机器人健忘症的福音——对话系统上下文
戳上面的蓝字关注我们哦! 
媒体盛传 2016 年是人工智能元年,语音、图像、自然语言处理中一大批研究成果正从实验室逐步走进公众的日常生活。对话系统(又称 dialog system )作为人工智能在 NLP 领域最难的问题,获得了工业界及学术界的火热的关注。从 apple 的 siri 到 facebook 的 M ,到目前火爆的亚马逊的 echo ,最新潮的高科技公司都在对话系统上开疆扩土,试图摘取 AI 这顶皇冠。微信作为领先的社交网络,也在探索自己的对话平台,向普通用户提供快速搭建垂直服务与闲聊机器人的能力。
网上经常见到人们调戏聊天机器人的段子。究其原因,还是在于当前对话系统的智能水平,尤其是在开放场景下自由对话(俗称闲聊)的能力,有待提高。都说金鱼的记忆只有7秒,而闲聊机器人的记忆常常只有一轮,这往往导致人们觉得闲聊机器人十分笨拙、不通人性。本文将围绕开放领域对话中的上下文问题展开讨论。
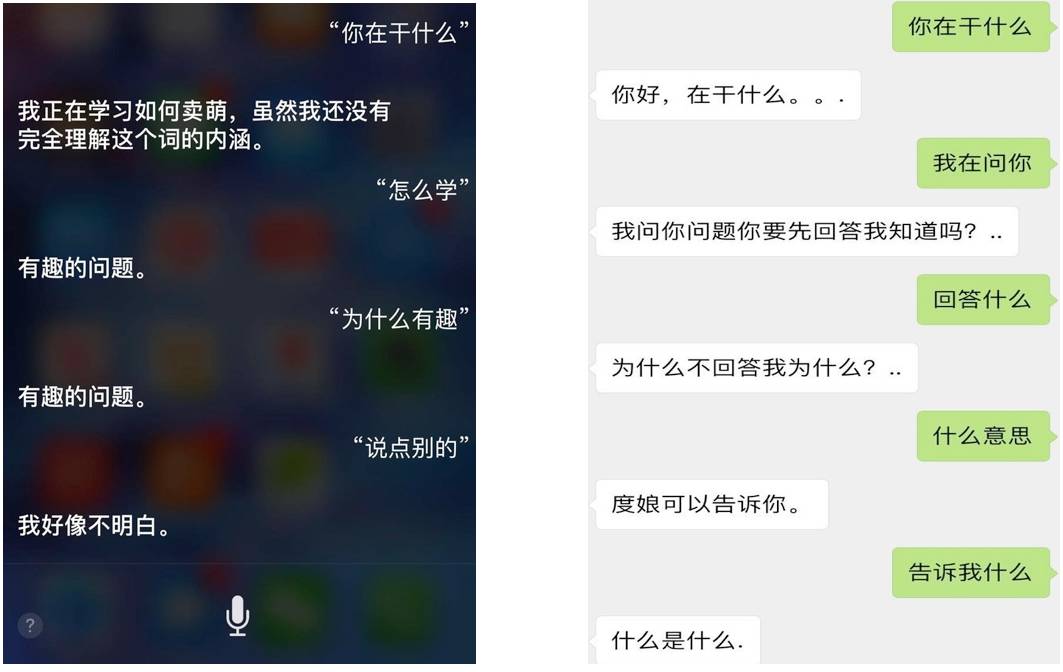
图 1:常见对话系统多轮聊天示例
看完上面这段对话,想来大家跟笔者的心情是一样的。

众所周知,上下文能力是对话系统智能化的瓶颈之一,然而业界至今尚无较好的解决方案。其难点首先在于大家对于对话上下文问题只有感性认知,没有清晰的形式化定义。通过调研分析,我们将开放聊天场景中的上下文表达方法分为隐式表达和显示表达两大类。
隐式表达指的是通过建立多轮上下文对话模型,将上下文编码成一个隐层向量,进一步进行答案搜索或生成。其缺点在于错误难跟踪,结果难解释,毕竟高维向量对于人类而言还是太过抽象了一些。来一个,大家感受下:
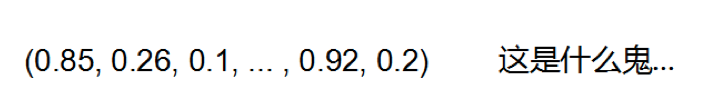
显示表达指将上下文信息加入当前 query ,形成人可以直观理解的 query 。显示表达又可以分为补词和上下文改写两个类型。上下文补词技术基于如下假设,即核心词可视为上文 topic 在词汇级别的表征,传递核心词可增强聊天场景的主题连贯性。其优点在于简单易行,结果直观;当然缺点也较明显,因为直接补词会破坏语义的连贯性,时常会给大家带来“ xx 病人思维广,xx 儿童欢乐多”的乱入感。
我们采用的是上下文改写技术,将上下文与当前 query 改写为完整意思的一句话,从而将多轮对话转成单轮对话进行解决。这个与我们人对话过程是一致的,我们人在对话中,不管前面说了多少,实际上也是先理解到目前为止,对方要表达的完整意思是什么,然后再回答。该方法既保留了语句的直观性,同时也保证了语义的连贯性,还盘活了单轮对话中各种成熟的搜索技术,给健忘的机器人插上了短时记忆的翅膀。
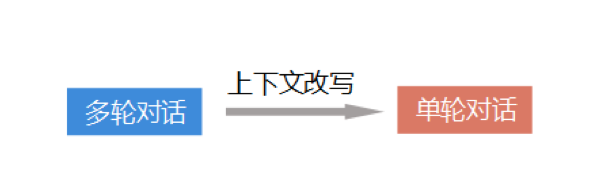
图 2:上下文问题抽象定义
使用该方法构造的聊天机器人对话示例如下:
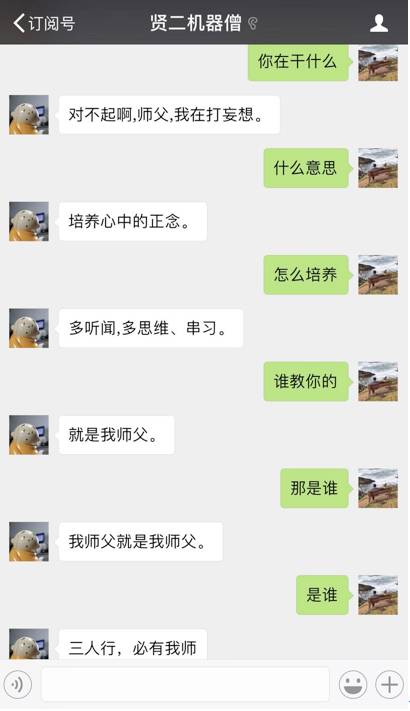
可以看到,对话的流畅程度和逻辑性较单轮对话系统是有所提升的。妈妈再也不用担心我的记忆力了。那么....

具体而言,我们在上下文相关类别的情况进行上下文改写。通过数据分析,我们发现指代与省略是对话中经常出现的现象。我们采用排序模型对指代消解问题进行求解;采用翻译模型对上下文补全问题进行求解。以下将分别进行介绍。
指代消解——从此认识你我他
我们首先来聊聊指代消解。指代消解指的是将当前 query 中的“他、她、这、那”等人称代词、地点代词替换为前文某一个人名或地名。
举一个例子:
用户:你是陈奕迅的粉丝吗?
机器人:更喜欢张学友
用户:为什么更喜欢他?
指代消解的目的就是将“为什么更喜欢他”改写为“为什么更喜欢张学友”。形式化定义如下:
q’=H(q|C)
输入中,C 是上下文信息,即前几轮的对话,q 是当前的查询,输出 q’ 是指代消解后,无歧义的查询,其中 H 的作用是将 q 中的指示代词 (人称、地点) 替换为 C 中的某一实体词。
我们将指代消解抽象为一个排序问题,其目的就是要选出概率更大的人名,替换当前 query 里的人称代词“他”。我们受大热的机器阅读理解的启发,使用双向 RNN ,对其编码并计算不同候选词与当前 query 的相似度。

好吧,简单的说,这个算法的核心在于“更喜欢他”与“更喜欢张学友”更相似,所以可以将“他”替换为“张学友”。来让我们看一看怎么用一个炫酷的模型来描述上面这句简单的话。
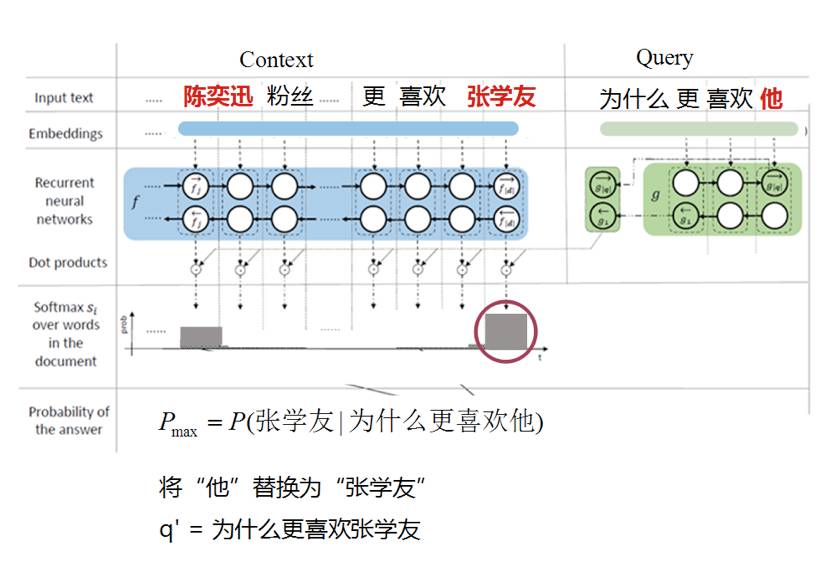
图 4:指代消解模型
该方法能较好的解决将候选词替换为一个实体词的情况,图5 是一些指代消解的例子。跟机器人交流终于不用每次都输入完整的话了,懒癌患者松了一口气。
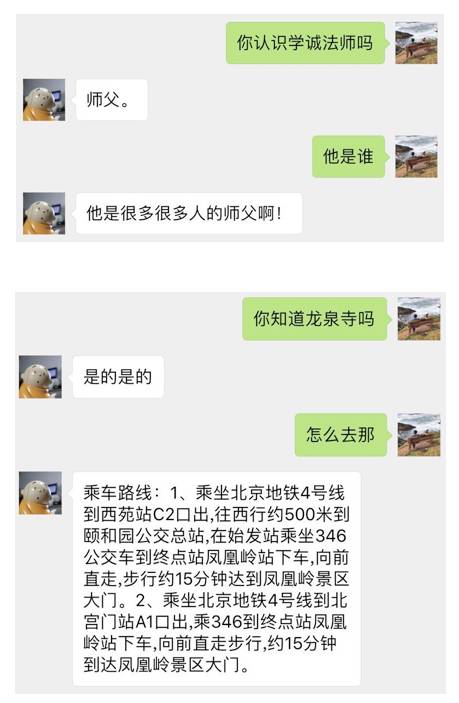
图 5:指代消解示例
上下文补全--放心使用省略句
接着我们来谈一下如何完成上下文补全。上下文补全指的是抽取上文中的一些词或短语,加入当前 query ,形成一句流畅无歧义的 query ,从而将多轮对话压缩为单轮对话。
例如:
用户:讲个故事给我听
机器人:等我学会了给你讲哦。
用户:我等着
上下文补全的目的就是将“我等着”,根据上文改写为“我等着听故事”。
我们将该问题抽象为翻译模型,对于刚才的例子而言,我们可以将多轮对话视为一种表述繁杂的语言 A ,而我们的目标是将其翻译为表达简洁紧凑的语言 B 。模型结构如 图6 所示。
需要注意的是,此处使用翻译模型与对话系统中直接由上一句生成下一句是有较大不同的。对于对话系统而言,任意一个问句,其答句的语义空间非常大,可生成的回复也就非常多,用人话说就是多种回答都有道理。在上下文补全任务上,相当于是在进行同义改写,其语义空间是固定的,从理论上说,改写结果应该是一定的。
我们使用了近年来非常流行的 encoder-decoder 架构对翻译问题进行端到端的建模,可以自动根据上文与当前有歧义的 query ,生成语意完整的 query 。该框架中,encoder 部分我们使用双向 LSTM 对输入进行编码,该编码器的作用在于可以将整句话的语义包含在一个向量中,同时突出当前字所携带的信息;decoder 使用 RNN 进行 query 生成,此处 RNN 相当于在对条件概率进行建模,可以综合已经生成的部分 query 以及当前隐状态,计算下一个要生成的字的概率分布。同时为了加强上文中相关词对生成完整 query 的影响,我们采用 attention 机制来建模人缩句时注意力的分布,加强关键部分的影响,减弱无关信息的影响。在 图6 所示的例子中,注意力会停留在“故事”和“听”上。
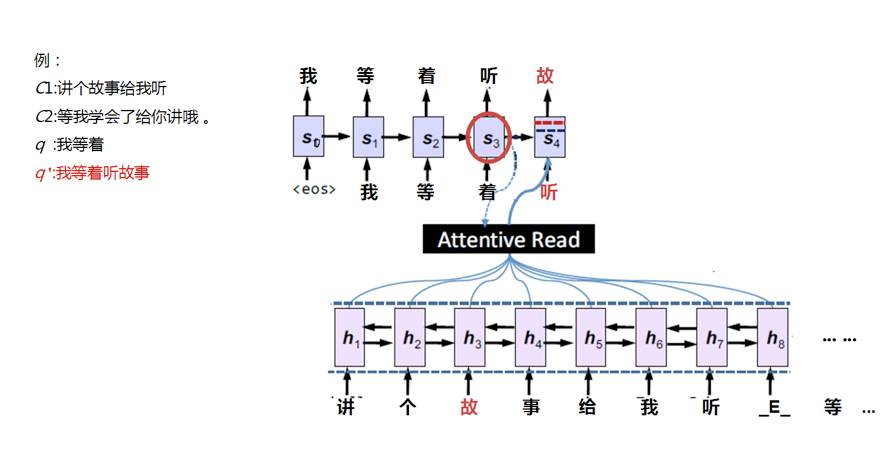
图 6:上下文补全模型
通过以上方法构造训练的补全模型,可以有效提高对话的连贯性,从 图7 中,我们不难发现,机器人的健忘情况,在上下文补全的帮助下,有了一定的缓解。不过,药不能停。
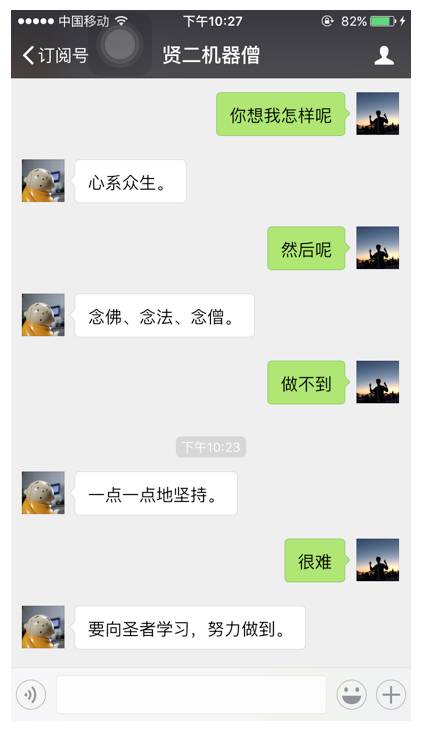
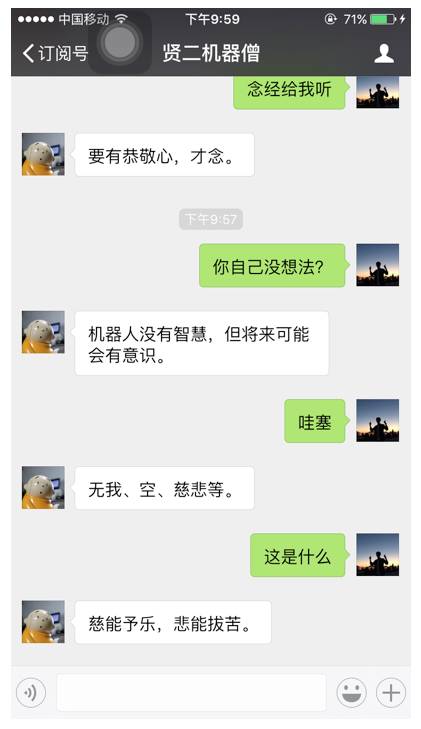
图 7:上下文补全效果
总的来说,上下文问题作为长期以来制约对话系统发展的关键技术,至今依然未得到充分解决。我们试图对上下文问题进行形式化定义,使用当下火热的深度学习方法进行求解,让机器人的健忘症得到了一定程度的缓解,前路依旧漫长,愿真正了解我们、懂我们的机器人助理早日来临。
参考文献
[1] Sutskever, Ilya, Oriol Vinyals, andQuoc V. Le. "Sequence to sequence learning with neural networks."Advances in neural information processing systems. 2014.
[2] A. Joulin, E. Grave, P. Bojanowski, T.Mikolov, Bag of Tricks for Efficient Text Classification
[3] Bahdanau, Dzmitry, Kyunghyun Cho, andYoshua Bengio. "Neural machine translation by jointly learning to alignand translate." arXiv preprint arXiv:1409.0473 (2014).
[4] Bengio, Yoshua, Patrice Simard, andPaolo Frasconi. "Learning long-term dependencies with gradient descent isdifficult." IEEE transactions on neural networks 5.2 (1994): 157-166.
[5] Graves, Alex. "Sequencetransduction with recurrent neural networks." arXiv preprintarXiv:1211.3711 (2012).
[6] Kadlec, Rudolf, et al. "Text understandingwith the attention sum reader network." arXiv preprint arXiv:1603.01547(2016).
[7] Jiatao Gu, Zhengdong Lu, Hang Li, etal. "Incorporating Copying Mechanism in Sequence-to-SequenceLearning". ACL 2016.

 微信ID:WeChatAI
微信ID:WeChatAI
 长按左侧二维码关注
长按左侧二维码关注

