KDD 2021 | 用NAS实现任务无关且可动态调整尺寸的BERT压缩

(本文阅读时间:12 分钟)
不同设备往往对训练的模型有不同的要求,如模型占用内存的大小、推理时延等。为了满足设备的要求,技术人员往往需要对大规模的预训练模型进行压缩处理。但是由于存在大量复杂的场景和不同的下游任务,专门为每一种场景设计压缩过的BERT模型,需要投入大量的人力和计算资源。
对此,微软亚洲研究院的研究员们提出了 NAS-BERT 技术(相关论文已发表在 KDD 2021 大会上),可以直接在上游预训练任务中进行压缩训练,使压缩模型不再依赖于下游的具体任务。并且 NAS-BERT 只需通过一次搜索就可以直接产生不同尺寸的模型,进而满足不同设备的要求。所以即使是资源受限的设备,也可以动态选择合适的架构。相较于传统方法,NAS-BERT 极大地提高了训练效率。

论文链接:https://arxiv.org/abs/2105.14444
如表1所示,之前大部分的压缩工作都是针对具体任务本身而设计方法实现的。比如,DisilBERT 等工作会直接在上游模型进行压缩学习,对下游任务无关,但不能适应各种不同受限资源的场景。DynaBERT 则可以在下游任务中通过一次训练产生多种不同大小的模型,以达到动态调整尺寸的目的。而 NAS-BERT 与其他几种工作不同,它可以同时做到任务无关和动态调整尺寸,并且达到优越的性能。

表1:之前的 BERT 压缩工作
为了让 NAS-BERT 实现上述目的,研究员们直接在上游预训练阶段对 NAS-BERT 进行了架构搜索(NAS)与训练,并且一次性搜索出各种大小的模型,以方便各种场景的部署。通过尝试架构层面的组合方式,NAS-BERT 不仅能够探索模型本身的潜力,还可以搜索出更加优越的架构。
具体而言,NAS-BERT 首先在上游预训练任务上训练一个超网络。其中,超网络中的一个有向无环图就是一个架构,不同的架构在超网络中共享参数来降低训练成本。然后研究员们再通过自动架构搜索技术去训练这个超网络。由于超网络中包括各种尺寸的模型,因此可以覆盖到各种不同的模型大小。最后,在用超网络去评价每个架构的性能并选择出优越的架构。
然而在 BERT 预训练任务上做自动架构搜索是具有挑战性的。其主要原因有:1. BERT 预训练本身收敛慢并且需要巨大的计算资源;2. 巨大的搜索空间会进一步导致训练超网络变得困难。为了解决这两个问题,NAS-BERT 主要采用了模块化搜索和逐渐缩小搜索空间的技术。同时,为了在缩小搜索空间的基础上能够给出各种不同的架构,NAS-BERT 还使用了分桶搜索把搜索空间分成众多不同的桶,不同桶中的架构有着不同的模型大小和延迟,桶中的架构相互竞争,从而选出最优越的架构。并且不同桶的架构通过权重共享,以降低架构搜索的代价。通过使用这些技术,NAS-BERT 才得以快速地搜索出各种不同的优越架构。

NAS-BERT 的架构设计(如图1所示),首先使用了一个预训练的 BERT 模型作为教师模型,然后用教师模型指导超网络的搜索。为了降低搜索空间,NAS-BERT 把学生模型(超网络)分成了几个不同的搜索模块,然后每个搜索模块会进行单独的训练。超网络模块的监督信号由教师模型的相应模块给出。换言之,就是给定一批数据,可以得到教师模型的每个模块输入输出的隐藏表征,再用这些输入输出的隐藏表征去训练搜索模块。这样,不同的搜索模块可以分开搜索且并行训练,指数级地降低了搜索空间。
对于每一个搜索模块,网络设计如图1(a)所示,网络的每一层包括了所有可能的搜索的候选操作(例如卷积、注意力网络)。一个架构就是一条从底部到最上层的单向路径,不同的架构(路径)共享权重以降低训练所需要的资源。
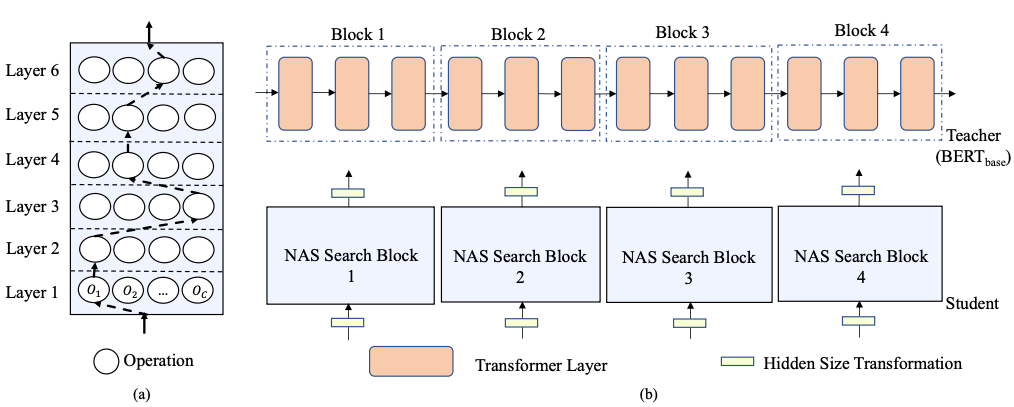
图1:NAS-BERT 方法框架图
为了使搜索的架构多样化,研究员们分别采用了三种不同的操作方法:注意力网络 MHA,前馈网络 FFN 和可分离卷积 CONV。MHA 和 FFN 是 Transformer 模型中的操作方法,采用这两种方法,可以使 Transformer 容纳在搜索空间中。由于 CONV 已经在很多自然语言任务中取得了不错的效果,因此研究员们也将其加入了搜索空间,以探索卷积和其他操作组合的潜力(操作设计请见图2)。同时,为了使搜索的架构具有各种不同的模型大小,研究员们让每一种操作都有128/192/256/384/512这5种不同的隐藏层大小,如表2所示。与此同时,还加入了 Identity(无操作),使其能搜索出各种不同层的架构。
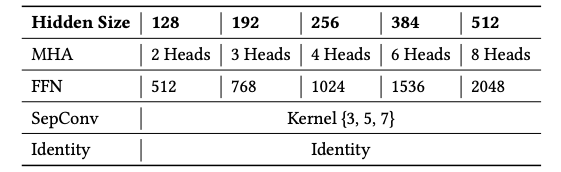
表2:操作集合的设计
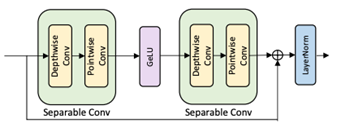
图2:卷积操作的设计
通过采用这种设计,可以使一个6层的搜索模块中有超过20万种可能的架构。如果采用4个搜索模块,架构的组合方式将超过10^20种。为了训练这个超网络,每次得到一批数据,就要随机采样一个架构进行训练,进而监督和学习教师模块的隐藏表征。由于搜索模块采样出来的架构输入输出的隐藏层大小可能和教师模块不一致,所以可以直接引入一个可学习的线性层进行转换,并和超网络一起训练。
虽然分模块搜索已经大大减小了搜索空间,但是训练超网络依然需要很长的时间收敛。而且大量的模型在竞争有限的资源,将导致每个模型的评估结果都不准确,严重影响了架构搜索的排序性能。所以研究员们在训练过程中的每一轮 epoch 结束时,会把搜索空间中一些没有希望的架构裁剪掉,然后在裁剪后的搜索空间上继续训练。通过这种方式,可以将更多的计算资源给到更有希望的架构,进而得到更加准确的评估,这既减少了资源的浪费,又加快了搜索过程。
然而直接对整个搜索空间进行裁剪,会导致无法得到大量不同大小的架构。因为超网络在搜索过程中可能偏向于大模型或者收敛快的模型,所以无约束的裁剪会使得最后得到的架构大小趋于相同。基于此,研究员们提出了分桶裁剪的方法,并且采用具体的数字为例,阐述了在分桶裁剪过程中,搜索空间是如何变化的。
首先研究员们将搜索空间均匀地分成10个桶,每个桶的架构被约束在不同的参数量和延迟下。尽管不同的架构落在不同的桶里,但是在训练的时候,它们的参数仍然是共享的。在每个迭代训练结束的时候,研究员们会随机从每个桶里采样出2000个架构,同时使用超网络评价它们在验证集上的分数,并删除一半的架构。通过重复这个过程,可以不断地收缩搜索空间,直到每个桶里只剩下10个架构。这样对于一个搜索模块而言,最终就得到了100个架构。假设共有4个搜索模块,那么就有100^4种组合方式,每一种组合方式都是一个完整的架构。
由于每个搜索模块中的100个架构来自不同的桶,因此它们有着显著不同的大小和延迟。所以通过组合不同的搜索模块而得到的100^4种架构,也具有显著不同的模型大小和延迟。
为了评估每个架构的性能,研究员们会首先评价每个搜索模块中100个架构在验证集上的损失。然后用不同模块的损失直接加和作为组合架构的性能。通过这种方式,仅仅通过4*100次验证集测试,就可以粗略得到所有架构的性能。该方法对于延迟的评估也是类似的,即先测量每个搜索模块内架构的延迟,然后再用不同模块的延迟加和作为整个架构的延迟。
所以当给定任何一种关于模型大小和延迟的约束时,可以通过查表的方式快速找到性能最高的架构。这种架构本身是在上游预训练任务中挑选出来的,因此与下游任务无关。
为了评估搜索得到的架构性能,研究员们重新在上游任务上训练了这个架构,然后在各种下游任务中测试了模型的性能。
在搜索阶段使用的教师模型是 BERT 110M 的模型。教师模型和搜索出来的架构都是在 BookCorpus+English Wikipedia (16GB) 数据上进行了预训练。为了和 BERT 的12层 Transformer 对齐,超网络包含了24个子层(每一个 Transformer 层等于一层 MHA 加一层FFN)。研究员们在大量的下游任务上评估搜索出来的架构的性能,包括 GLUE 和 SQuAD 数据集,并选择了5M,10M,30M,60M参数量的架构为例,来展示搜索出来的架构效果。
研究员们首先把 NAS-BERT 搜索出来的架构和手工设计的 BERT 架构进行了对比。从表3中可以看到,NAS-BERT 在各种模型大小及延迟条件下,都超过了手工设计的 BERT 模型。
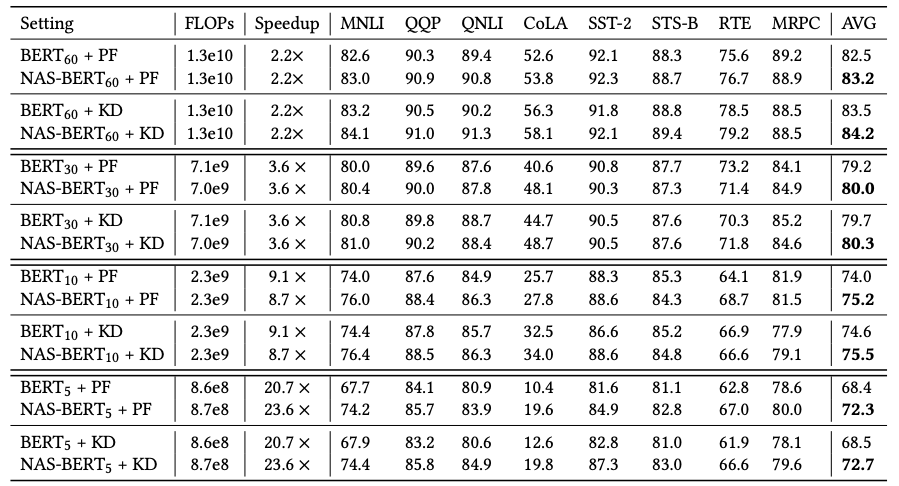
表3:NAS-BERT 和 BERT 对比
进一步,研究员们将 NAS-BERT 和之前的模型压缩工作进行对比。之前的模型压缩工作主要采用了多种蒸馏技巧和训练方式。而 NAS-BERT 只使用了简单的两阶段蒸馏来突出其搜索出的架构优势,不使用复杂的蒸馏技术或训练方法,如注意力蒸馏,逐层替换等。从表4可以看到,NAS-BERT 超过了之前的方法,证明了架构本身的优越性。
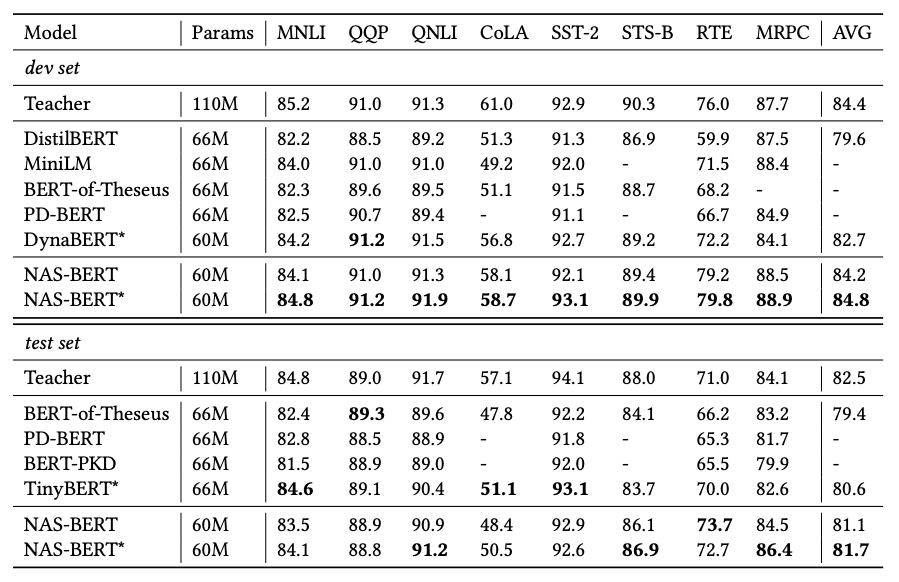
表4:NAS-BERT 和之前的 BERT 压缩工作对比
为了证明缩小搜索空间方法的有效性,研究员们又做了一组实验——与不使用逐渐缩小搜索空间进行对比。从图3的损失函数曲线来看,使用逐渐缩小搜索空间显著加快了收敛速度。从最终搜索得到的架构来看,使用逐渐缩小搜索空间能够帮助搜索到更好的架构。
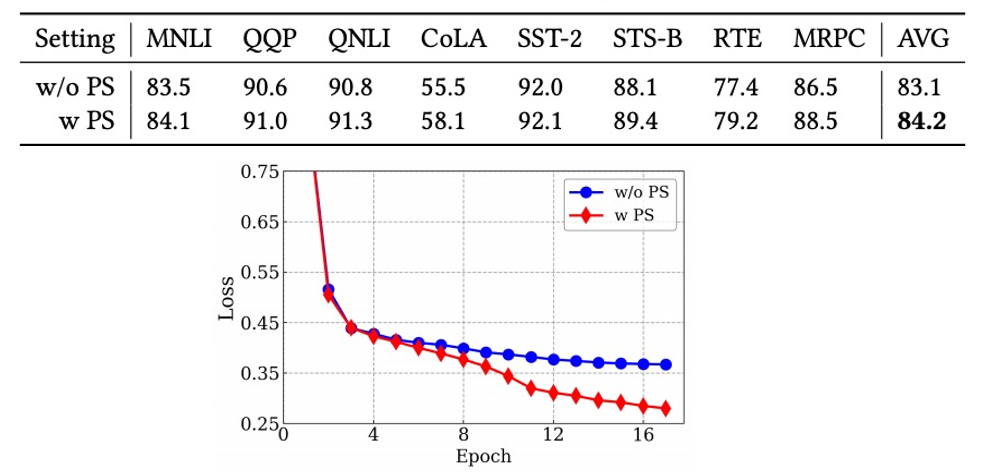
图3:逐渐缩小搜索空间的分离实验
同时,研究员们还探究了缩小搜索空间的其他方法。与从架构层面缩小搜索空间不同,研究员们尝试了从操作层面缩小搜索空间的方法(具体见论文)。从表5可以看到,从架构层面缩小搜索空间更为准确,因此能搜索到更好的架构。
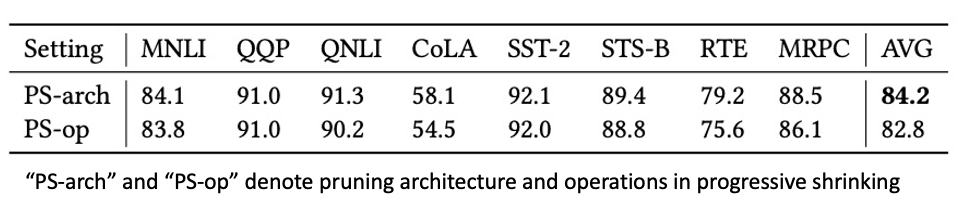
表5:不同逐渐缩小搜索空间的分离试验
最后,研究员们使用了各种不同的训练方式来训练 NAS-BERT,并将其与 BERT 模型对比,以证明搜索的架构的鲁棒性。并且研究员们还尝试了在训练过程中,在上游预训练阶段或下游微调阶段或两者都有的情况下,观察 NAS-BERT 搜索的架构的鲁棒性。从表6中可以看到,NAS-BERT 在各种训练配置上,都能显著超过手工设计的 BERT 架构。
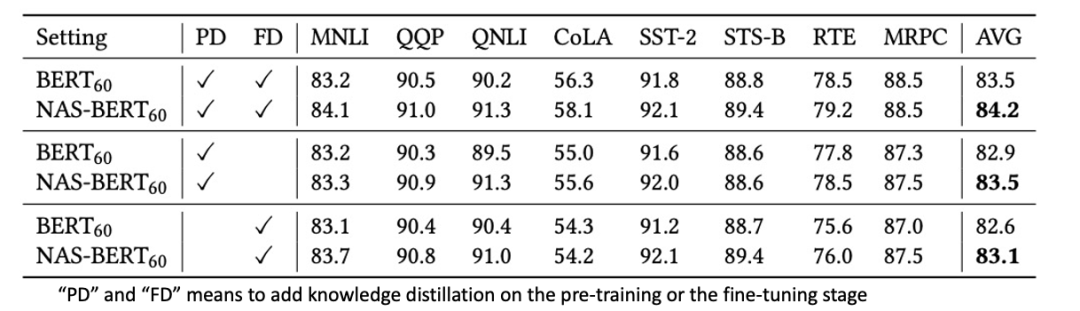
表6:不同训练方式的分离实验
表7展示了部分 NAS-BERT 搜索得到的架构。可以发现,搜索出来的架构都由不同的操作且复杂的方式组成,这证明了 NAS-BERT 能够搜索出更加新颖的新架构。
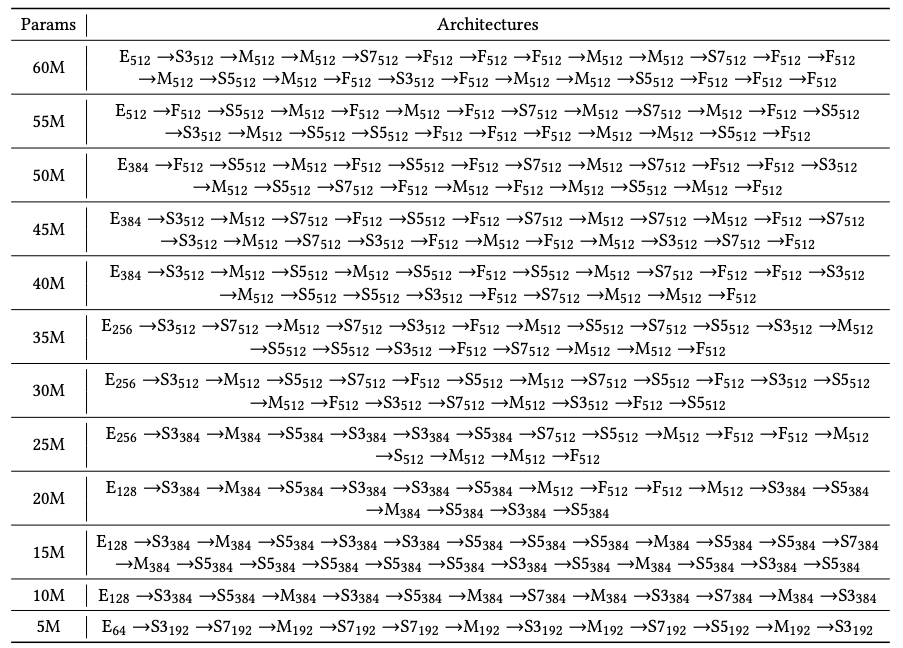
表7:部分 NAS-BERT 搜索得到的架构
微软亚洲研究院的研究员们在本篇论文中提出的 NAS-BERT,是一种用自动架构搜索方法实现任务无关且动态调整尺寸的 BERT 压缩技术。其拥有新颖的搜索空间、卷积、注意力、前馈网络以及不同的隐藏层大小。加上高效的搜索方法,NAS-BERT 可以探索出不同操作的复杂组合方式得到模型的潜力。研究员们通过大量的比较和分离实验,也证明了 NAS-BERT 搜索得到架构的有效性。
8月12日(本周四),我们将邀请微软亚洲研究院主管研究员谭旭,为大家深度解读语音合成综述论文 “A Survey on Neural Speech Synthesis”,届时欢迎大家扫码观看。

你也许还想看:









