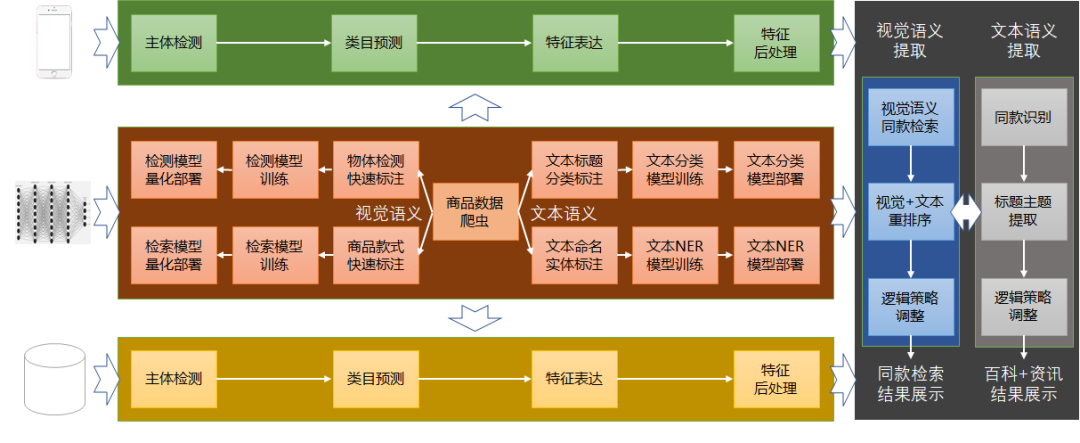
微信AI的高性能检测器,让识图更精准

导语
一、物体检测的作用及难点
(1)注意力问题:为了优化扫一扫识物体验,我们需要检测的物体是用户视觉中心关心的物体,减少用户不必要的交互操作;
(2)开集检测问题:适配用户任意输入请求(可能是从未见过的子类目);
(3)标注成本问题:项目落地中物体检测的标注时间和金钱成本不容忽视;
(4)多源异构性问题:这是最具挑战的一点,我们多说一句。多源性是指我们检测器需要处理不同来源的数据,如室内嘈杂的办公桌,室外空旷的草地,用户随手上传的街拍数据,卖家精心评测自家的电商数据,不同来源的数据在光线、清晰度、尺度、视角都变化巨大;异构性则是根据我们对不同垂类的定位和检索要求来定义的,如电商、汽车、动物我们一般要求框图是物体明显的边界;而植物、地标和菜品通常有可能是边界模糊,需要涵盖绿叶、背景和器皿;红酒我们主要定位是酒标而不是酒瓶(酒标对红酒的识别更具判别性),名画我们定位的是画作本身而不是相框(很多画作不带相框),商标主要定位图案logo(纯文字logo由OCR来完成,暂时还未上线),作业检测的目的是切分不同的题目(不同学科如英语,数学题目的定义差异巨大,不像电商等垂类有明确的主体概念),结构迥异的垂类也就带来了更加严峻的困难样本检测问题、长尾检测问题,以及模型收敛问题,参考图1.2;
(5)隐私、传输流量和并发问题:对于用户隐私图片如账单等图片自动判别不进行后续识图操作,对用户高清图快速定位显著区域并抠图,减少流量处理,以及部署模型的精度和速度折中问题。

二、物体检测在学术界的发展进程回顾
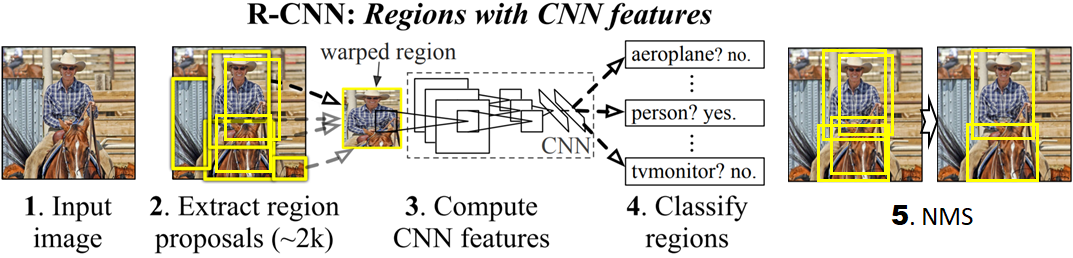
1) 输入是基于传统Selective Search得到的候选proposals;
2) backbone采用当时主流的AlexNet/VGG16等模型;
3) 由于输入是proposal,直接复用分类任务设计的网络,无neck设计;
4) 可以理解为典型的两阶段算法,先得到候选位置,再对候选位置进行分类和校准;
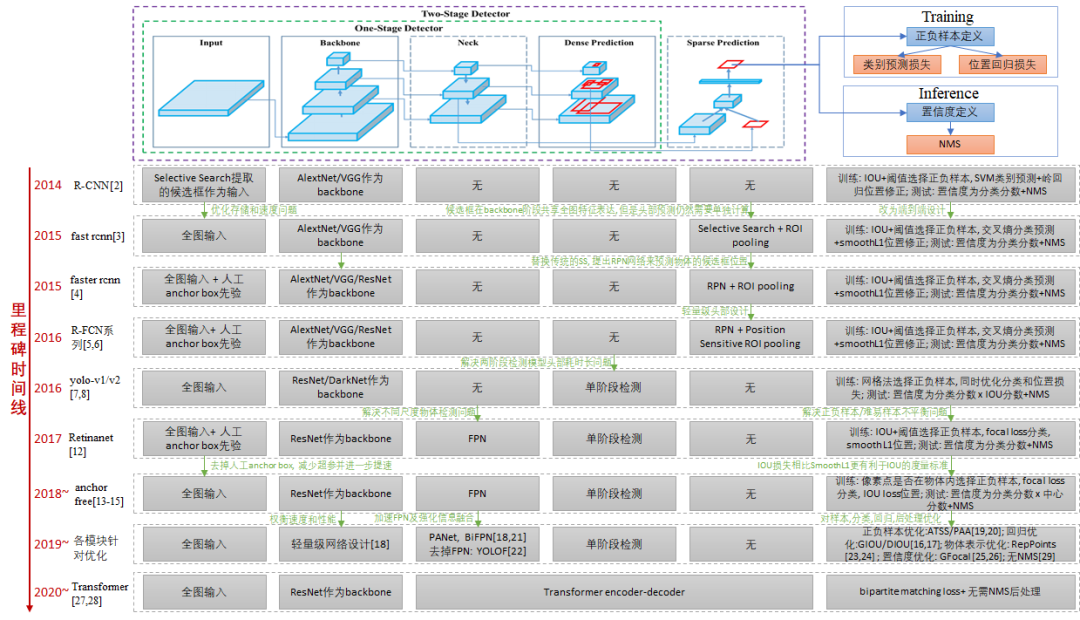
5) 依赖NMS等后处理输出最终的检测结果。后续的物体检测算法基本都是对该框架的各个模块进行改进和优化,我们借鉴yolov4的框架图来对目前主流的物体检测算法进行了归纳和串联,如下图2.2所示。这里不再对每种改进的细节进行赘述,大家感兴趣可以找原文或者文章解读进行细致的了解。
(1)学术上物体检测评测指标关注召回图片上所有物体(所有位置所有尺度的物体)以及检测框的重合度,而我们实际落地更关心用户视觉中心感兴趣物体的定位和识别精度。
(2)学术上物体检测大都面向闭集问题,即训练集中物体类目和测试集物体类目一致,而我们实际落地需求面向的是开集问题,需要处理用户任意输入请求(很多从未见过的子类目)。
(3)学术上物体检测不需要考虑标注成本问题(直接采用开源已经标注好的数据库就行),而我们需要快速支持业务端新增加的各种垂类识别请求。
(4)学术上检测数据库基本拍摄风格较为一致,而我们面对的是电商、植物、动物、汽车、酒标、菜品、地标、商标、切题等多源异构的数据,对模型的泛化性要求更高。
(5)学术上物体检测大都不需要考虑隐私、传输带宽和并发量问题,而我们服务于微信的海量用户,需要充分考虑隐私图片禁止识别,以及传输带宽和高并发问题。
三、面向多源异构数据的物体检测模型
3.1 检测器整体架构
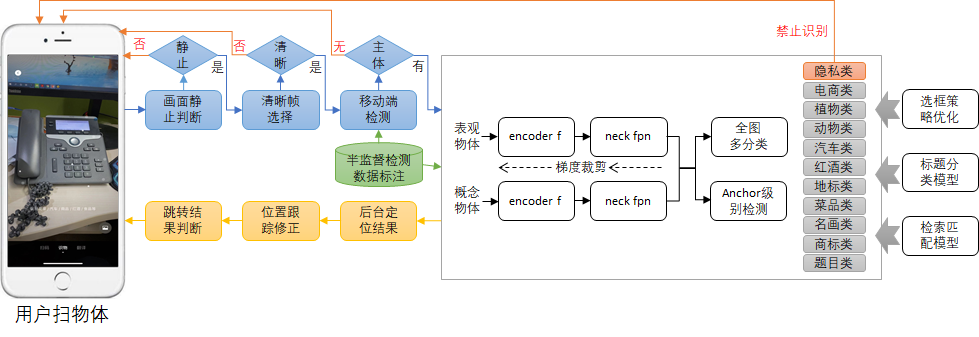
3.2 检测数据标注
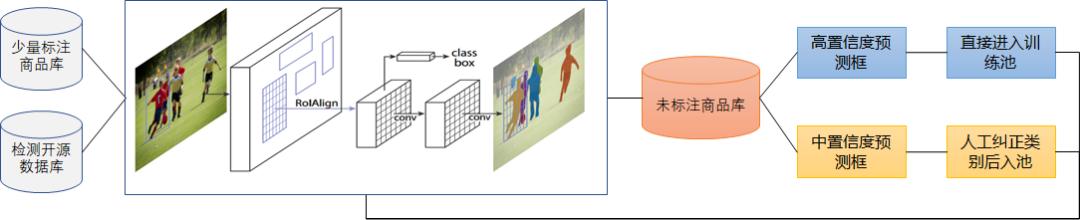
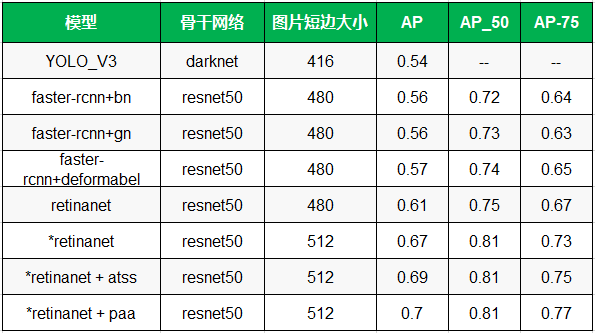
3.3 移动端快速检测
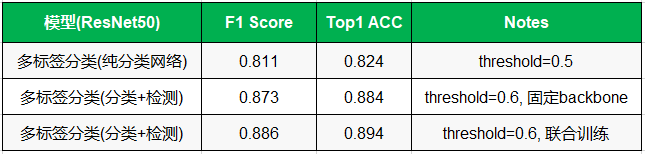
3.4 多标签分类识别
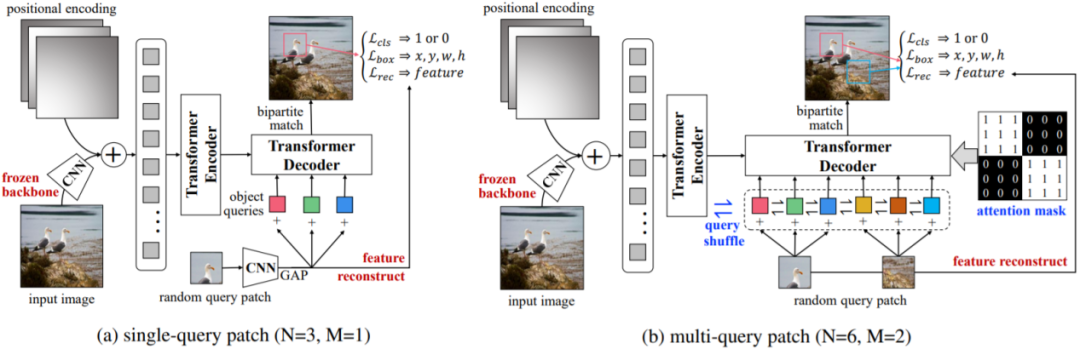
3.5 具有表观一致性的物体定位和识别
3.6 无表观一致性的概念体定位和识别
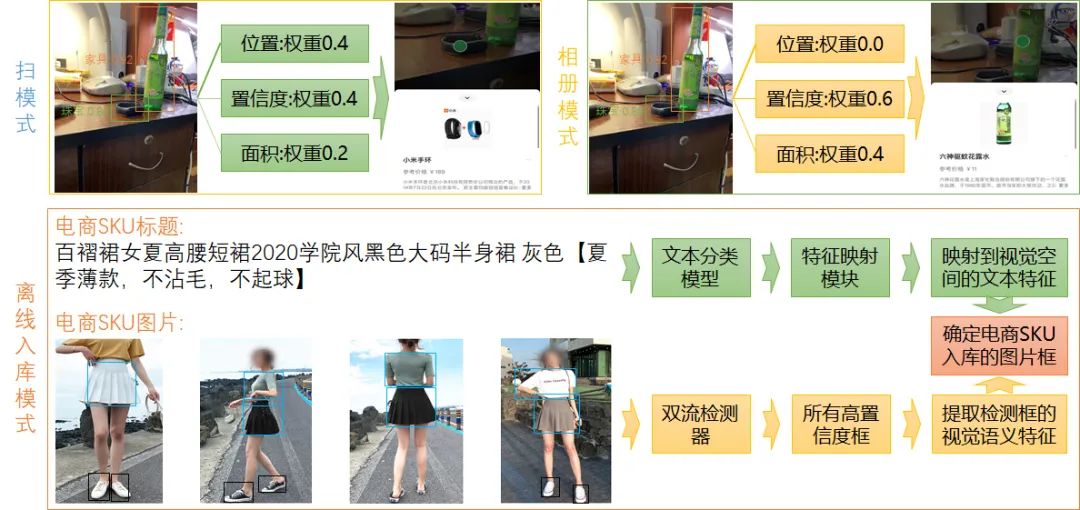
3.7 选框策略及类目预测
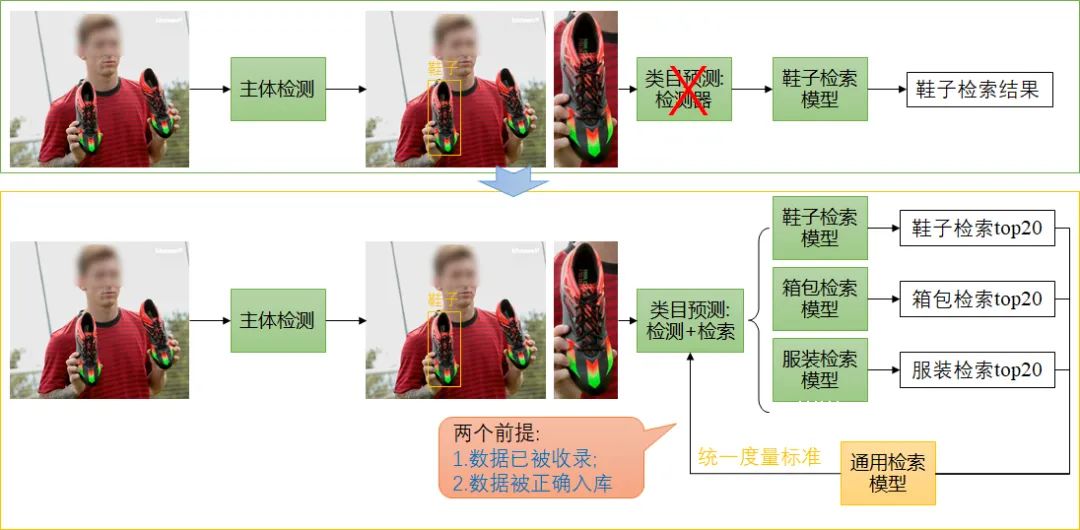
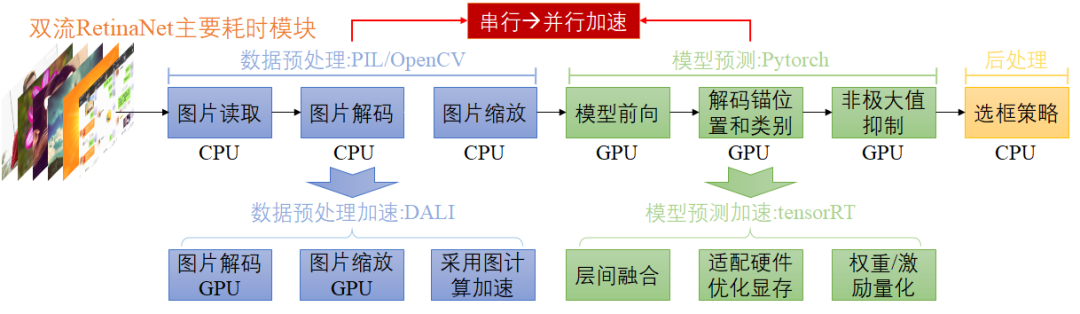
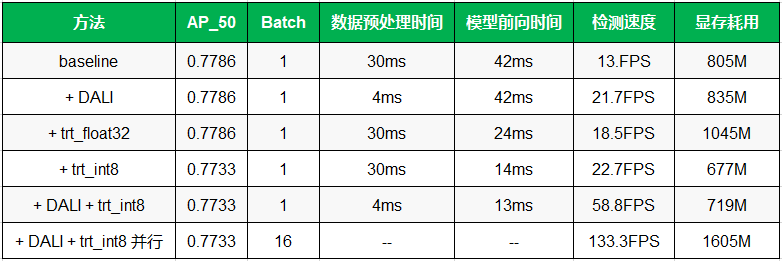
3.8 模型部署和加速
四、总结和展望
五、参考文献
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。



