通过这种方式来实现mask训练的过程。
② token含义不同
在文本预训练,序列中的每一个token都是有意义的,但是在音素后验矩阵当中却存在着大量无意义的静音帧。mask掉这些静音帧去做预测的话,给模型的学习带来很多噪声和困难。对此,我们采取的方案是通过概率分布筛选出静音帧,并在mask过程中对这些静音帧进行进行排除。
③ 单个token信息量不同
文本预训练中,每个token包含的信息量比较大,这是因为不管是中文词典或者是英文词典,规模都较大,所以每一个token包含的信息量都会比较多。而音素后验矩阵中单个向量包含的信息量会比较少,因为中文音素只有121个,然后英文音素的话只有42个。由于每一帧包含的信息量较少,这样随机mask后做训练的话,模型并不能真正得到语义能力的学习。对此,我们采用片段式的mask,通过这种方式使得在每一次mask的过程中可以去掉包含更多信息量的这些帧,然后使得整个无监督的预训练的效果会达到更好。
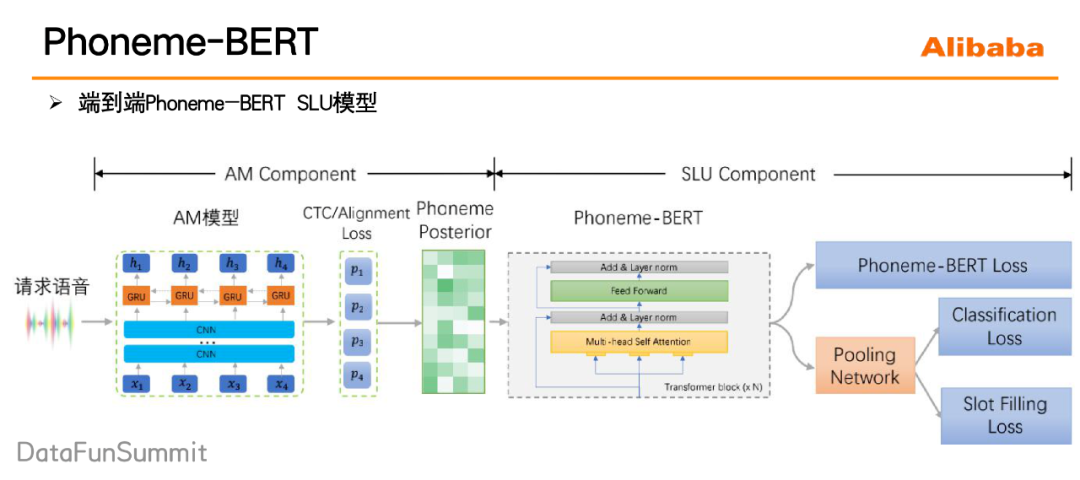
4. 应用流程
我们利用Phoneme-BERT对speech2slot中的speech encoder进行一个预训练,通过大规模无监督语料让speech encoder具备语音语义理解能力。预训练完成之后,我们再用少量标注数据对整个speech2slot进行端到端的finetune。Phoneme-BERT还可以应用于所有的端到端的语音语义理解模型(分类任务/生成任务)的预训练。
5. 实验结果
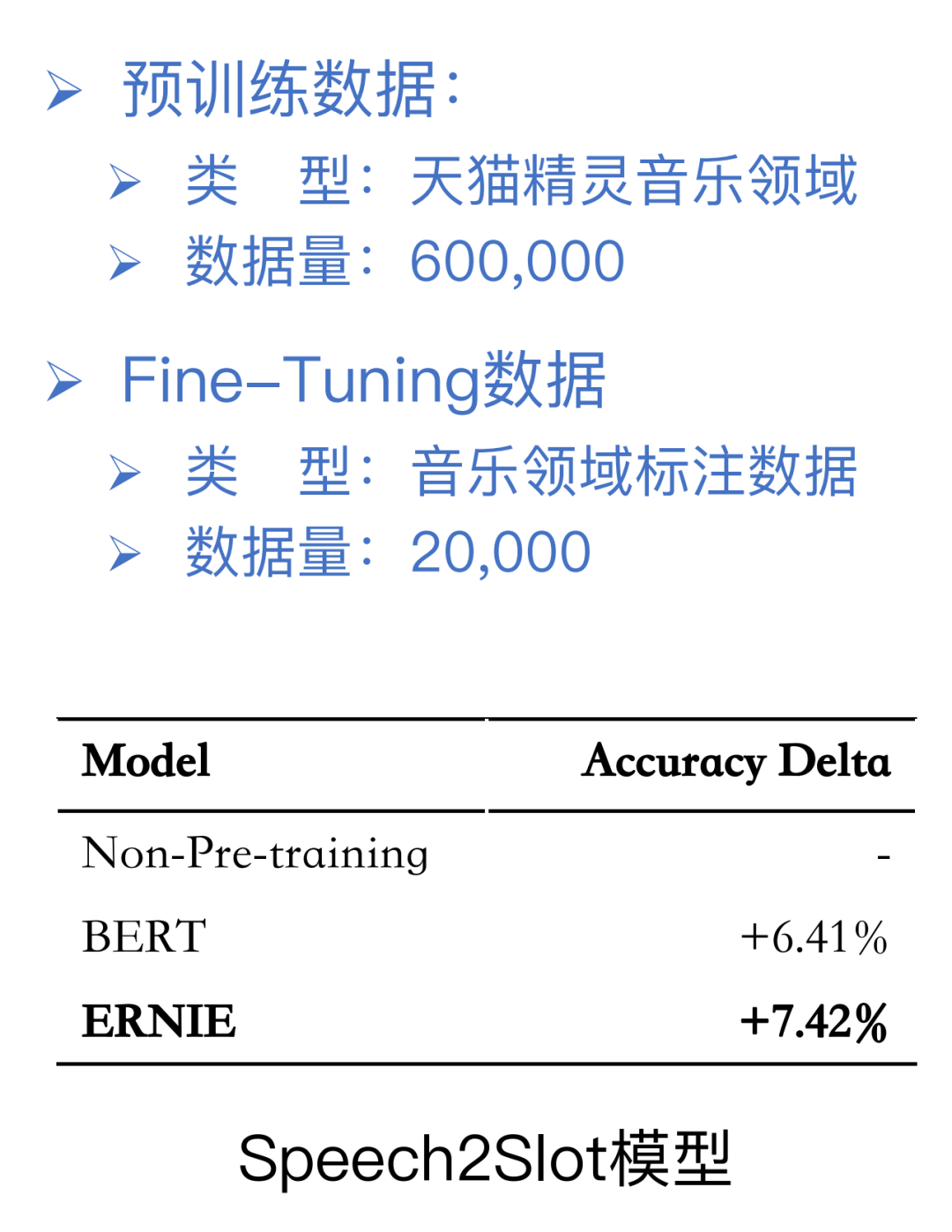
可以看到实验结果,不管是哪一种预训练的方式,都相比没有预训的方式能够得到更好的一个提升。
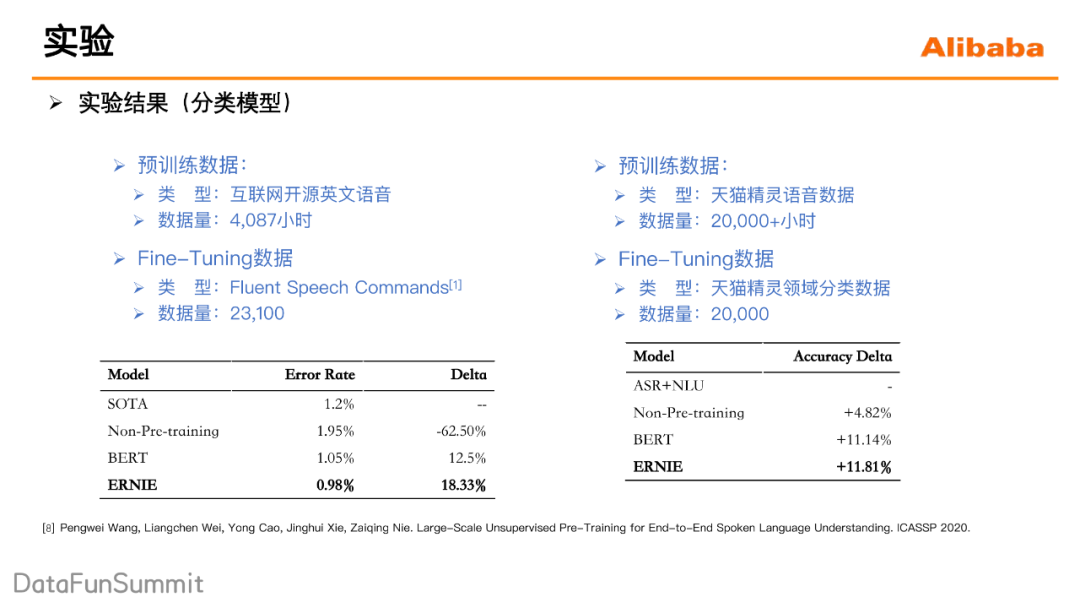
同时在分类模型上也分别做了实验,一个是在公开的数据集上做的一个实验:先用开公开的4000多小时的英文的语音数据,是对模型进行一个预训练,然后之后预训练好的模型,再去做一个领域分类任务,可以看到的,端到端的模型一开始在训练数据不足的情况下,相比于baseline错误率是还提高了,但是预训练之后,整个模型相比于之前的模型准确率是提升的。另外在天猫精灵的数据上也是得到了像一样的验证效果。
今天的分享就到这里,谢谢大家。
分享嘉宾:

OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。




