田渊栋从数学上证明ICLR最佳论文“彩票假设”,强化学习和NLP也适用

新智元报道
新智元报道
来源:Facebook AI
作者:Ari Morcos、田渊栋 编辑:肖琴
【新智元导读】ICLR 2019最佳论文提出的“彩票假设”能够将神经网络缩小10-100倍,而不损失性能。Facebook田渊栋团队的最新研究发现了第一个确定的证据,证明彩票假设在相关但截然不同的数据集中普遍存在,并可以扩展到强化学习和自然语言处理。你怎么看这一系列研究?来 新智元AI朋友圈 和AI大咖们一起讨论吧。
最初由MIT的研究人员Jonathan Frankle 和Michael Carbin 提出的彩票假设(lottery ticket hypothesis)表明,通过从“幸运”初始化(lucky initialization,通常被称为“中奖彩票”)开始训练深度神经网络,可以以最小的性能损失(甚至获得收益)将网络缩小10-100倍。
这项工作的意义令人兴奋,它不仅可能找到用更少的资源进行训练的方法,而且还可以在更小的设备(例如智能手机和VR头盔)上更快地运行模型推理。
但彩票假设尚未被AI社区完全理解。特别是,我们尚不清楚中奖彩票是取决于特定的因素,还是代表了DNN的一种固有特性。
Facebook AI的最新研究发现了第一个确定的证据,证明彩票假设在相关但截然不同的数据集中普遍存在,并可以扩展到强化学习(RL)和自然语言处理(NLP)。
Facebook AI的Ari Morcos和田渊栋是这一系列相关研究的其中两位作者,他们在最新博文中介绍了使用中奖彩票的实验结果和细节,并提出有关彩票形成的一个新理论框架,以帮助研究人员更好地理解幸运初始化。
什么是“中奖彩票”?
训练和压缩深度神经网络的标准方法包括调整神经网络中的数百万个参数,然后删除或“修剪”不必要的权重,以将网络结构缩减到更易于管理的大小。减小模型尺寸有助于最大程度地减小其内存、推理和计算需求。许多研究发现,经过训练的神经网络中的许多权重有时可以被削减多达99%,从而产生更小、更稀疏的网络。
彩票假设颠覆了DNN的修剪,其核心动机是:与其训练大型网络并将其削减为较小的网络,不如从一开始就确定并训练最优的小网络?
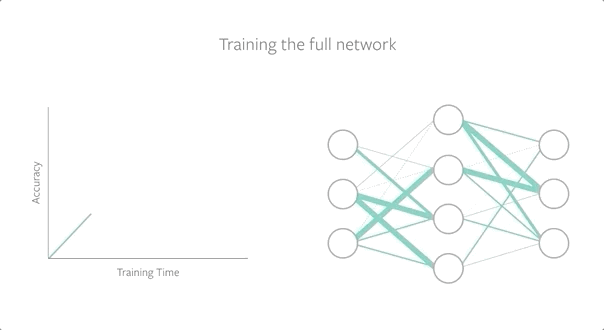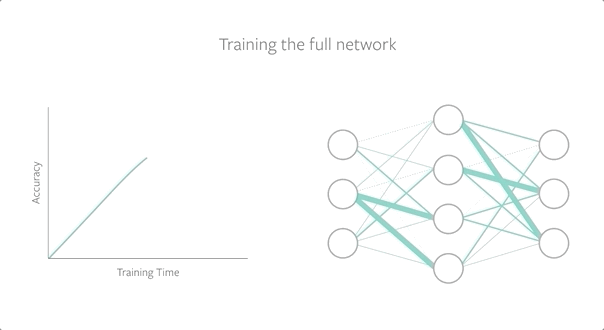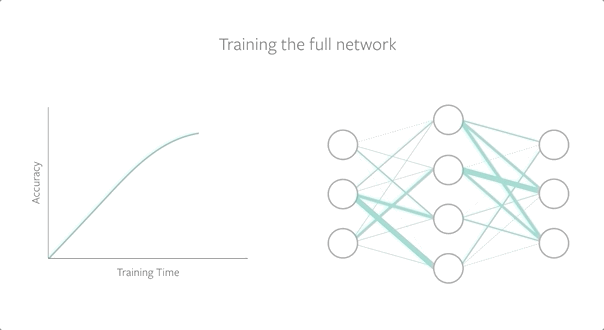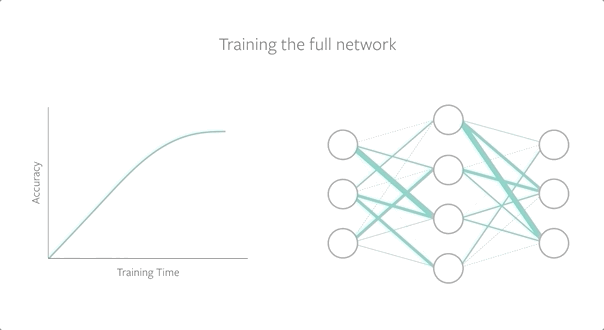
为了找到中奖彩票,我们使用随机初始化来训练一个完整的网络,在保留其性能的同时修剪模型,然后在训练开始前将子网络重置(或倒回)到初始化。为了评估中奖彩票,我们将它们与随机彩票进行比较,并发现中奖彩票(或幸运初始化)表现得更好。
随着网络规模的增大,我们组合地增加了可能的子网络的数量,这意味着存在一个幸运的子网络初始化的概率更高。彩票假设表明,如果我们能找到这个幸运的子网络,我们就能将小的、稀疏的网络训练到高性能,即使删除了整个网络90%以上的参数。然而,找到中奖彩票需要大量的计算资源,因为模型必须经过多次训练和再训练,这使得跨问题设置的泛化成为改进深度神经网络的一个关键标准。
跨数据集和优化器进行泛化
到目前为止,研究人员只是在原始研究论文中用于寻找中奖彩票的完全相同问题上测试了这一假设,部分原因是在新设置下寻找中奖彩票所需的计算能力太大。
在我们今年在NeurIPS上发表的论文“One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers”中,我们评估了6个不同的自然图像数据集和优化器中彩票初始化的通用性。令人鼓舞的是,我们发现中奖彩票普遍适用于相关但不同的数据集。类似地,我们还发现中奖彩票在不同的优化器中都是通用的,这表明中奖彩票初始化在很大程度上是与优化器无关的。

论文地址:
https://arxiv.org/pdf/1906.02773.pdf
为了度量中奖彩票的通用性,我们在一个源训练配置中生成中奖彩票,并在不同的目标配置中评估性能。例如,我们可以使用CIFAR-10数据集(源配置)生成中奖彩票,并在ImageNet数据集(目标配置)上评估它的性能。通过一系列不同设置的严格实验,我们观察到中奖彩票在不同的图像数据集上可以泛化。有趣的是,我们还观察到,由大型数据集(如ImageNet和Places365)生成的中奖彩票的迁移效果始终比小数据集(如CIFAR-10)好得多。
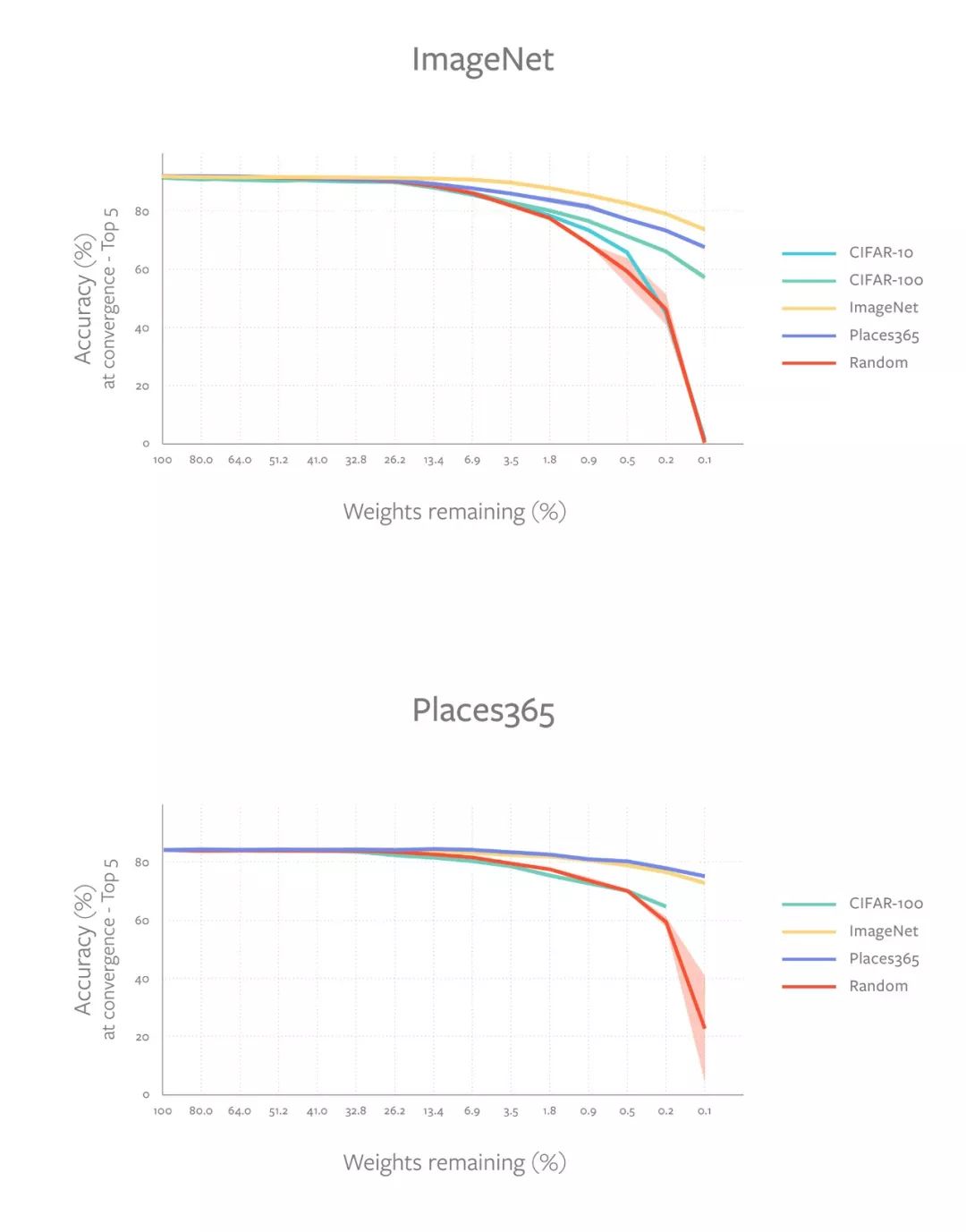
这些图显示了物体分类模型的中奖彩票是如何跨越大型数据集(ImageNet和Places365)和小型数据集(CIFAR-10/CIFAR-100)的。图中不同的线代表中奖彩票的不同源数据集。在ImageNet和Places365上生成的中奖彩票始终优于在较小数据集上生成的中奖彩票。
这些结果表明,与较小的数据集相比,较大的数据集会鼓励更多的通用中奖彩票。我们还发现,在相同数量的训练示例(但类别数量不同)的数据集上生成的中奖彩票的表现也有所不同。类别更多似乎就可以更好地泛化(例如,比较CIFAR-10和CIFAR-100中奖彩票的性能,它们分别有10个类和100个类)。
这项研究表明,无论确切的问题是什么,中奖彩票都包含有改善深度神经网络训练的一般属性。这样就有可能产生少量这样的中奖彩票,并在不同的任务和环境中使用它们进行更有效的训练。(要了解更多细节,请阅读论文:One ticket to win them all: Generalizing lottery ticket initializations across data sets and optimizers)。
推广到其他领域和其他学习方法:强化学习和NLP
到目前为止,彩票现象只在以视觉为中心的分类任务这样的监督学习环境中进行了测试,这留下了一个关键的开放性问题——它们是否只存在于监督学习方法中,或者仅是图像分类领域的一个巧合?如果彩票现象代表了DNN的基本属性,那么中奖彩票应该出现在各种不同的领域和学习环境中。
在最近的论文“Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP”中,我们研究了这些问题,发现彩票现象也存在于强化学习(RL)和自然语言处理(NLP)领域。对于RL,我们分析了一组经典的控制任务和Atari游戏;对于NLP,我们研究了经典的长短时记忆(LSTM)语言模型和最近的为机器翻译训练的Transformer模型。
我们关注的任务与最初用于图像分类和监督学习的范例和架构有很大的不同。例如,在RL中,数据分布会随着智能体从稀疏的奖励信号中学习而发生变化,这显著地修改了优化过程和生成的网络。在NLP任务中,DNN需要对时间动态进行建模,而这在有监督的图像分类中是不存在的。

论文地址:
https://arxiv.org/pdf/1906.02768.pdf
与之前的监督图像分类的工作一致,我们证实了在RL和NLP问题中,中奖彩票的表现也优于标准随机子网络初始化,即使在极端的剪枝率下也是如此。对于RL,我们发现在经典控制问题和许多(但不是全部) Atari游戏中,中奖彩票的表现远远好于随机彩票。
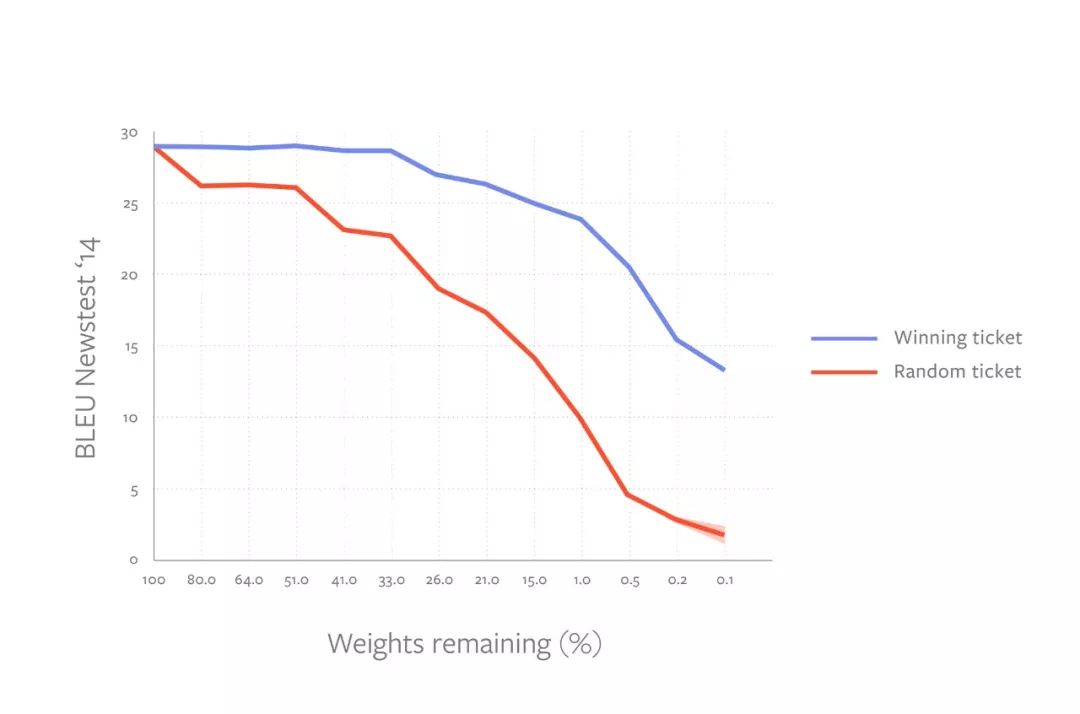
为机器翻译任务训练的Transformer 模型的中奖票初始化性能
对于NLP模型,我们发现在语言建模任务训练的LSTM和机器翻译任务训练的Transformer中都存在中奖彩票。令人惊讶的是,我们发现拥有超过2亿个参数的超大型Transformer模型可以从零开始训练到接近等效的性能,而只剩下三分之一的权重。这一结果表明,我们有可能从头开始构建和训练基于注意力的语言模型,这些模型被大大简化,足以适应小型设备。
总之,这些结果表明彩票现象并仅仅是图像分类的产物,而是代表了深度神经网络(DNN)这个广泛领域的一种现象。(关于这些实验的详细信息,请阅读论文:Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP。)
进一步加深对“中奖彩票”的理解
这些研究有助于证明彩票可以在原始研究论文的确切条件之外存在,这为我们加深对幸运初始化的理解提供了更多的激励。然而,还有很多关于神经网络的潜在属性和行为的开放性问题,比如这些中奖彩票是如何形成的,它们为什么存在,它们是如何工作的?
为了在深层ReLU网络的背景下开始分析这些问题,我们使用了一个“学生-教师”的设置,在这个设置中,一个较大的学生网络必须学会准确地模仿较小的教师网络正在做的事情。由于我们可以在此设置中定义具有固定参数的教师网络,因此我们可以定量地测量学生网络的学习进度,并且,对于我们的彩票研究来说,了解学生网络的初始化如何影响学习过程是至关重要的。
在“学生-教师”设置下的研究中,我们发现,经过训练后,被挑选出来的学生神经元的活动模式与教师神经元的活动模式之间的相关性比与其他学生神经元的活动之间的相关性更强——这一概念被称为“学生专业化”(student specialization)。这种更强的相关性表明,在训练期间,学生网络不仅学习教师的网络输出,而且可以通过模仿个别老师的神经元来学习教师网络的内部结构。
在论文“Luck Matters: Understanding Training Dynamics of Deep ReLU Networks”的分析中,我们发现这种现象发生在一个2层的ReLU网络中:如果一个学生神经元的初始权重碰巧与某些教师神经元的权重相似,那么就会出现专门化。神经网络的大小很重要,因为学生网络越大,越有可能存在一个学生神经元与教师神经元的距离很接近,从而在训练中模仿教师神经元的活动。更重要的是,如果一个学生神经元的初始激活区域与一个教师神经元有更多的重叠,那么这个学生神经元的就会更快地专业化。这一行为证实了彩票假设,该假设同样提出,在神经网络中存在一些幸运的初始化子集,“中奖彩票”就是幸运的学生神经元,它们恰好在训练开始时处于正确的位置。

论文地址:
https://arxiv.org/pdf/1905.13405.pdf
在我们的后续研究论文“Student Specialization in Deep ReLU Networks With Finite Width and Input Dimension”中,我们通过消除多种数学假设(包括独立激活和局部性)来强化我们的结果,并且仍然证明了学生专业化在经过训练后发生在深层ReLU网络的最底层。从我们的分析中,我们发现训练动态中的某些数学性质与彩票现象产生了共鸣:那些在初始化时具有轻微优势的权重,在训练收敛后成为中奖彩票的可能性更大。

论文地址:
https://arxiv.org/pdf/1909.13458.pdf
通过这个“教师-学生”范式,我们已经能够从数学上证明幸运初始化的彩票行为——超出了经验实验。
彩票假设的未来和开放性问题
彩票假设是一个令人兴奋且潜力巨大的视角,通过它我们可以更好地理解和改善DNN。
通过这一系列的研究和理论分析,我们证明了彩票效应可以发生在各种不同的领域,中奖彩票的初始化能够在相关但不同的数据集进行泛化,以及更一般的意义上,他们比先前研究人员所理解的更有潜力。如果我们能找到一种方法,从一开始就识别出中奖彩票,那么我们不仅可以用今天所使用的计算资源的一小部分来构建强大的深度学习系统,而且还可以使用这些技术来提高当前的大型网络的性能。
虽然我们的研究已经证明了彩票假设的普遍性,并且我们的理论框架有助于更具体地证实这一现象,但这是一个活跃的研究领域,有许多问题仍然没有得到解答。中奖彩票是依赖于标签还是仅仅依赖于数据分布?如何更有效地生成中奖彩票?是否有可能在不同的架构之间迁移中奖彩票?也许最有趣的是,是什么让中奖彩票如此特别?我们希望这些工作将推动我们的团队和其他人今后的研究,探讨这些悬而未决的问题。
原文链接:
https://ai.facebook.com/blog/understanding-the-generalization-of-lottery-tickets-in-neural-networks






