手把手教你构建量化因子分析体系
挖掘Alpha因子、评价Alpha因子、改进Alpha因子是量化投资者职业生涯永恒的奋斗目标,而一套严密有效的因子分析体系是这一切的基石。“不以规矩,不能成方圆”,没有系统的因子分析体系,Alpha研究举步维艰,难以筑起量化研究的高楼。
萝卜投资结合国内外量化研究经验,从量化投资者实际需求出发,构建了一套包含因子统计分析、IC分析、分组测试等模块的完整因子分析体系,是投资者进行Alpha研究的利器。下面我们按照投资流程来看看如何构建因子分析体系。
Alpha因子的预处理
不论是基本面因子、技术面因子,亦或是一致预期或者舆情因子,都是基于某种逻辑计算出来的数据结果,可能存在不适合进行因子分析的数据特征,同时我们希望因子的分析结果可以横向比较,因此我们在对Alpha因子进行评价分析前需要进行标准化的“预处理”,主要步骤包括:
◆ 去极值:顾名思义,是对因子中异常值的处理,例如PE因子可能会由于分母的earning过小导致其PE出现极端大值,这些异常值会干扰后续因子中性化(回归)以及IC分析的结果,因此我们需要进行去极值,萝卜投资的winsorize模块提供了如下几种去极值方法:
a)3σ法则:正态分布去机制,将截面上处于均值±3σ之外的因子值拉回;
b)分位数法:根据p-value将截面上因子值最大与最小的p-value/2按比例拉回;
c)中位数法:
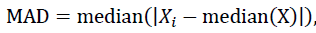
将中位数±5MAD的因子值拉回。
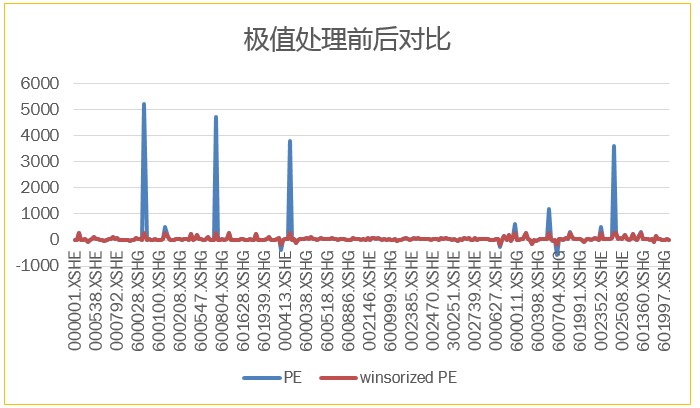
上图是以某期PE为例的去极值效果,在不改变因子结构的基础上对异常值进行了拉回,方便后续因子分析研究。
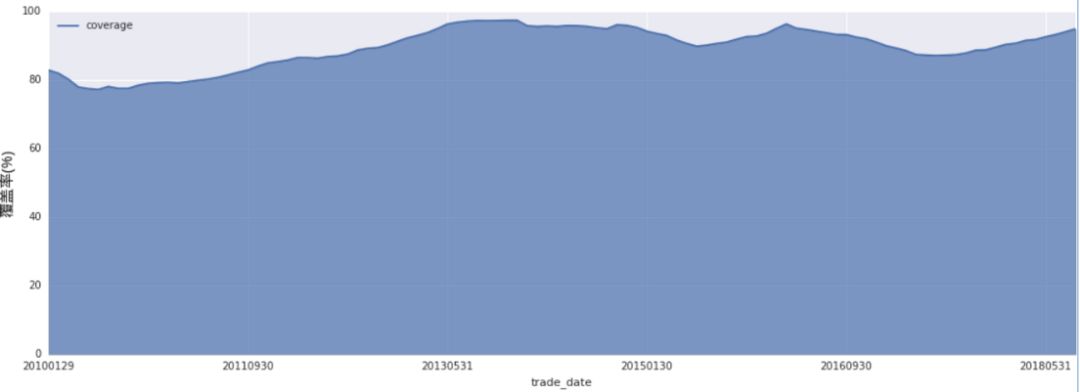
◆ 缺失值填充:另一类常见的问题是缺失值,一般而言,我们希望因子的空缺值越少越好,我们用因子覆盖率来衡量空缺值的数量:

标准化的价量交易型数据空缺值较少,因子覆盖率一般在90%以上,但部分基本面因子、一致预期、舆情因子的因子覆盖率较低,在一定场合下需要填充,我们一般采取中位数替代法、历史数据替代法进行填充,当然在部分情境下也会直接剔除缺失值的股票。
在单因子体系中主要的预处理就是去极值和缺失值填充,中性化处理视量化投资者的需求而定,并非必要;而标准化方法主要是为了统一因子间的量纲从而方便因子合成,在因子分析部分暂不涉及。
Alpha因子的基本描述
Alpha因子的基本描述结果由analyse_general接口产生,我们以某一Alpha信号为例,主要包含以下统计描述结果:
◆ 信号整体分布情况:描述因子的统计特征

◆ 信号在时间序列上的分布情况:(该因子做了截面上的标准化处理,因此每期的均值都为0,标准差都为1)
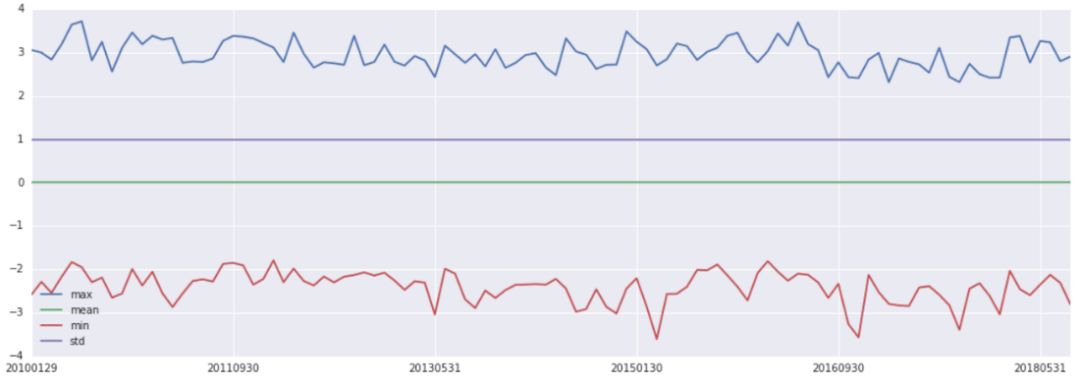
◆ 信号在投资域上的覆盖率:考察因子空缺比例及在时间序列上的变化
Alpha因子的IC分析

IC指标旨在衡量Alpha因子对于下一期收益的预测能力:
a)当IC值为正,表明因子值和未来收益正相关,例如净利润增长率,值越大代表股票未来收益越好;
b)当IC值为负,表明因子值和未来收益负相关,例如PE,值越小代表股票未来收益越好。
由此可见IC的方向不重要,重要的是IC的绝对值,在萝卜投资中我们可以利用analyse_IC模块实现对IC的分析,主要包含如下维度:
◆ IC相关描述统计

a)该示例因子的IC值为-0.078,对于单个因子而言,这个IC绝对值比较高;
b)波动率指的是区间内IC值的标准差,我们期望好的Alpha因子的IC值应该相对稳定,波动越小越好,这样的因子才能拥有稳定的选股能力;
c)胜率分析部分是对IC正/负向的统计描述,示例因子的负IC期数高达90%,且负IC的绝对值均值较大,波动率较小,说明负向IC很稳定。
综上,我们可以初步判定该因子的确具有不错的收益预测能力。
◆ IC时序图
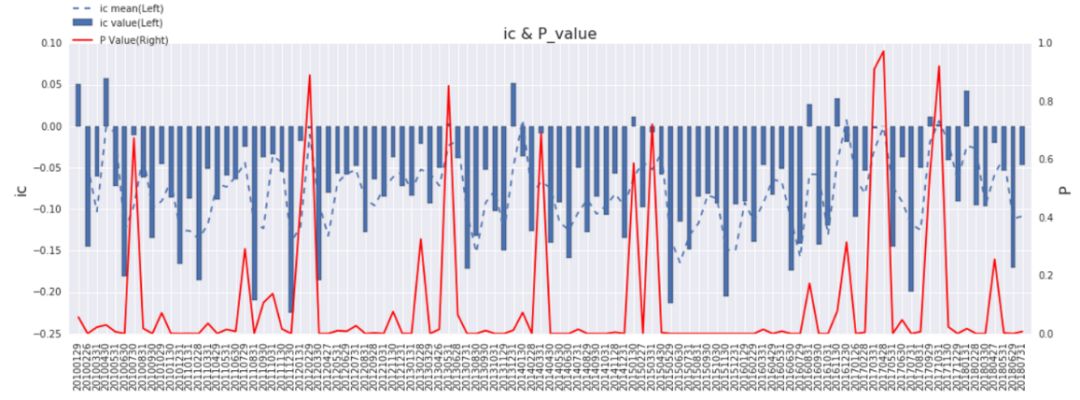
a)IC时序图中蓝色的柱子对应左侧坐标轴,代表的是每期的IC值,与上述负IC值占比一致,可以更直观地了解IC值在时间序列上的变化及分布;
b)蓝色的虚线代表IC的滚动平均值,用于观测IC时序上的走势;
c)红线代表每期的IC值t检验的p-value(右轴),p-value越接近0说明当期的IC值在统计意义上显著,即代表当期Alpha因子的确有收益预测能力。
◆ 分行业IC
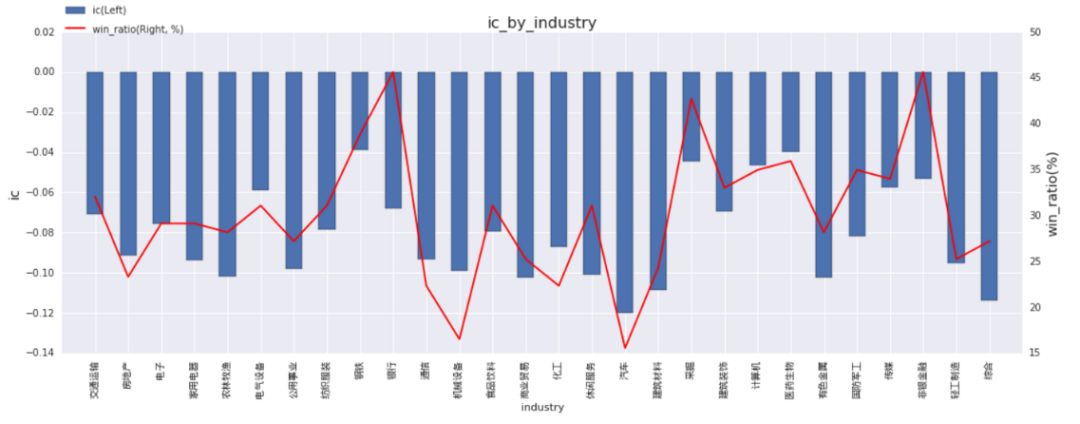
考虑到因子可能在不同行业的适用性差异,我们在IC分析体系中计算了分行业的IC值,反映的是因子在各个申万一级行业内的选股效果,图中的红线则是代表在区间内该行业内IC的胜率,示例因子在商业贸易、汽车、建筑材料等行业内的选股效果相对更好(IC绝对值>0.10),在传媒、非银金融等行业的选股效果相对一般。
◆ 分市值IC
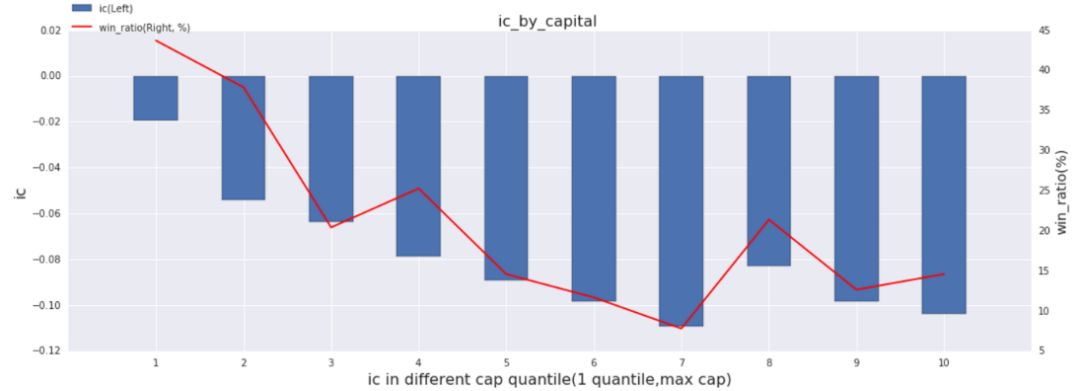
市值是A股重要参考分类,Alpha因子在不同市值股票上的表现可能会存在差异,举个最简单的例子,分析师一致预期因子在大盘股中的收益预测能力会明显强于小盘股,因此我们引入了分市值IC来考察因子在不同市值中的预测效果,示例因子的分市值IC图中说明(quantile1代表市值最大的那组),该因子在大盘股中的选股效果显著弱于小盘股,因此我们将该因子用于在小盘股中进行选股效果会更好。
◆ IC衰减分析
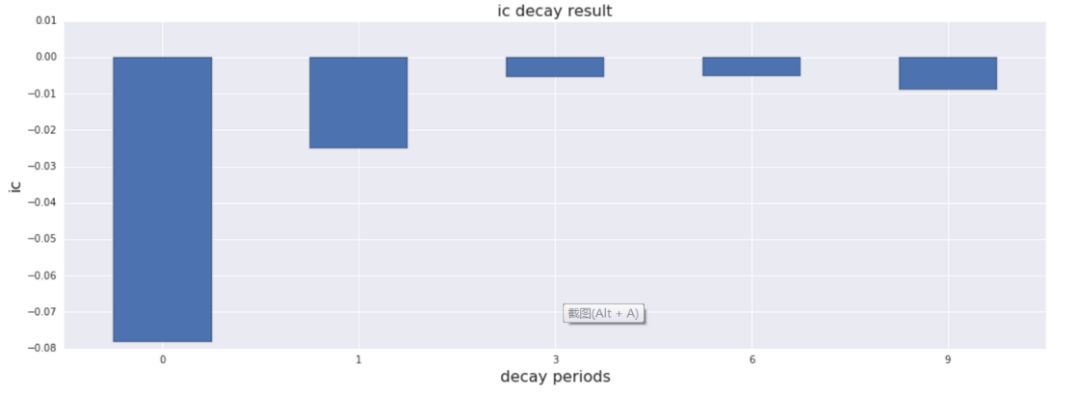
IC衰减分析考察的是因子选股能力的时效性,以1期为例说明,这个IC代表的是在t期计算的因子在t+1期进行收益预测的IC值,IC的衰减期数可供投资者自由定义,如果单个因子的IC值衰减过快(IC的绝对值下降过快),可能会导致组合较高的换手,交易成本会大幅侵蚀模型的盈利能力,本例中的频率为月频,可以看到,滞后一期的IC下降特别显著,说明以该因子构建的选股策略的换手会相对较高,同时也意味着根据该因子构建的选股策略的调仓频率不宜太低。
Alpha因子的分组测试
上一节我们展示了萝卜投资上的因子IC评价体系,IC体系简洁明了,一步相关性计算就能体现出因子的选股能力,在学术界备受追捧。不过在实际投资中,我们一般把IC检验作为初步检验,深入研究更多的还是会采取分组测试的方法来检验因子的选股能力。主要是由于IC体系难以体现现实的复杂性,例如反转类因子的多头收益钝化,指标收益非线性;交易费用对于收益的实际侵蚀等。这些问题只有落实在组合中才能得到回答,萝卜投资中的analyse_return模块能够帮助投资者完成分组测试分析,具体包含如下维度:
◆ 分组测试结果
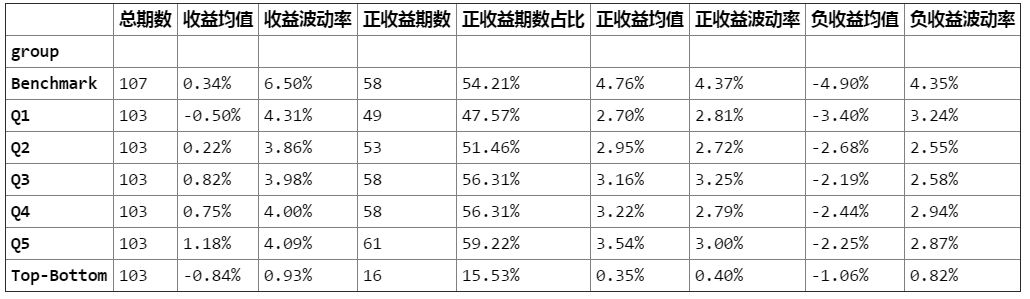
注释:
a)Q1-Qn组合:做多信号中相应部分的股票,同时减去benchmark得到的组合;
b)Q1对应的部分为信号值排在1/quantile_num的股票。
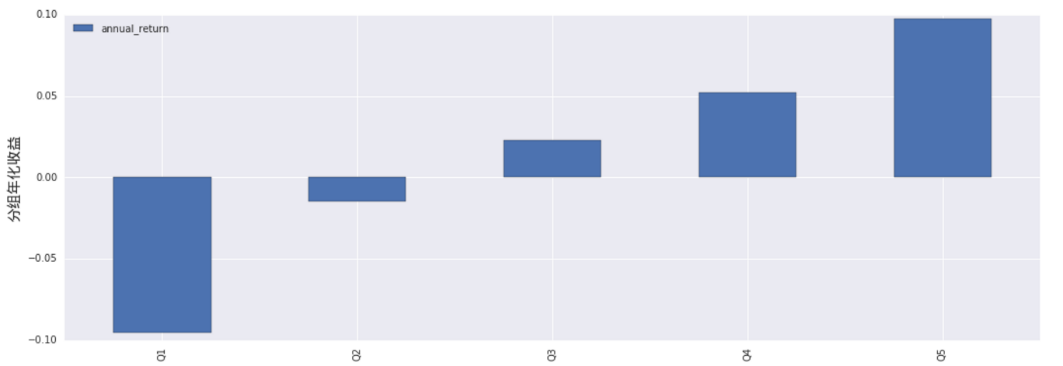
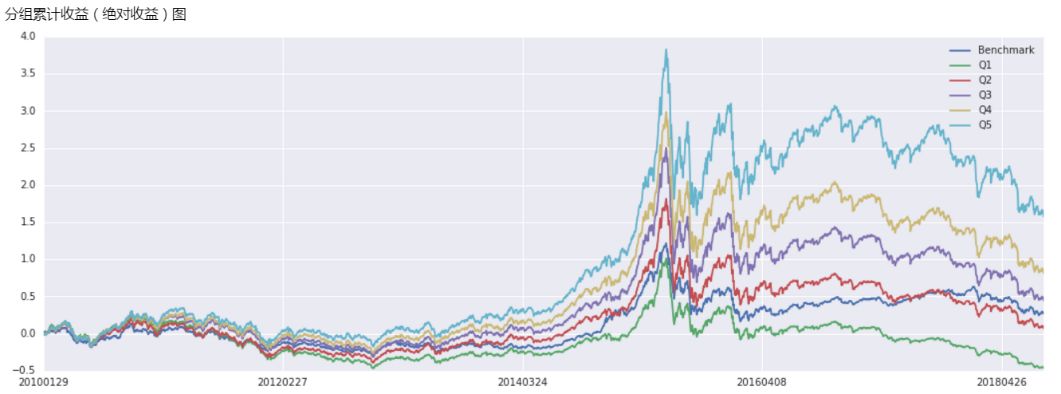
以上的一表两图构成了分组收益测试的主要部分,表中展示了分组组合的测试结果,结合两图可以直观地看出Alpha因子的选股区分度。示例因子就是一个比较优秀的选股因子,因为其各组收益率出现了明显分化,不论从年化分组均值还是分组净值曲线上都可以看到根据该因子构建的分组组合具有良好的单调性,而且根据柱状图,该因子的收益并不集中在多头/空头某一端,不存在多头收益钝化。
◆ 分组年度分析
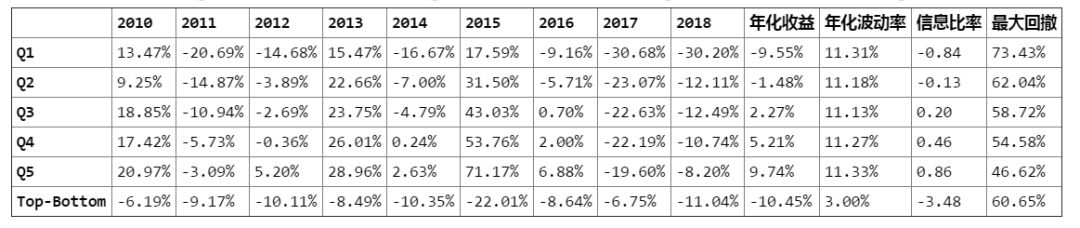
a)展示了分组测试在各年度的收益结果,主要是帮助投资者分析Alpha因子在不同市场环境下的分组表现;
b)表格的后半段展示了用于衡量分组回测表现是否优异的几项关键指标,例如因子表现最好的Q5组的年化收益为9.74%,年化波动率为11.33%,对应的信息比率(IR)为0.86,Q5组在回测区间内的最大回撤为46.62%,这些绝对指标可以辅助投资者进行因子间的对比分析。
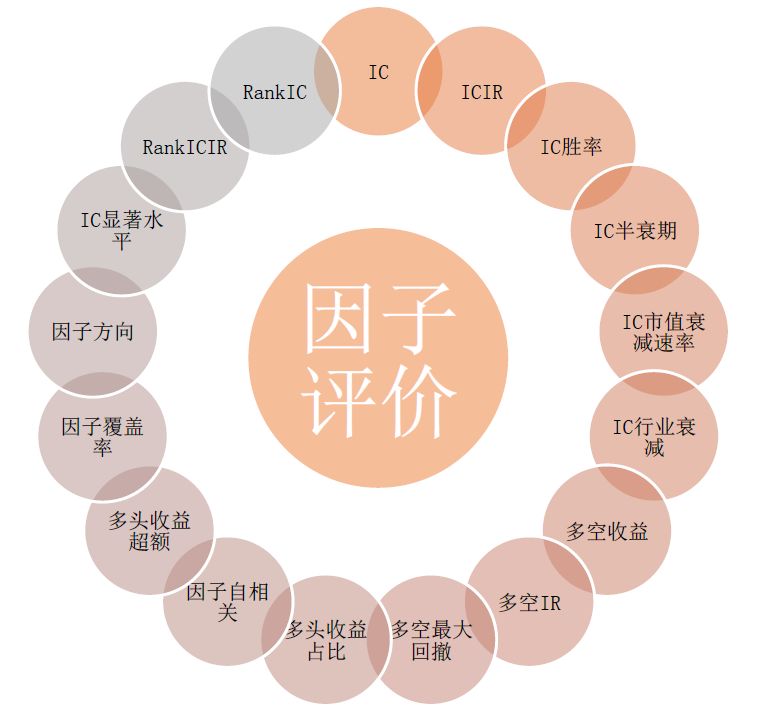
萝卜投资的因子评价主要包括IC体系和分组测试两部分,共涉及到二十余项因子评价指标,共同构建了一套完整的体系,投资者可以根据该体系全面深入地了解Alpha因子的优劣,挖掘、优化Alpha因子,做出正确的量化投资决策,让量化投资更加高效、更加便捷。
-- the end --
优矿是由通联数据出品,覆盖研究、回测、模拟、实盘交易全流程的量化平台。优矿不仅拥有通联海量的金融数据、动态丰富的策略框架,同时还通过知识库信号库提供持续的知识输出,满足用户在研究过程中高效获取、迅速验证、多维度挖掘、多策略并行的迫切需求,为投资决策提供重要支持。

扫二维码,立即预约试用!
↓↓↓ 点击"阅读原文" 【查看更多】



