11篇ICLR2020满分文章,来看看他们都在做什么?
【导读】International Conference on Learning Representations (ICLR)虽然是人工智能的分支学科“representation learning”的会议,但是由于表征学习的基础性,使得ICLR对人工智能和深度学习领域影响深远。近日,随着ICLR 2020的Review工作接近尾声,一大批优秀文章也浮出了水面。根据当前最新的OpenReview情况,小编找到了11篇ICLR 2020 满分(全8分)文章,一起来看看他们在做什么吧。

【Paper List】
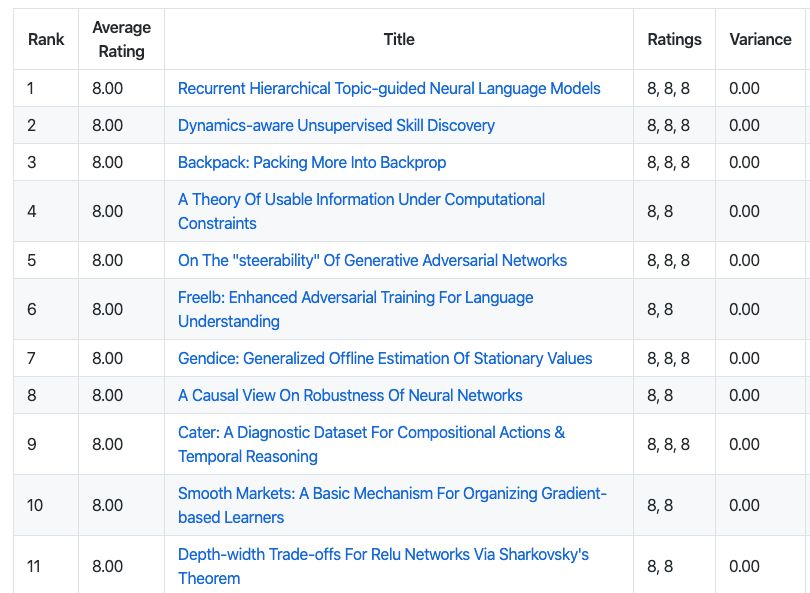
各个文章的总结,是小编根据自己的理解写的,如有错误,欢迎评论区指出
Recurrent Hierarchical Topic-guided Neural Language Models
循环层次主题引导的神经网络语言模型
总结:引入了一种更大上下文的语言模型来同时捕获语法和语义,使它能够生成高度可解释的句子和段落
关键词: 贝叶斯深度学习(Bayesian deep learning), 循环伽马信念网络(recurrent gamma belief net),更大上下文的语言模型(larger-context language model), 变分推断(variational inference), 句子生成(sentence generation), 段落生成(paragraph generation)
摘要:To simultaneously capture syntax and semantics from a text corpus, we propose a new larger-context language model that extracts recurrent hierarchical semantic structure via a dynamic deep topic model to guide natural language generation. Moving beyond a conventional language model that ignores long-range word dependencies and sentence order, the proposed model captures not only intra-sentence word dependencies, but also temporal transitions between sentences and inter-sentence topic dependences. For inference, we develop a hybrid of stochastic-gradient MCMC and recurrent autoencoding variational Bayes. Experimental results on a variety of real-world text corpora demonstrate that the proposed model not only outperforms state-of-the-art larger-context language models, but also learns interpretable recurrent multilayer topics and generates diverse sentences and paragraphs that are syntactically correct and semantically coherent.
地址:https://openreview.net/forum?id=Byl1W1rtvH
Dynamics-aware Unsupervised Skill Discovery 动态感知的无监督技能发现
总结: 提出了一种无监督的技能发现方法,使基于模型的分层强化学习规划成为可能。
关键词:强化学习(reinforcement learning), 无监督学习(unsupervised learning), 基于模型的学习(model-based learning), 深度学习(deep learning), 层次强化学习(hierarchical reinforcement learning)
摘要:Conventionally, model-based reinforcement learning (MBRL) aims to learn a global model for the dynamics of the environment. A good model can potentially enable planning algorithms to generate a large variety of behaviors and solve diverse tasks. However, learning an accurate model for complex dynamical systems is difficult, and even then, the model might not generalize well outside the distribution of states on which it was trained. In this work, we combine model-based learning with model-free learning of primitives that make model-based planning easy. To that end, we aim to answer the question: how can we discover skills whose outcomes are easy to predict? We propose an unsupervised learning algorithm, Dynamics-Aware Discovery of Skills (DADS), which simultaneously discovers predictable behaviors and learns their dynamics. Our method can leverage continuous skill spaces, theoretically, allowing us to learn infinitely many behaviors even for high-dimensional state-spaces. We demonstrate that zero-shot planning in the learned latent space significantly outperforms standard MBRL and model-free goal-conditioned RL, can handle sparse-reward tasks, and substantially improves over prior hierarchical RL methods for unsupervised skill discovery.
地址:https://openreview.net/forum?id=HJgLZR4KvH
Backpack: Packing More Into Backprop Backpack:在反向传播的时候,传递更多信息
总结:发布了一种基于PyTorch的自动求导框架,扩展了反向传播算法,能从一阶和二阶导数中提取额外的信息。
摘要:Automatic differentiation frameworks are optimized for exactly one thing: computing the average mini-batch gradient. Yet, other quantities such as the variance of the mini-batch gradients or many approximations to the Hessian can, in theory, be computed efficiently, and at the same time as the gradient. While these quantities are of great interest to researchers and practitioners, current deep learning software does not support their automatic calculation. Manually implementing them is burdensome, inefficient if done naively, and the resulting code is rarely shared. This hampers progress in deep learning, and unnecessarily narrows research to focus on gradient descent and its variants; it also complicates replication studies and comparisons between newly developed methods that require those quantities, to the point of impossibility. To address this problem, we introduce BackPACK, an efficient framework built on top of PyTorch, that extends the backpropagation algorithm to extract additional information from first-and second-order derivatives. Its capabilities are illustrated by benchmark reports for computing additional quantities on deep neural networks, and an example application by testing several recent curvature approximations for optimization.
地址:https://openreview.net/forum?id=BJlrF24twB
A Theory Of Usable Information Under Computational Constraints 在计算限制下的可用信息理论
总结:提出了一种比互信息更好的F-信息
摘要:We propose a new framework for reasoning about information in complex systems. Our foundation is based on a variational extension of Shannon’s information theory that takes into account the modeling power and computational constraints of the observer. The resulting predictive F-information encompasses mutual information and other notions of informativeness such as the coefficient of determination. Unlike Shannon’s mutual information and in violation of the data processing inequality, F-information can be created through computation. This is consistent with deep neural networks extracting hierarchies of progressively more informative features in representation learning. Additionally, we show that by incorporating computational constraints, F-information can be reliably estimated from data even in high dimensions with PAC-style guarantees. Empirically, we demonstrate predictive F-information is more effective than mutual information for structure learning and fair representation learning.
地址:https://openreview.net/forum?id=r1eBeyHFDH
On The "steerability" Of Generative Adversarial Networks 论生成对抗网络的可控制性
总结:量化了GANs模型在数据集上的泛化能力,并提出技术来帮助GANs模型在不同数据集上运行的更好。
关键词:生成对抗网络(generative adversarial network),隐空间插值( latent space interpolation), 数据集偏差(dataset bias), 模型泛化(model generalization)
摘要:An open secret in contemporary machine learning is that many models work beautifully on standard benchmarks but fail to generalize outside the lab. This has been attributed to biased training data, which provide poor coverage over real world events. Generative models are no exception, but recent advances in generative adversarial networks (GANs) suggest otherwise -- these models can now synthesize strikingly realistic and diverse images. Is generative modeling of photos a solved problem? We show that although current GANs can fit standard datasets very well, they still fall short of being comprehensive models of the visual manifold. In particular, we study their ability to fit simple transformations such as camera movements and color changes. We find that the models reflect the biases of the datasets on which they are trained (e.g., centered objects), but that they also exhibit some capacity for generalization: by "steering" in latent space, we can shift the distribution while still creating realistic images. We hypothesize that the degree of distributional shift is related to the breadth of the training data distribution. Thus, we conduct experiments to quantify the limits of GAN transformations and introduce techniques to mitigate the problem.
地址:https://openreview.net/forum?id=HylsTT4FvB
Freelb: Enhanced Adversarial Training For Language Understanding
Freelb: 增强对抗性的自然语言理解训练方法
总结:提出了一种新的对抗训练算法FreeLB,它通过在单词嵌入中加入对抗扰动并最小化在输入样本周围不同区域内的结果对抗风险,来提高了嵌入空间的鲁棒性和不变性。
摘要:Adversarial training, which minimizes the maximal risk for label-preserving input perturbations, has proved to be effective for improving the generalization of language models. In this work, we propose a novel adversarial training algorithm - FreeLB, that promotes higher robustness and invariance in the embedding space, by adding adversarial perturbations to word embeddings and minimizing the resultant adversarial risk inside different regions around input samples. To validate the effectiveness of the proposed approach, we apply it to Transformer-based models for natural language understanding and commonsense reasoning tasks. Experiments on the GLUE benchmark show that when applied only to the finetuning stage, it is able to improve the overall test scores of BERT-based model from 78.3 to 79.4, and RoBERTa-large model from 88.5 to 88.8. In addition, the proposed approach achieves state-of-the-art test accuracies of 85.39\% and 67.32\% on ARC-Easy and ARC-Challenge. Experiments on CommonsenseQA benchmark further demonstrate that FreeLB can be generalized and boost the performance of RoBERTa-large model on other tasks as well.
地址:https://openreview.net/forum?id=BygzbyHFvB
Gendice: Generalized Offline Estimation Of Stationary Values 平稳值的广义离线估计
总结:本文提出了一种新的广义平稳分布校正估计算法GenDICE,该算法既能处理多行为不可知样本的折现估计,又能处理多行为不可知样本的平均离线估计。
关键词:离线策略评估(Off-policy Policy Evaluation), 强化学习(Reinforcement Learning), 平稳分布校正估计(Stationary Distribution Correction Estimation), 芬舍尔对偶(Fenchel Dual)
摘要:An important problem that arises in reinforcement learning and Monte Carlo methods is estimating quantities defined by the stationary distribution of a Markov chain. In many real-world applications, access to the underlying transition operator is limited to a fixed set of data that has already been collected, without additional interaction with the environment being available. We show that consistent estimation remains possible in this scenario, and that effective estimation can still be achieved in important applications. Our approach is based on estimating a ratio that corrects for the discrepancy between the stationary and empirical distributions, derived from fundamental properties of the stationary distribution, and exploiting constraint reformulations based on variational divergence minimization. The resulting algorithm, GenDICE, is straightforward and effective. We prove the consistency of the method under general conditions, provide a detailed error analysis, and demonstrate strong empirical performance on benchmark tasks, including off-line PageRank and off-policy policy evaluation.
地址:https://openreview.net/forum?id=HkxlcnVFwB
A Causal View On Robustness Of Neural Networks 一种针对神经网络鲁棒性的因果观点
总结:提出了一种对神经网络鲁棒性的因果看法,明确的将数据操作,作为观察结果变量的原因进行建模
摘要:We present a causal view on the robustness of neural networks against input manipulations, which applies not only to traditional classification tasks but also to general measurement data. Based on this view, we design a deep causal manipulation augmented model (deep CAMA) which explicitly models the manipulations of data as a cause to the observed effect variables. We further develop data augmentation and test-time fine-tuning methods to improve deep CAMA's robustness. When compared with discriminative deep neural networks, our proposed model shows superior robustness against unseen manipulations. As a by-product, our model achieves disentangled representation which separates the representation of manipulations from those of other latent causes.
地址:https://openreview.net/forum?id=Hkxvl0EtDH
Cater: A Diagnostic Dataset For Compositional Actions & Temporal Reasoning Cater: 用于组合动作和时间推理的诊断数据集
总结:提出了一种新的视频理解基准及其数据集,它需要模型对视频内的时空进行实实在在的理解(逐帧分析并不work),才能完成任务。
摘要:Computer vision has undergone a dramatic revolution in performance, driven in large part through deep features trained on large-scale supervised datasets. However, much of these improvements have focused on static image analysis; video understanding has seen rather modest improvements. Even though new datasets and spatiotemporal models have been proposed, simple frame-by-frame classification methods often still remain competitive. We posit that current video datasets are plagued with implicit biases over scene and object structure that can dwarf variations in temporal structure. In this work, we build a video dataset with fully observable and controllable object and scene bias, and which truly requires spatiotemporal understanding in order to be solved. Our dataset, named CATER, is rendered synthetically using a library of standard 3D objects, and tests the ability to recognize compositions of object movements that require long-term reasoning. In addition to being a challenging dataset, CATER also provides a plethora of diagnostic tools to analyze modern spatiotemporal video architectures by being completely observable and controllable. Using CATER, we provide insights into some of the most recent state of the art deep video architectures.
地址:https://openreview.net/forum?id=HJgzt2VKPB
Smooth Markets: A Basic Mechanism For Organizing Gradient-based Learners Smooth Markets: 组织梯度学习者的基本机制
总结:尝试理解和控制学习算法之间的交互
摘要:With the success of modern machine learning, it is becoming increasingly important to understand and control how learning algorithms interact. Unfortunately, negative results from game theory show there is little hope of understanding or controlling general n-player games. We therefore introduce smooth markets (SM-games), a class of n-player games with pairwise zero-sum interactions. SM-games codify a common design pattern in machine learning that includes some GANs, adversarial training, and other recent algorithms. We show that SM-games are amenable to analysis and optimization using first-order methods.
地址:https://openreview.net/forum?id=B1xMEerYvB
Depth-width Trade-offs For Relu Networks Via Sharkovsky's Theorem 基于Sharkovsky定理的ReLU网络深度-宽度权衡
总结:指出了DNNs表达性和动力系统里的Sharkovsky定理之间的一个新的联系,从而能够刻画ReLU网络的深度-宽度权衡
摘要:Understanding the representational power of Deep Neural Networks (DNNs) and how their structural properties (e.g., depth, width, type of activation unit) affect the functions they can compute, has been an important yet challenging question in deep learning and approximation theory. In a seminal paper, Telgarsky high- lighted the benefits of depth by presenting a family of functions (based on simple triangular waves) for which DNNs achieve zero classification error, whereas shallow networks with fewer than exponentially many nodes incur constant error. Even though Telgarsky’s work reveals the limitations of shallow neural networks, it doesn’t inform us on why these functions are difficult to represent and in fact he states it as a tantalizing open question to characterize those functions that cannot be well-approximated by smaller depths. In this work, we point to a new connection between DNNs expressivity and Sharkovsky’s Theorem from dynamical systems, that enables us to characterize the depth-width trade-offs of ReLU networks for representing functions based on the presence of a generalized notion of fixed points, called periodic points (a fixed point is a point of period 1). Motivated by our observation that the triangle waves used in Telgarsky’s work contain points of period 3 – a period that is special in that it implies chaotic behavior based on the celebrated result by Li-Yorke – we proceed to give general lower bounds for the width needed to represent periodic functions as a function of the depth. Technically, the crux of our approach is based on an eigenvalue analysis of the dynamical systems associated with such functions.
地址:https://openreview.net/forum?id=BJe55gBtvH






