你知道该如何搭建 AI 智能问答系统吗?


作者 | 李秋键
责编 | 刘静
出品 | CSDN(ID:CSDNnews)
今天我们将利用分词处理以及搜索引擎搭建一个智能问答系统,具体的效果如下所示:
下面简单了解下智能问答系统和自然语言处理的概念,智能问答系统是自然语言处理的一个重要分支。现在普遍认为智能问答能够独立解决很多问题,但是必须要承认现在技术所处的初级阶段的性质。也就是说,智能问答系统在现阶段最大的价值在于为客服人员附能,而并非独立于人自行解决众多目前还有巨大错误率和不确定性的问题。一旦具有这样的思想基础——通过智能问答系统为客服人员附能,那么将智能问答系统做成一个工具和产品的基础就有了,只有通过产品化、工具化的方式,才能够实现这个预期。
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
下面开始搭建我们的智能问答系统,首先我们需要 导入的库:
import requests
from lxml import etree
import jieba
import re
import sys,time
import os
我们知道一个真正的语言回答应该是逐字回答的才符合人的回答习惯,下面为了达到语言对话的效果,我们定义一个函数:
def print_one_by_one(text):
sys.stdout.write("\r " + " " * 60 + "\r") # /r 光标回到行首
sys.stdout.flush() #把缓冲区全部输出
for c in text:
sys.stdout.write(c)
sys.stdout.flush()
time.sleep(0.1)
下面是真正搭建的部分,为了对语言进行处理,首先我们要加载停用词,去除掉语言中无意义的词,比如“了”,“啊”等等:
stop = [line.strip() for line in open('stopwords.txt',encoding='utf-8').readlines() ]
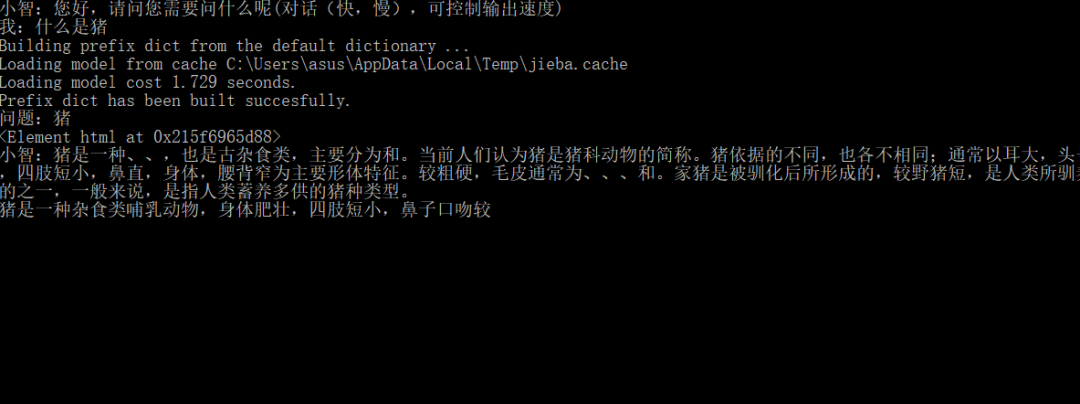
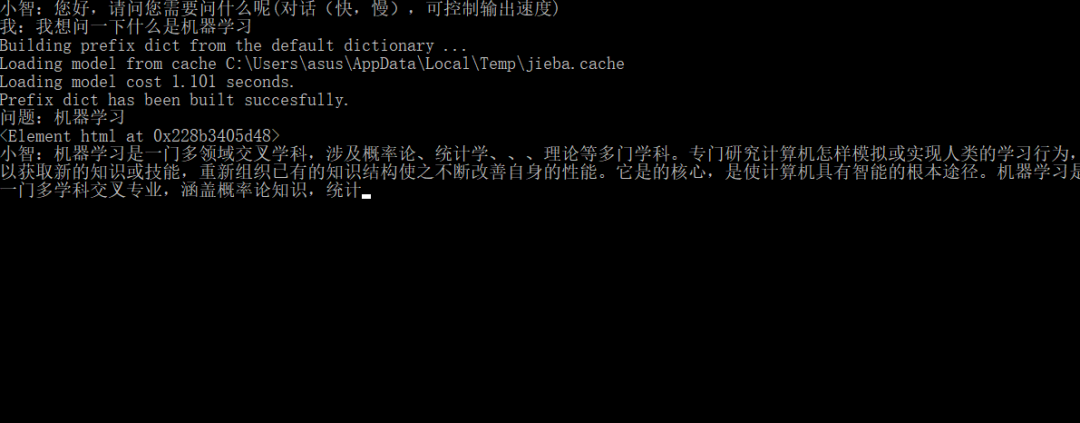
print("小智:您好,请问您需要问什么呢(对话(快,慢),可控制输出速度)")
input_word=input("我:")
#默认为慢速
#print(input_word)
if input_word == "快":
f = open("1.txt", "w")
f.write("0")
f.close()
elif input_word =='慢':
f = open("1.txt", "w")
f.write("1")
f.close()
sd=jieba.cut(input_word,cut_all=False)
final=''
for seg in sd:
#去停用词
#print(seg)
if seg not in stop :
final +=seg
process=final
#匹配问后面全部内容
pat=re.compile(r'(.*?)问(.*)')
#一个“问”时的处理
try:
rel=pat.findall(final)
process=rel[0][1]
except:
pass
#两个问时的处理
try:
rel=pat.findall(final)
rel0=rel[0][1]
#print(rel0)
rel1=pat.findall(rel0)
process=rel1[0][1]
except:
pass
print("问题:"+process)
if process=='':
print("小智:OK")
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url=requests.get("https://baike.baidu.com/search/word?word="+process,headers=header)
#为了防止中文乱码,编码使用原网页编码
url.raise_for_status()
url.encoding = url.apparent_encoding
bject=etree.HTML(url.text)
print(object)
#正则匹配搜索出来答案的所有网址
#获取词条
#head =object.xpath('/html/head//meta[@name="description"]/@content')
#详细内容
para=object.xpath('/html/body//div[@class="para"]/text()')
result='小智:'
for i in para:
result+=i
if result=='小智:':
print("小智:对不起,我不知道")
else:
f = open("1.txt", "r")
s=f.read()
if s=="1":
print_one_by_one(result)
else:
print(result)
while(True):
if os.path.exists('1.txt'):
chuli()
else:
f = open("1.txt", "w")
f.write("1")
f.close()
chuli()
那么让我们再接着了解自然语言处理的发展历程吧,最先的语义解读各个方面的研究是自然语言。1949年,非裔威弗首先明确提出了自然语言方案。20世纪60八十年代,外国对自然语言曾有大规模的研究,花费了巨额开销,但人们以前似乎是高估了语义的复杂度,语法处置的学说和新技术皆不成冷,所以成果并不大。主要的作法是储存两种语法的单字、单词相同译名的辞典,翻译成时双射,新技术上只是变更语法的同条次序。但现实生活中的语法的翻译成近不是如此非常简单,很多时候还要参照某句话前后的意即。
约90八十年代开始,语义处置各个领域再次发生了极大的变动。这种变动的两个显著的特点是:
(1)系统对输出,拒绝研发的语义处置该系统能处置大规模的现实文档,而不是如现在的学术性该系统那样,不能处置极少的词典和类似于字词。只有这样,研发的该系统才有确实的实用性。
(2)系统对的输入,鉴于现实地解读语义是难于的,系统对非常拒绝能对语义文档展开深层的解读,但要能借此提取简单的数据。例如,对语义文档展开系统会地萃取目录词语,过滤器,索引,系统会萃取最重要数据,展开系统会概要等等。
同时,由于特别强调了"大规模",特别强调了"现实语料",上面两各个方面的开拓性管理工作也获得了推崇和强化。
(1)大规模现实语料的研发。大规模的经过有所不同深度加工的现实文档的语料,是研究工作语义统计资料物理性质的根基。没它们,统计资料方式不能是无源之水。
(2)大规模、数据非常丰富的字典的编制工作。数量为几万,十几万,甚至几十万词语,所含非常丰富的数据(如包括词语的配上数据)的计算机系统能用字典对语义处置的必要性是很显著的
作者简介:李秋键,CSDN 博客专家,CSDN达人课作者。
声明:本文为作者原创投稿,未经允许请勿转载。
【END】

热 文 推 荐
☞这款“狗屁不通”文章生成器火了,效果确实比GPT 2差太远
☞CSDN应邀赴微软IT大会,揭开微软重磅推出的秘密武器——Azure区块链代币平台的神秘面纱!





