揭穿AI竞赛真实面目!各种冠军模型根本没用,Kaggle受益者挺身反驳

新智元报道
新智元报道
作者:lukeoakdenrayner
编译:肖琴、鹏飞
【新智元导读】今天,一个话题引起热议:AI竞赛根本不能产生有用的模型,无法适用于现实世界;获胜的模型也不一定是最好的模型,冠军获胜只是因为他们运气好。那么,各种AI竞赛意义何在?作者的观点引发许多人反驳。
最近,一个新的大型CT脑扫描数据集被发布,其目的是训练模型以检测颅内出血。
围绕该数据集,北美放射学会(RSNA)发布了一场Kaggle竞赛,有人在Twitter搞了个小投票:
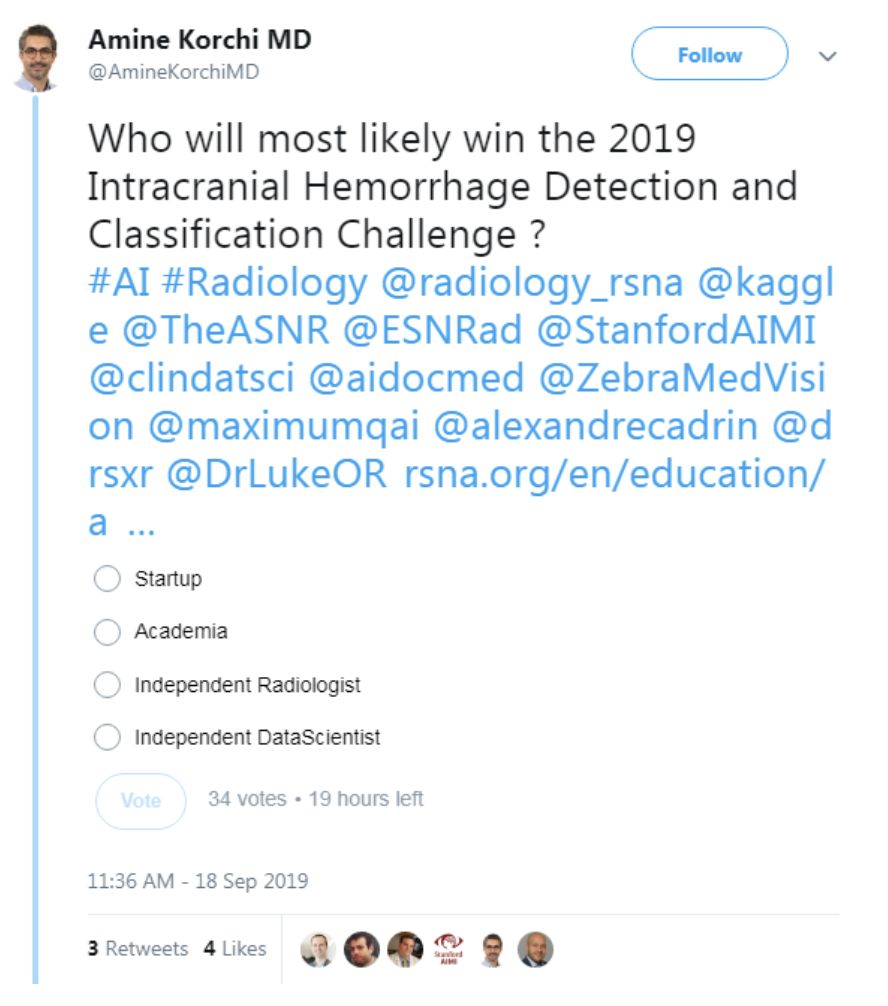
引发讨论:

讨论继续,人们的想法从“但是既然有一个验证集,怎么会过拟合呢?”到“提出的解决方案永远不会被直接应用”(后者来自以前的竞赛获胜者)。
随着讨论的深入,我意识到,尽管我们“都知道”竞赛结果在临床意义上是有点可疑的,但我从未真正看到一个令人信服的解释,来解释为什么会这样。
这就是这篇文章的内容,希望能够解释为什么竞赛实际上并不是构建有用的AI系统。
那么,医疗AI领域的竞赛是怎样的呢?下面是一些选项:
让团队尝试解决一个临床问题
让团队探索如何解决问题,并尝试新的解决方案
让团队构建一个在竞赛测试集中表现最好的模型
浪费时间
现在,我还没有厌倦到直接跳到最后一个选项。但是前三个选项呢?这些模型适用于临床任务吗?它们是否能带来广泛适用的解决方案和新颖性?又或者它们只在竞赛中表现出色,而不适用于现实世界?
(剧透:我认为是后者)。
我们是否应该期望竞赛能产生好模型呢?让我们看看其中一位组织者是怎么说的。
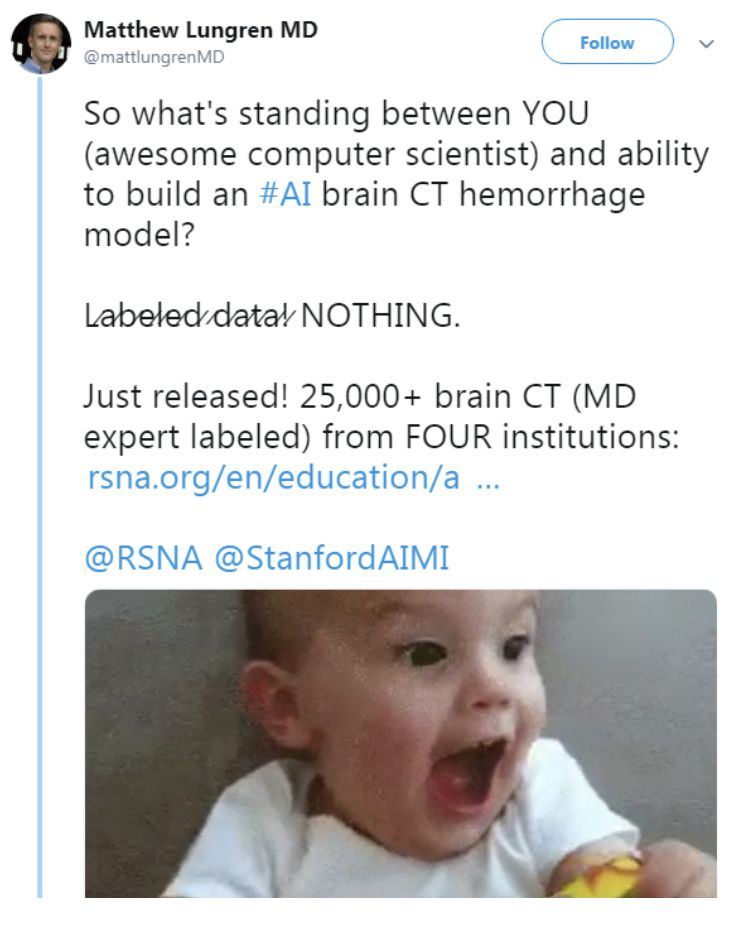
酷。完全同意。缺乏大型、标记良好的数据集是构建有用的临床AI的最大障碍,因此该数据集应该有所帮助。
但是说数据集有用并不等于说竞赛将产生好模型。
因此,为了定义术语,让我们假设一个好模型是指:一个可以在未见过的数据(模型不知道的情况)上检测脑出血的模型。
相反,一个糟糕的模型是,它不能在未见过的数据中检测出脑出血。
这些定义毫无争议。我相信竞赛的组织者会同意这些定义,并且希望他们的参与者能做出好的模型而不是糟糕的模型。事实上,他们已经明确地以一种旨在促进好模型的方式设立了竞赛。
这还不够。

要是学术争论这么可爱就好了
ML101(machine learning 101的拟人化)告诉我们,控制过拟合的方法是使用一个留出的测试集(hold-out test set),这是模型训练中没有见过的数据。这模拟了在临床环境中观察新患者。
ML101还表示,留出数据只适用于一次测试。如果你测试多个模型,那么即使你没有欺骗并将测试信息泄漏到开发过程中,那么最佳结果也可能是一个异常值,这个异常值只比你偶然得到的最差结果好。
因此,今天的竞赛组织者会制作出一个留出的测试集,并且只允许每个团队在数据上运行一次模型。问题解决了,ML101说。获胜者只测试了一次,所以没有理由认为他们的是异常值,他们只是拥有最好的模型。
别急,伙计。
让我介绍一下“Epi101”(Epidemiology 101),它声称有一枚神奇的硬币。

Epi101让你抛10次硬币。如果你得到8个及以上的正面,就证明了硬币是有魔力的(虽然这个断言显然是无稽之谈,但你要继续下去,因为你知道8/10个正面相当于一枚均匀硬币的p值<0.05,所以它一定是合理的)。

在你不知道的情况下,Epi101对另外99个人也做了同样的事情,他们都认为只有自己在测试硬币。你希望发生什么?
如果这枚硬币是完全正常的,而不是魔法硬币,那么大约5个人会发现这枚硬币是特殊的。看似显而易见,但是要考虑个体的情况。这5个人都只做了一次测试。根据他们的说法,他们有统计上显著的证据表明他们手里拿着一枚“魔法”硬币。
现在想象你不是在抛硬币。想象一下,你们都在一个竞赛测试集上运行模型。你不再怀疑你的硬币是否有魔力,而是希望你的模型是最好的,只要最好就能挣25,000美元。
当然,你不能提交多个模型。那样会是作弊。其中一个模型可能表现得很好,这相当于抛一枚均匀硬币10次碰巧得到8个正面。
好在有规则禁止提交多个模型,否则其他99个参与者和他们的99个模型中的任何一个都可能获胜,只要运气好……

当然,我们用 Epi101 硬币看到的效果适用于我们的竞赛。由于随机的机会,一些比例的模型将优于其他模型,即使它们彼此都一样好。数学并不关心是一个团队测试了100个模型,还是100个团队。
即使某些模型在某种意义上优于其他模型,除非你真正相信冠军的ML能力独一无二,否则你必须承认,至少其他一些参与者也会获得类似的结果,因此冠军获胜只是因为他们运气好。真正的“最佳性能”将会出现在某个地方,可能高于平均水平,但低于冠军方案。
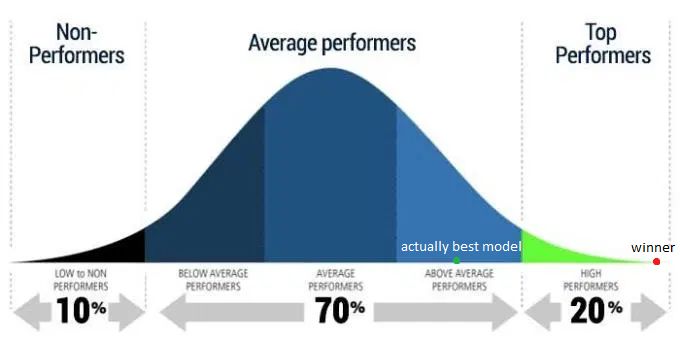
Epi101表示这种效应被称为多重假设检验。在竞赛的情况下,你有很多假设——每个参与者都比其他参与者更好。100个参与者,就有100个假设。
其中一个假设,如果单独考虑,可能会告诉我们有一个具有统计学意义(p<0.05)的胜利者。但是综合来看,即使获胜者的获胜p值小于0.05,这并不意味着我们只有5%的机会做出不合理的决定。事实上,如果这是抛硬币,我们将有超过99%的机会让一个或更多人“赢”,并得到8个正面!
这就是AI竞赛的获胜者:抛硬币时恰好得到8次正面的人。
有趣的是,虽然ML101非常清楚,自己运行100个模型并选择最好的模型将导致过拟合,但他们很少讨论这种“人群的过拟合”。当你考虑到几乎所有的ML研究都是在经过大量过度测试的公共数据集进行的,这就更奇怪了……
那么我们如何处理多重假设检验呢?这一切都归结于问题的原因,即数据。Epi101告诉我们,任何测试集都是目标总体的一个有偏差的版本。在这种情况下,目标人群是“所有CT头部成像的患者,有或无颅内出血”。让我们来看看这种偏见是如何产生的,举一个小的数据集示例:
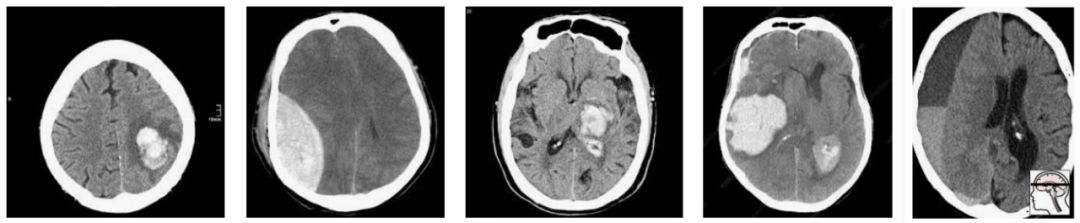
在这一人群中,我们有相当合理的“临床”病例组合。3例脑内出血(可能与高血压或中风有关),2例创伤性出血。
现在让我们对这个群体进行抽样,以构建我们的测试集:
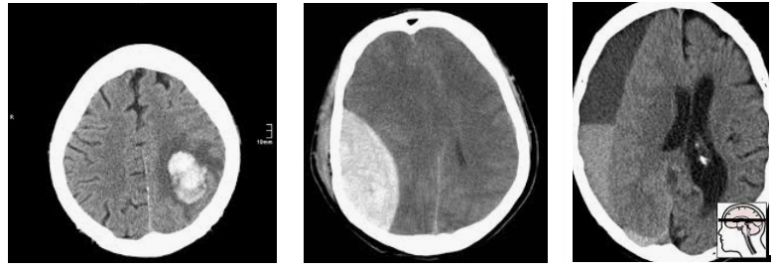
随机地,我们抽样得到的大部分是轴外出血。在这项测试中表现良好的模型不一定能在真实的患者身上发挥同样的效果。事实上,你可能期望一个擅长轴外出血而牺牲脑内出血的模型获胜。
但Epi101不仅指出了问题。Epi101有一个解决方案。
只有一种方法可以得到一个无偏见的测试集——即包含整个总体!那么,无论哪种模型在测试中表现良好,在实践中也将是最好的,因为你在所有可能的未来患者身上测试了它(这似乎很困难)。
这就引出了一个非常简单的想法——随着测试集的增大,你的测试结果将变得更加可靠。我们可以通过计算来预测测试集的可靠性。
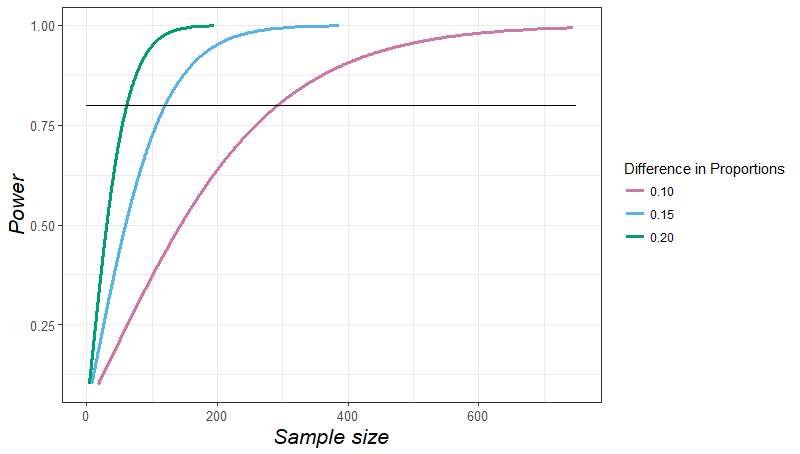
根据 power 曲线,如果你粗略地知道你的“获胜”模型比次优模型好多少,那么你就可以估计需要多少测试用例来可靠地证明它更好。
因此,要确定你的模型是否比竞争对手的模型好10%,你需要大约300个测试用例。还可以看到,随着模型之间的差异越来越小,所需的示例数量将呈指数级增长。
让我们把这个付诸实践。比如另一个医疗AI竞赛,ACR气胸分割挑战赛,我们会发现分数(范围在0和1之间)的差异在排行榜的顶部是可以忽略不计的。这次挑战赛的数据集有3200个示例。
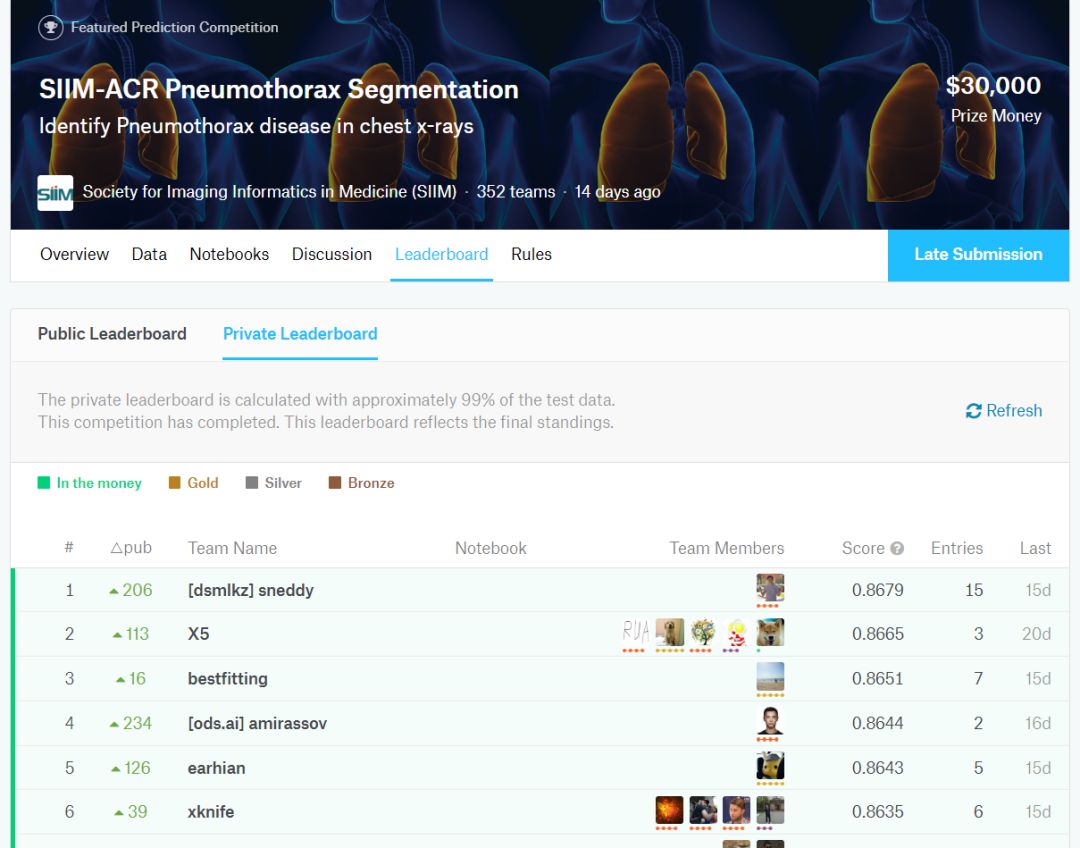
第一名和第二名的分数差距是0.0014,我们把它放到样本容量计算器里。
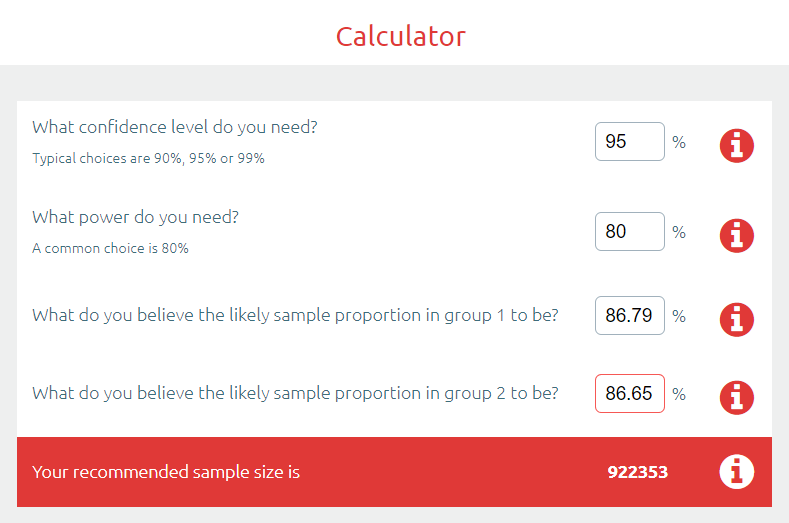
好了,为了显示这两个结果之间的显著差异,你需要92万示例。
但为什么止步于此呢?我们甚至还没有讨论多重假设检验。如果只有一个假设,也就是说只有两名参与者,那么就需要这么多的示例。
如果我们再看一下排行榜,有351个团队提交了模型。规则规定他们可以提交两个模型,所以我们不妨假设至少有500个测试。这必然产生一些异常值,就像500个人抛一枚均匀硬币。
多重假设检验在医学中非常普遍,尤其是在基因组学等“大数据”领域。过去几十年,我们一直在学习如何应对这种情况。处理这个问题最简单可靠的方法叫做Bonferroni校正。
Bonferroni校正非常简单:将p值除以测试次数,找到一个“统计显著性阈值”,该阈值已为所有额外的抛硬币操作调整过。在这种情况下,是0.05/500,我们新的p值目标是0.0001,任何比这更差的结果都将被认为支持零假设(即竞争对手在测试集中的表现同样出色)。让我们把它代入计算器。
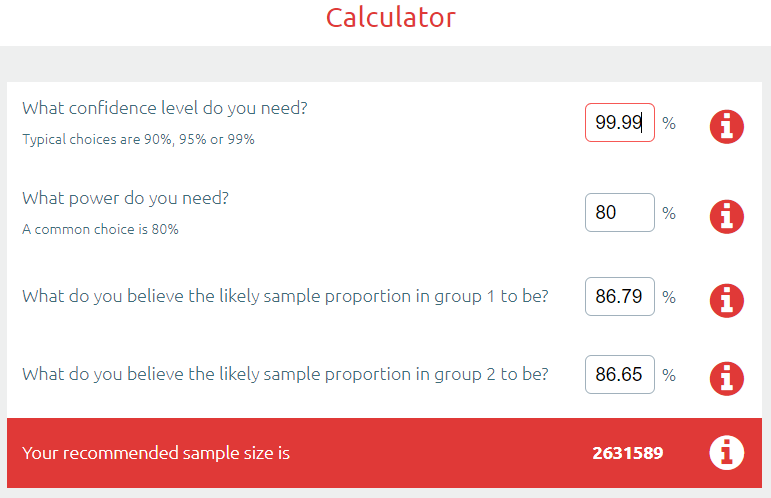
你可能会说我这么搞非常不公平,排行榜的顶部肯定会有一些好模型彼此之间没有明显的不同。好吧,那我们试试第一名和第 150 名。
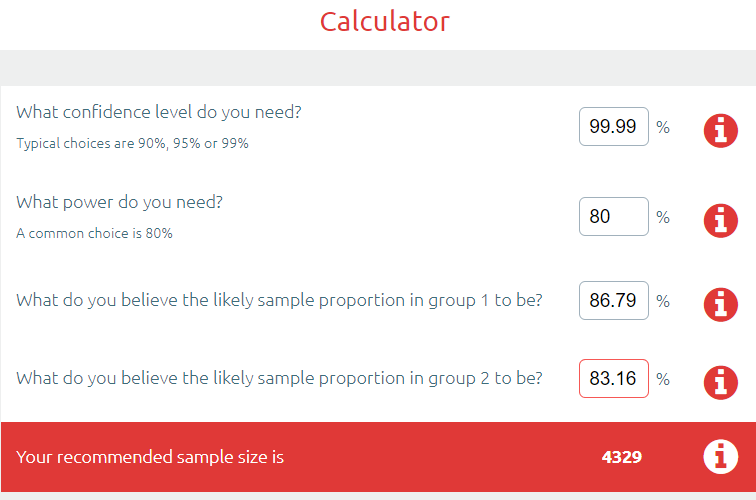
事实上,我直到第 192 名,才找到一个结果,其中样本量足以产生 “统计上显着” 的差异。
但也许这是 pneumothorax 挑战特有的?其他比赛怎么样?
在 MURA,有 207 个 X 射线的测试集,70 个团队 “每月提交模型不超过两个”,所以让我们慷慨的说,就算 100 个模型吧,结果 “第一名” 模型仅和第 56 名及更靠后的有明显差异。
在 RSNA Pneumonia Detection Challenge 中,有 3000 个测试图像,350 个团队各提交一个模型。与第 30 名以后才看出显著差异。
那么医学之外呢?
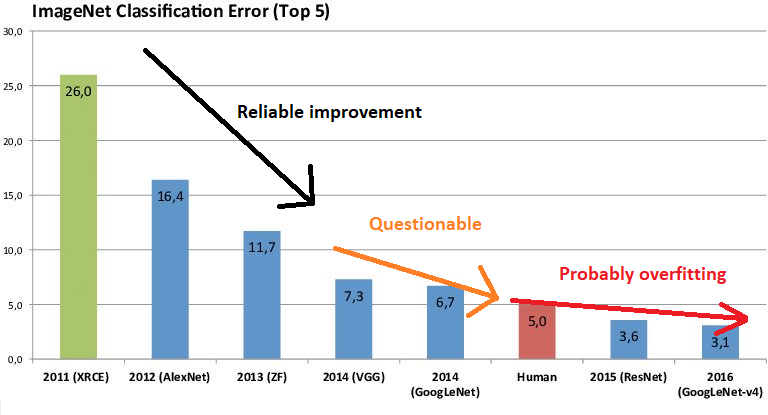
在 ImageNet 结果中从左到右看,每年的改进速度变慢,并且对数据集进行测试的人数增加。我无法真正估计这些数字,但是有人真的相信在 2010 年中期的 SOTA 热潮就一定不是众包过度拟合吗?

他们显然不能可靠地找到最好的模型。他们甚至没有真正找到有效的技术来构建优秀的模型,因为我们不知道这一百多个模型种,哪些真的用了好的可靠的方法,而哪种方法只不过是迎合了能力低下的测试集。
问问竞赛组织者,他们大多说竞赛是为了宣传。我想这就足够了。
人工智能竞赛很有趣,可以实现社区建设,搜集人才,品牌推广和获取关注。
但人工智能竞赛并不是为了开发有用的模型。
在科幻小说里,竞赛绝对是非常有用的。 但在现实中,1000 个型号的集合将无法在生产中扩展,这就是为什么如果用作黑盒子,获胜者的解决方案很可能无用。





