用于强化学习的置换不变神经网络


发布人:东京 Google Research 研究员 David Ha 和研究软件工程师 Tang Yujin

人类有一种很神奇的能力,可以使用一种感官方式(比如触摸)来提供通常由另一种感官(比如视觉)收集的环境信息。这种适应性能力,被称为感官替代 (Sensory substitution),是神经科学领域一个很有名的现象。一些有难度的适应,例如适应上下颠倒着看东西、学习骑乘“反转”自行车,或学习通过解读放置在舌头上的电极网格发射的视觉信息来“看”,可能需要几周、几个月甚至几年的时间才能掌握,但无论多难,人们最终都能够适应感官替代。
上下颠倒
https://www.sciencedirect.com/science/article/abs/pii/S0010945217301314
“反转”自行车
https://ed.ted.com/best_of_web/bf2mRAfC

感官替代的示例
左图:舌显象装置(Maris 和 Bach-y-Rita,2001;图片:Kaczmarek,2011);右图:“倒置眼镜”,最初由 Erismann 和 Kohler 构思于 1931 年。(图片:维基百科 Upside down goggles)
舌显象装置
https://www.sciencedirect.com/science/article/abs/pii/S0006899301026671
Kaczmarek,2011
https://www.sciencedirect.com/science/article/pii/S1026309811001702#f000020
然而,大多数神经网络根本无法适应感官替代。例如,大多数强化学习 (Reinforcement Learning, RL) 代理要求其输入采用预先指定的格式,否则就会失败。对于这些代理来说,其输入需要为固定大小,且输入的每个元素都应该带有指定位置的像素强度等精确含义,或者带有位置或速度等状态信息。在主流 RL 基准任务(例如 Ant 或 Cart-pole)中,如果以当前 RL 算法训练的代理在感觉输入上发生变化,或者代理获得与当前任务无关的额外嘈杂输入,该代理将失败。
Ant
https://pybullet.org/
Cart-pole
https://github.com/google/brain-tokyo-workshop/tree/master/learntopredict/cartpole
RL 算法
hhttps://github.com/DLR-RM/stable-baselines3
在 NeurIPS 2021 的焦点论文“感觉神经元作为转换器:用于强化学习的置换不变神经网络 (The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning)”中,我们研究了置换不变 (permutation invariant) 神经网络代理,它要求每个感觉神经元(从环境中接收感觉输入的感受器)理解其输入信号的含义和背景,而不是明确假设一个固定的含义。实验表明,此类代理能够稳健地应对包含额外冗余或嘈杂信息的观察,以及损坏和不完整的观察。
焦点论文
https://arxiv.org/abs/2109.02869
感觉神经元作为转换器:用于强化学习的置换不变神经网络
https://attentionneuron.github.io/

置换不变强化学习代理,适应感官替代。左图:Ant 的 28 个观察的顺序每 200 个时间步随机重排一次。与标准策略不同,我们的策略不受突然置换的输入影响。右图:给定大量冗余嘈杂输入的 Cart-pole 代理(互动式网络演示)
网络演示
https://attentionneuron.github.io/#cartpole_demo_special
除了适应状态观察环境中的感官替代(如 Ant 和 Cart-pole 示例),这些代理还可以适应复杂视觉观察环境中的感官替代(如仅使用像素观察的 CarRacing 游戏)并在输入图像流不断重排时运作:
CarRacing
https://gym.openai.com/envs/CarRacing-v0/

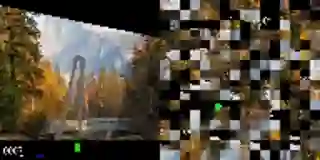
我们将来自 CarRacing 的视觉输入分成由小图块组成的二维网格,并打乱其顺序。在没有任何额外训练的情况下,即使原始训练背景(左)被新图像(右)替换,我们的代理仍然可以运作

我们的方法在每个时间步从环境中获取观察,并将观察的每个元素输入到特定又相同的神经网络(即“感觉神经元”),每个神经网络彼此之间没有固定的关系。随着时间的推移,每个感觉神经元只整合来自其特定感觉输入通道的信息。因为每个感觉神经元只接收整个画面的一小部分,所以它们需要通过通信进行自组织 (Self-organization),实现 (Emergence) 全局一致行为。
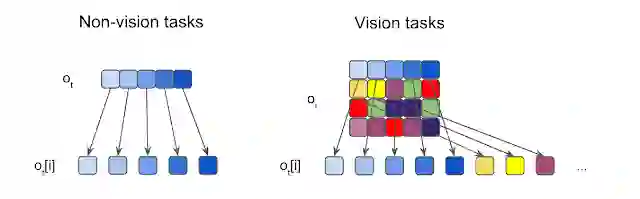
观察分割的图示。我们将每个输入分割成元素,然后将这些元素馈送到独立的感觉神经元。对于非视觉任务,由于输入通常是一维向量,所以每个元素都是一个标量。对于视觉任务,我们将每个输入图像裁剪成不重叠的图块
我们训练神经元广播消息,以此鼓励神经元相互通信。在局部接收信息的同时,每个单独的感觉神经元也在每个时间步连续广播输出消息。经由类似于 Transformer 架构中应用的关注机制,这些消息被整合并组合成一个输出向量,即全局潜码 (global latent code)。然后,策略网络使用全局潜码生成供代理与环境交互的动作。这个动作还会在下一个时间步中反馈到每个感觉神经元,从而关闭通信循环。
Transformer
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
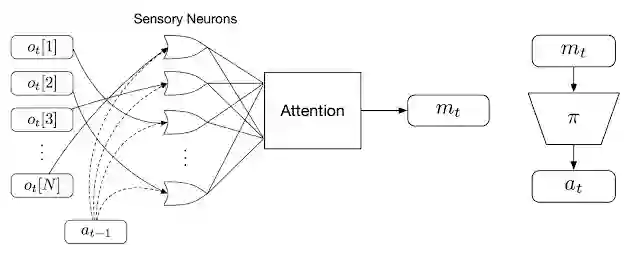
置换不变强化学习方法概览。我们首先将每个观察 (ot) 馈送到特定的感觉神经元(以及代理的先前动作,at-1)。然后,每个神经元独立生成和广播一条消息。关注机制将消息汇总为一个全局潜码 (mt),提供给代理的下游策略网络 (𝜋),生成代理的动作 at
为什么这个系统是置换不变的?每个感觉神经元都是相同的神经网络,不限于仅处理来自一个特定感觉输入的信息。事实上,在我们的设置中,每个感觉神经元的输入都未被定义。各个神经元必须关注其他感觉神经元接收到的输入,以此理解输入信号的含义,而不是明确假设一个固定的含义。这就鼓励代理将整个输入作为无序集处理,并使系统对其输入保持置换不变。此外,原则上,代理可以根据需要使用尽可能多的感觉神经元,处理任意长度的观察。这两种属性都将帮助代理适应感官替代。
无序集
https://arxiv.org/abs/1810.00825
我们在较简单的状态观察环境中证明了这种方法的稳健性和灵活性。代理接收的观察输入是低维向量,包含有关代理状态的信息,例如其组件的位置或速度。在流行的 Ant 移动任务中,代理共有 28 个输入,包含位置和速度等信息。我们在试验期间多次打乱输入向量的顺序,结果表明代理始终能够快速适应和继续前进。
在 cart-pole 中,代理的目标是摆动安装在推车中心的推车杆并使其保持直立。通常,代理只会看到 5 个输入,但我们修改了 cartpole 环境,提供了 15 个重排的输入信号,其中 10 个是纯噪声,其余是来自环境的实际观察。代理仍然能够执行任务,表明系统有能力处理大量输入并且只关注它认为有用的通道。这种灵活的能力适合处理来自定义不明确系统的未指定数量的大量信号,此类信号大部分都是噪声。
我们还将这种方法应用于高维视觉环境,其中的观察是像素图像流。这一部分研究的是屏幕重排版本的视觉强化学习环境。每个观察帧都被划分为一个图块网格,代理必须像拼拼图一样在重排的顺序下处理图块,确定待采取的行动方案。为演示视觉任务上的方法,我们创建了一个重排版本的 Atari Pong。


重排的 Pong 结果。左图:经过训练的 Pong 代理只使用了 30% 的图块,就与 Atari 对手的性能不相上下。右图:无额外训练,向代理提供更多拼图块后,其性能有所提高
代理在这里的输入是一个可变长度的图块列表,因此只能从屏幕上“看到”图块的子集,与典型的强化学习代理不同。在拼图 Pong 实验中,我们将屏幕上的随机图块样本传递给代理,然后在游戏的其余部分进行修复。我们发现,丢弃 70% 的图块后(在这些固定随机位置),代理经过训练仍然能在对抗内置 Atari 对手时表现良好。有趣的是,如果我们随后向代理展现额外的信息(例如,允许它访问更多的图块),即使没有额外训练,其性能也会提高。代理按照重排的顺序收到所有图块后,每次都会获胜,这一结果与训练时看到整个屏幕的代理相同。
我们发现,在训练中使用无序观察施加额外的障碍也会带来额外的好处,例如,CarRacing 训练环境的背景换为新图像后,任务中未见的变化得到了更好的泛化。

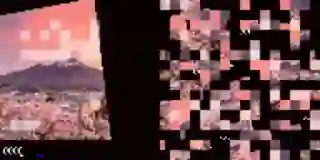
重排的 CarRacing 结果。代理已经学会将注意力(由突出显示的图块表示)集中在道路边界上。左图:训练环境。右图:带有新背景的测试环境
本文介绍的置换不变神经网络代理可以处理定义不明确的、变化的观察空间。我们的代理能够稳健地应对包含冗余或嘈杂信息的观察以及损坏和不完整的观察。我们相信置换不变系统将为强化学习带来许多新的方向。
如果您有兴趣进一步了解这项研究,欢迎阅读我们的互动式文章(pdf 版本)或观看我们的视频。我们也为重现实验发布了代码。
互动式文章
https://attentionneuron.github.io/
pdf
https://arxiv.org/abs/2109.02869
视频
https://youtu.be/7nTlXhx0CZI
代码
https://github.com/google/brain-tokyo-workshop

点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看



