ECCV22 最新54篇论文分方向整理|包含目标检测、图像分割、监督学习等(附下载)

极市导读
ECCV 2022 已经放榜,共有1629篇论文中选,录用率还不到20%。为了让大家更快地获取和学习到计算机视觉前沿技术,极市对ECCV2022最新论文进行追踪,包括分研究方向的论文及代码汇总。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
- 检测
- 分割
- 图像处理
- 视频处理
- 图像、视频检索与理解
- 估计
- 目标跟踪
- 文本检测与识别
- GAN/生成式/对抗式
- 神经网络结构设计
- 数据处理
- 模型训练/泛化
- 模型压缩
- 模型评估
- 半监督学习/自监督学习
- 多模态/跨模态学习
- 小样本学习
- 强化学习检测
2D目标检测
paper:https://arxiv.org/abs/2207.06827
code:https://github.com/ucas-vg/p2bnet
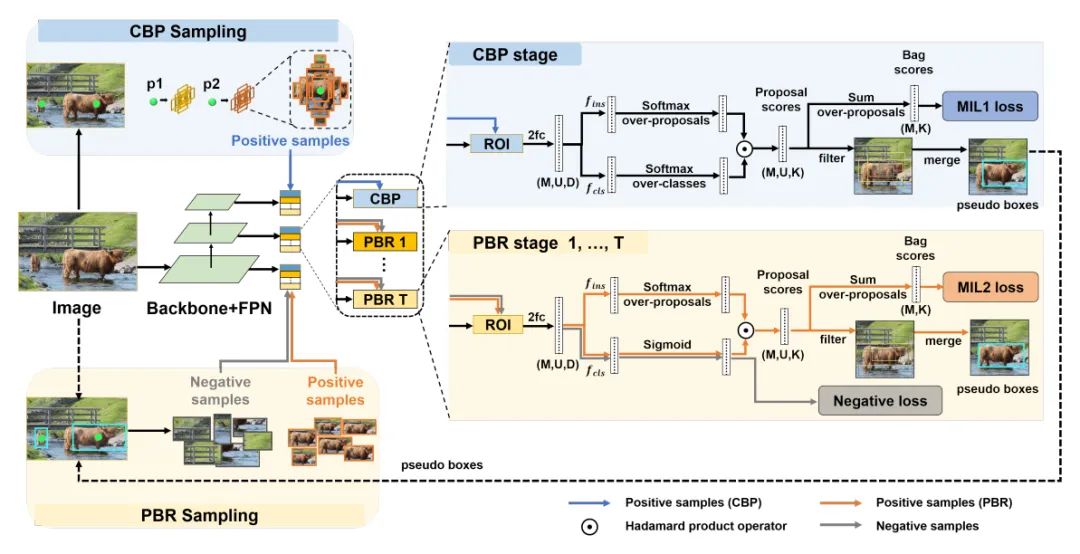
paper:https://arxiv.org/abs/2207.07889
code:https://github.com/charlespikachu/yslao
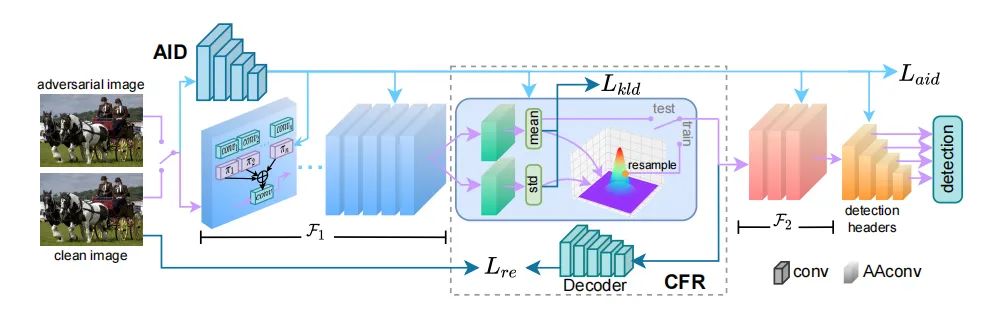
paper:https://arxiv.org/abs/2207.06202
code:https://github.com/7eu7d7/robustdet
3D目标检测
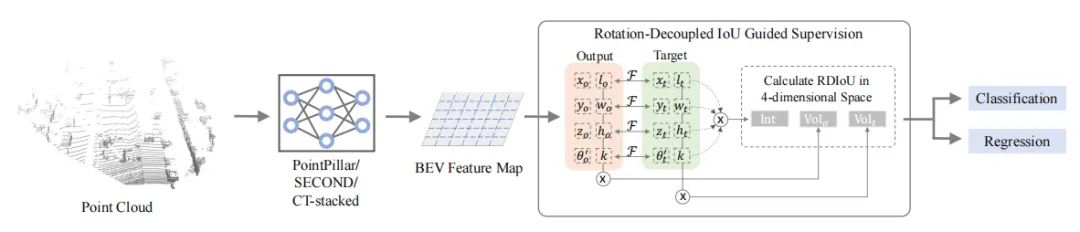
paper:https://arxiv.org/abs/2207.09332
人物交互检测
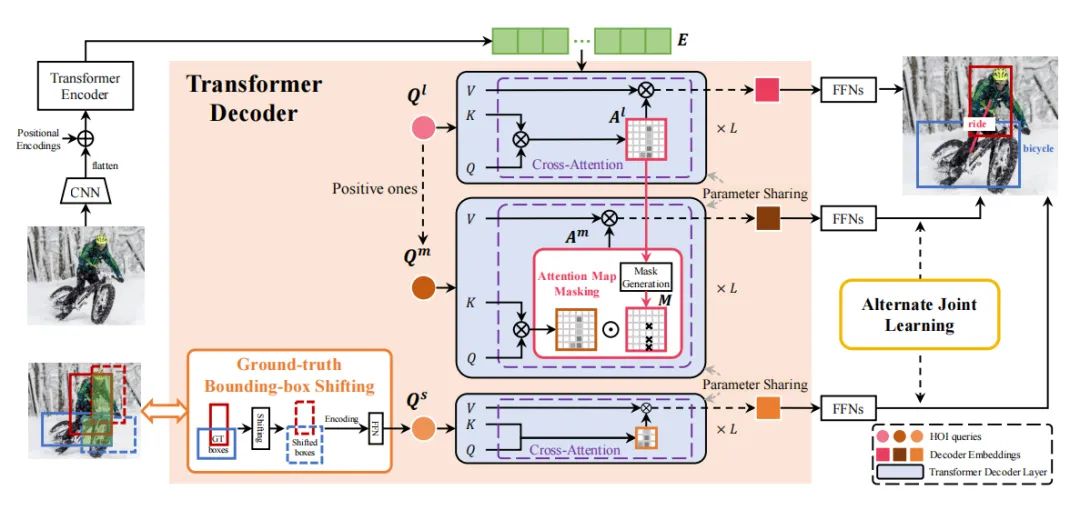
paper:https://arxiv.org/abs/2207.05293
code:https://github.com/muchhair/hqm
图像异常检测
paper:https://arxiv.org/abs/2111.09805
code:https://github.com/deeplearning-wisc/dice
分割
实例分割
paper:https://arxiv.org/abs/2207.09055
paper:https://arxiv.org/abs/2207.02255
code:https://github.com/pjlallen/osformer
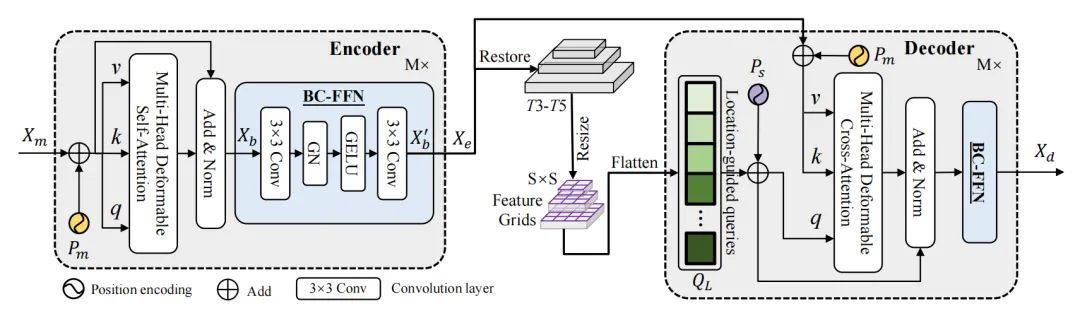
语义分割
paper:https://arxiv.org/abs/2207.04397
code:https://github.com/yanx27/2dpass
视频目标分割
paper:https://arxiv.org/abs/2207.07922
code:https://github.com/workforai/qdmn
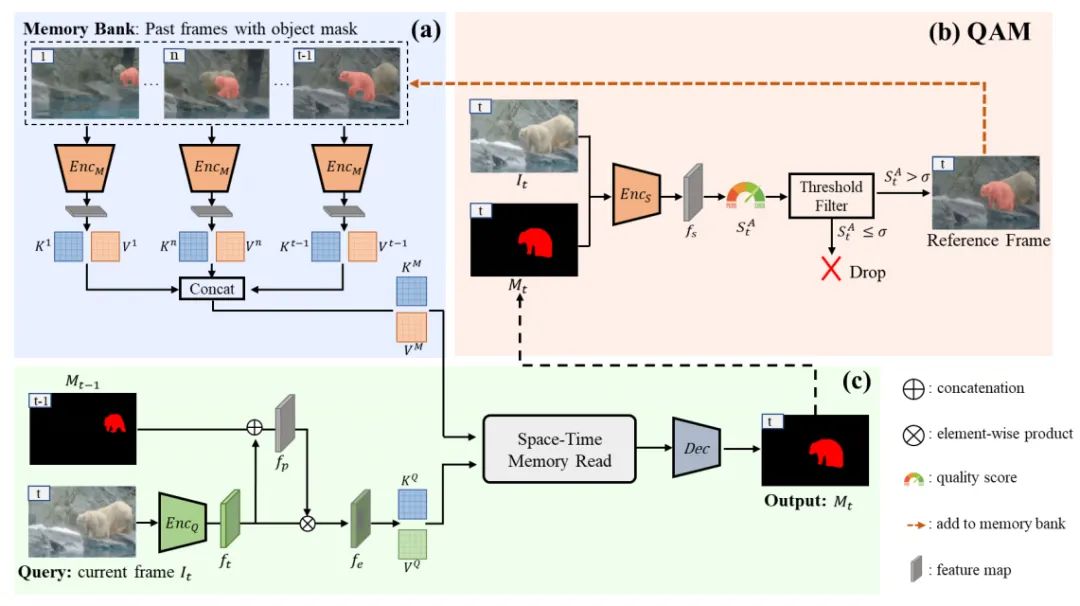
图像处理
超分辨率
paper:https://arxiv.org/abs/2203.03844
code:https://github.com/zysxmu/ddtb
图像去噪
paper:https://arxiv.org/abs/2207.09302
图像复原/图像增强/图像重建
paper:https://arxiv.org/abs/2112.01335
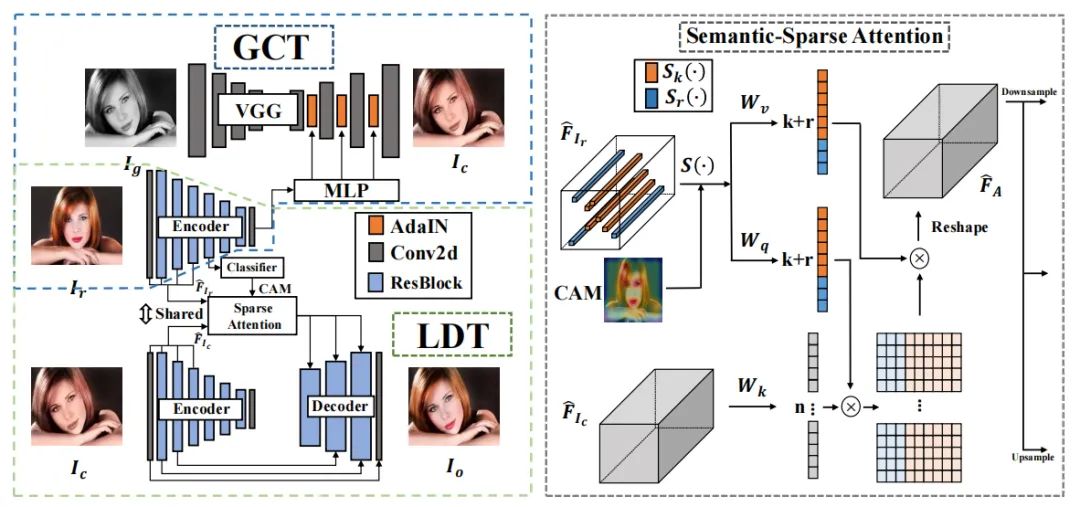
paper:https://arxiv.org/abs/2207.04750
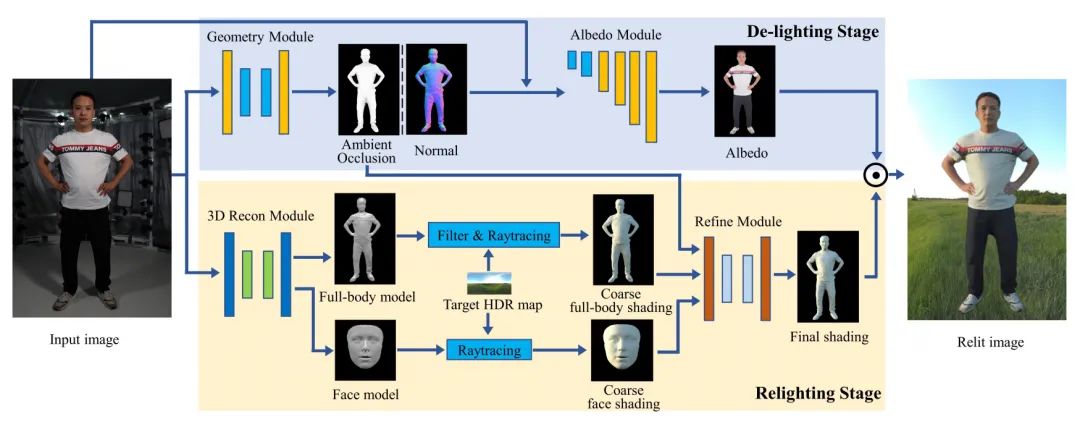
paper:https://arxiv.org/abs/2203.09855
paper:https://arxiv.org/abs/2203.09283
paper:https://arxiv.org/abs/2207.01769
paper:https://arxiv.org/abs/2107.13802
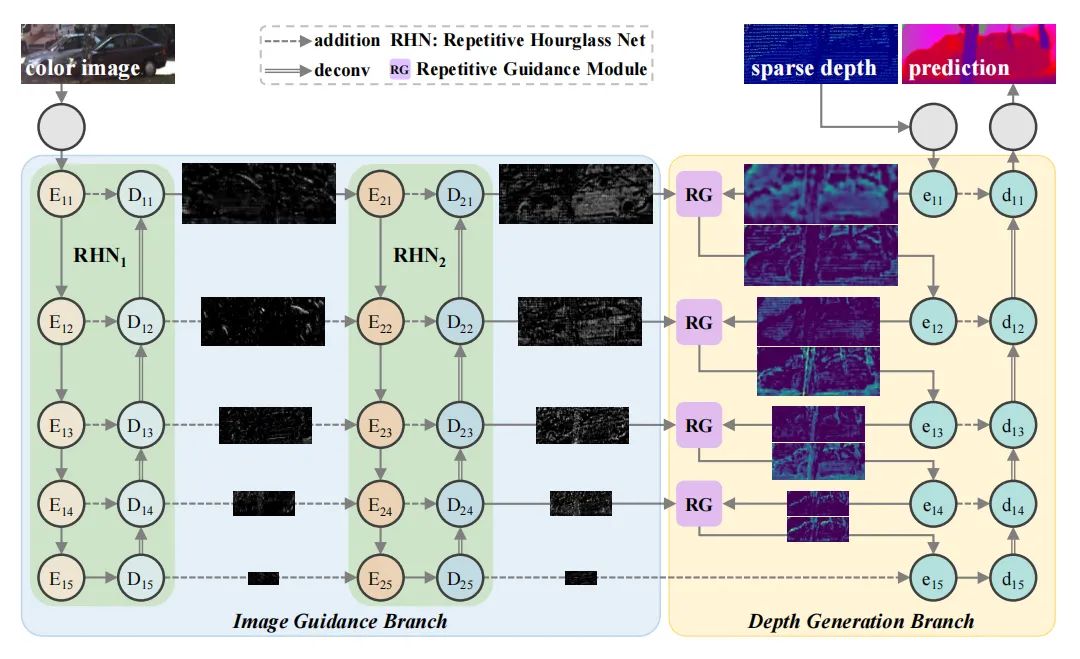
图像外推(Image Outpainting)
paper:https://arxiv.org/abs/2207.05312
code:https://github.com/kaiseem/queryotr

风格迁移(Style Transfer)
paper:https://arxiv.org/abs/2207.04808
code:https://github.com/JarrentWu1031/CCPL
视频处理(Video Processing)
paper:https://arxiv.org/abs/2111.12792
code:https://github.com/shuhongchen/eisai-anime-interpolator
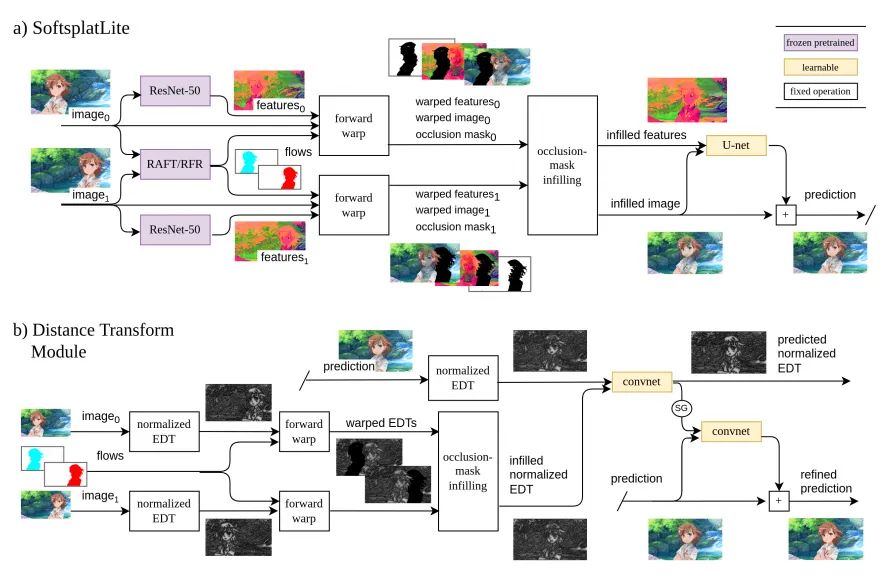
paper:https://arxiv.org/abs/2011.06294
code:https://github.com/MegEngine/arXiv2020-RIFE
图像、视频检索与理解
动作识别
paper:https://arxiv.org/abs/2207.07097
code:https://github.com/sssste/react
paper:https://arxiv.org/abs/2207.05254
视频理解
paper:https://arxiv.org/abs/2207.01375
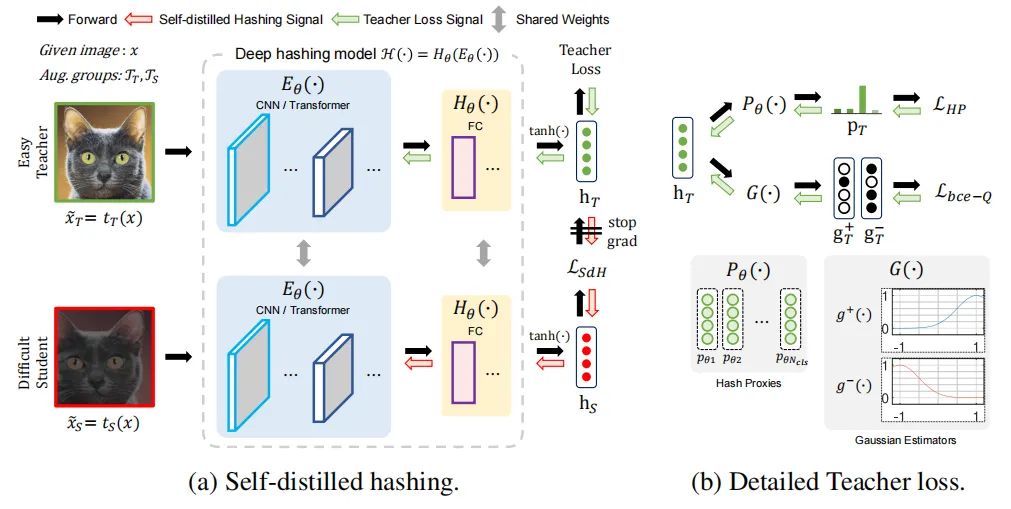
paper:https://arxiv.org/abs/2112.08816
code:https://github.com/youngkyunjang/deep-hash-distillation
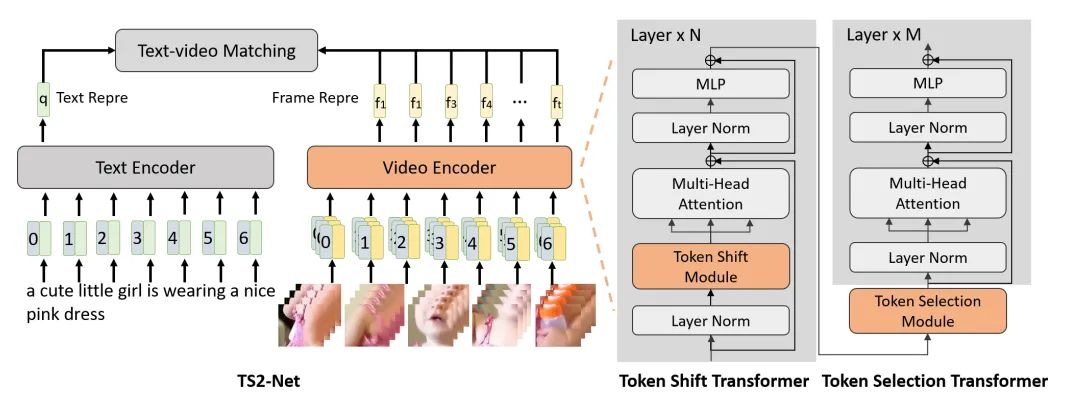
视频检索(Video Retrieval)
paper:https://arxiv.org/abs/2207.07852
code:https://github.com/yuqi657/ts2_net
paper:https://arxiv.org/abs/2112.01832
估计
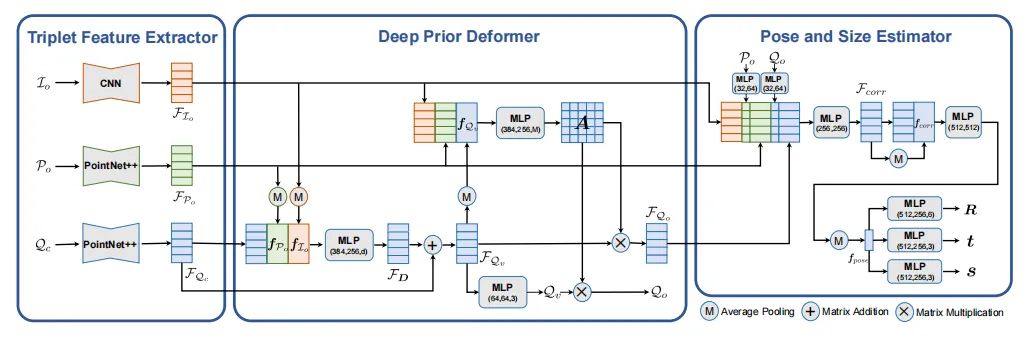
位姿估计
paper:https://arxiv.org/abs/2207.05444
code:https://github.com/jiehonglin/self-dpdn
深度估计
paper:https://arxiv.org/abs/2207.04718
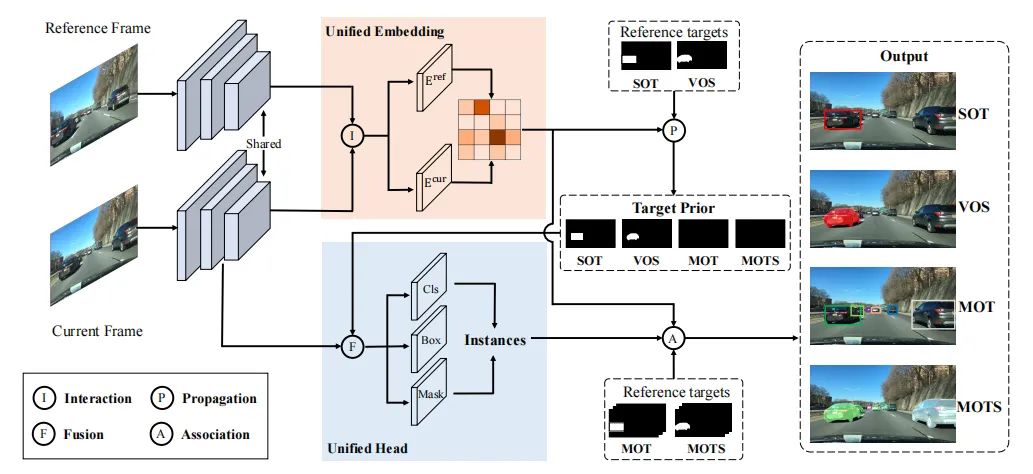
目标跟踪
paper:https://arxiv.org/abs/2207.07078
code:https://github.com/masterbin-iiau/unicorn
文本检测与识别
paper:https://arxiv.org/abs/2207.06694
code:https://github.com/hikopensource/davar-lab-ocr
GAN/生成式/对抗式
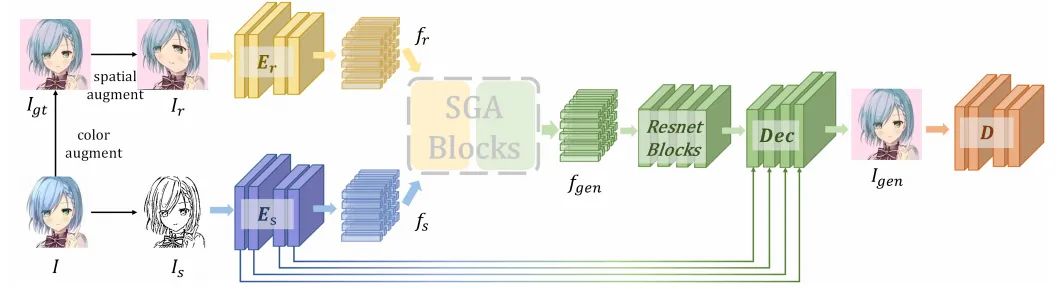
paper:https://arxiv.org/abs/2207.06095
code:https://github.com/kunkun0w0/sga
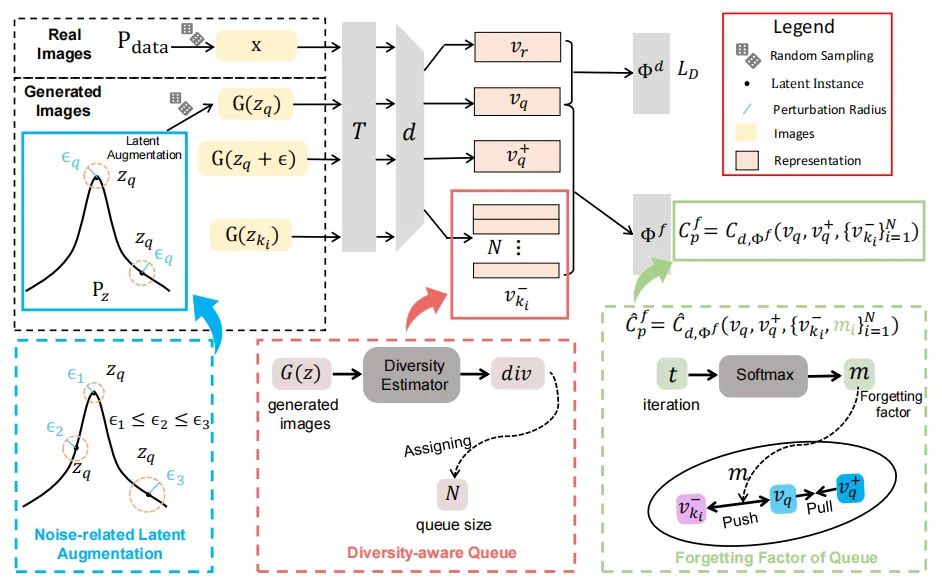
paper:https://arxiv.org/abs/2207.07288
code:https://github.com/kobeshegu/eccv2022_wavegan
paper:https://arxiv.org/abs/2207.08630
code:https://github.com/iceli1007/fakeclr
paper:https://arxiv.org/abs/2207.02152
神经网络结构设计
神经网络架构搜索(NAS)
paper:https://arxiv.org/abs/2207.07267
code:https://github.com/luminolx/scalenet
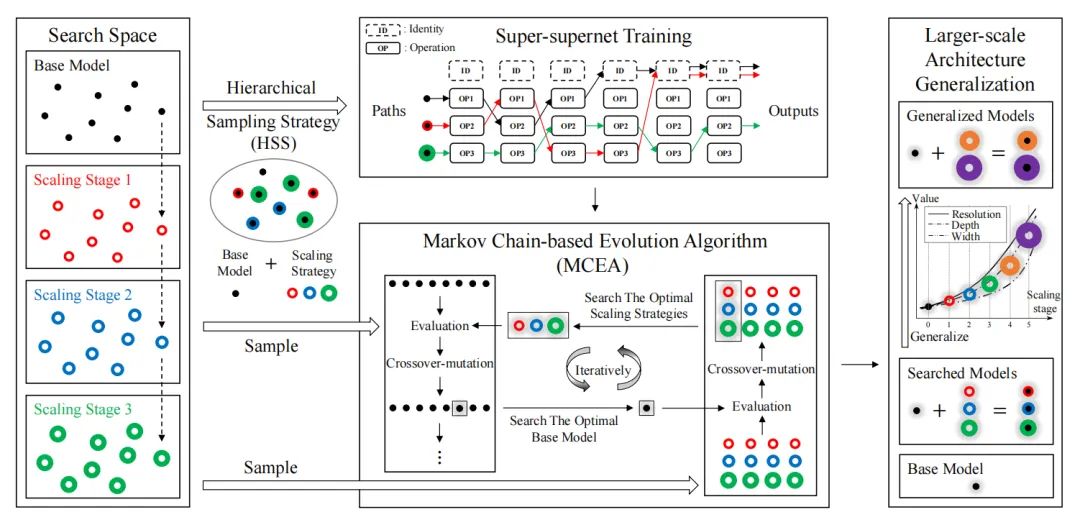
paper:https://arxiv.org/abs/2203.02651
code:https://github.com/sseung0703/ekg
paper:https://arxiv.org/abs/2111.15097
code:https://github.com/marsggbo/EAGAN
数据处理
归一化
paper:https://arxiv.org/abs/2109.04186
code:https://github.com/zysxmu/fdda
模型训练/泛化
噪声标签
paper:https://arxiv.org/abs/2111.14932
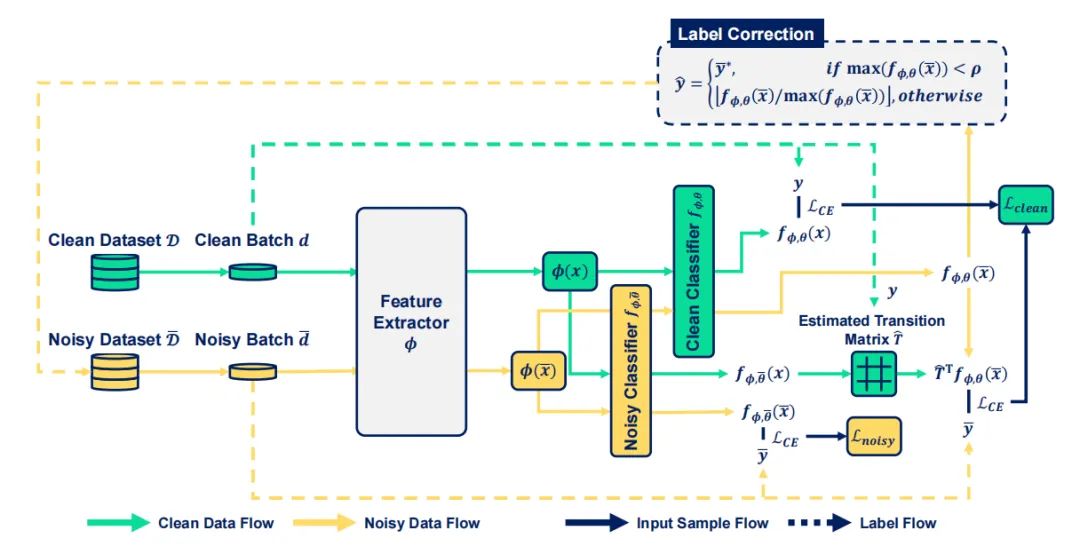
模型压缩
知识蒸馏
paper:https://arxiv.org/abs/2207.05409
code:https://github.com/dzy3/kcd)
模型评估
paper:https://arxiv.org/abs/2207.04624
code:https://github.com/d1024choi/hlstrajforecast
半监督学习/无监督学习/自监督学习
paper:https://arxiv.org/abs/2207.09158
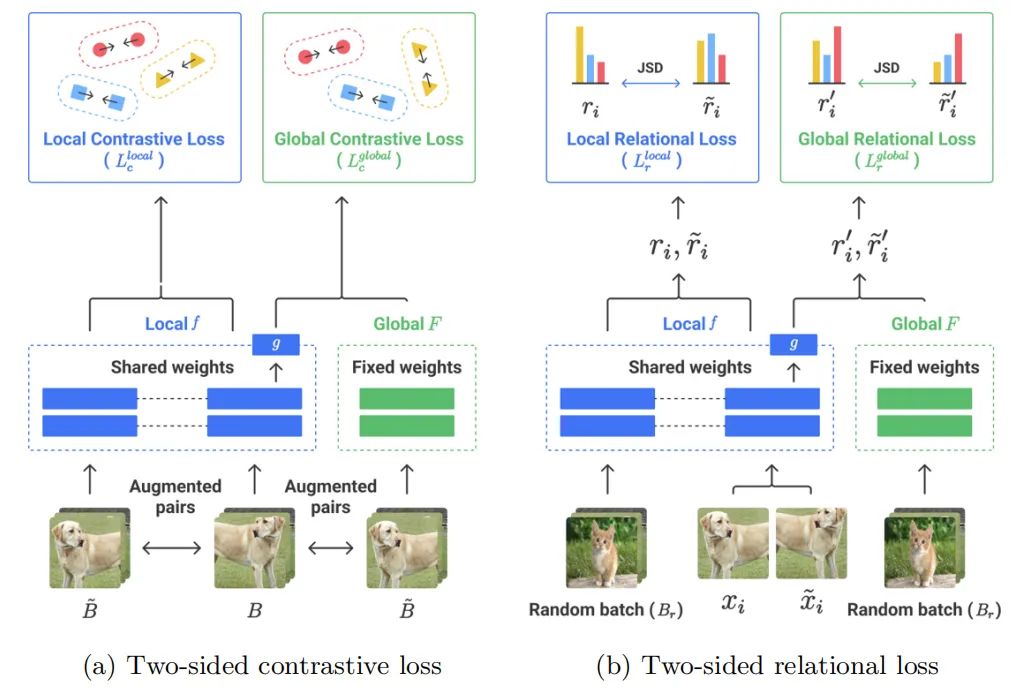
paper:https://arxiv.org/abs/2207.05432
code:https://github.com/megvii-research/ssql-eccv2022)
paper:https://arxiv.org/abs/2207.05306
code:https://github.com/archiplab-linfengzhang/contrastive-deep-supervision
paper: https://arxiv.org/abs/2207.02541
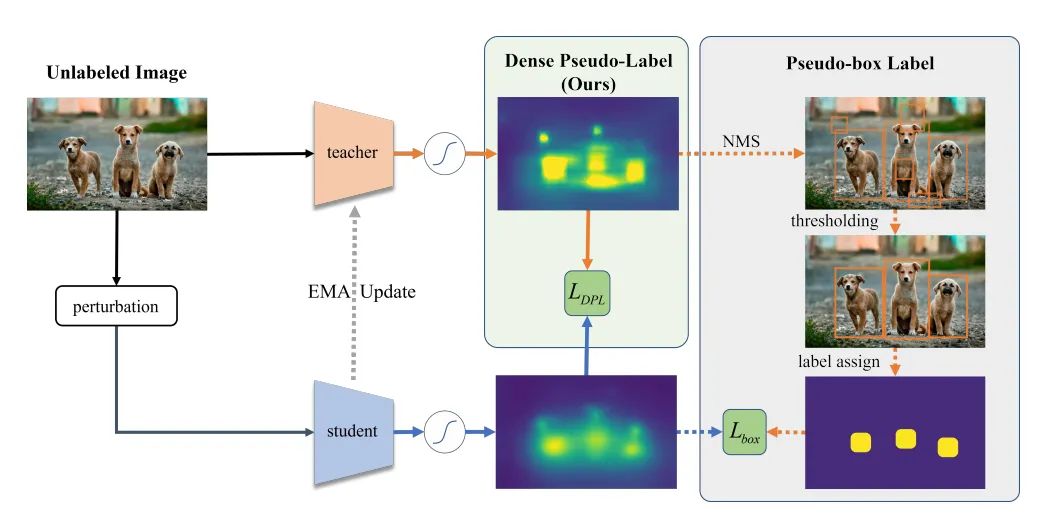
paper:https://arxiv.org/abs/2207.01932
多模态学习/跨模态
视觉-语言
paper:https://arxiv.org/abs/2112.09331
code:https://github.com/zerovl/zerovl
跨模态
paper:https://arxiv.org/abs/
code:https://github.com/markin-wang/xpronet
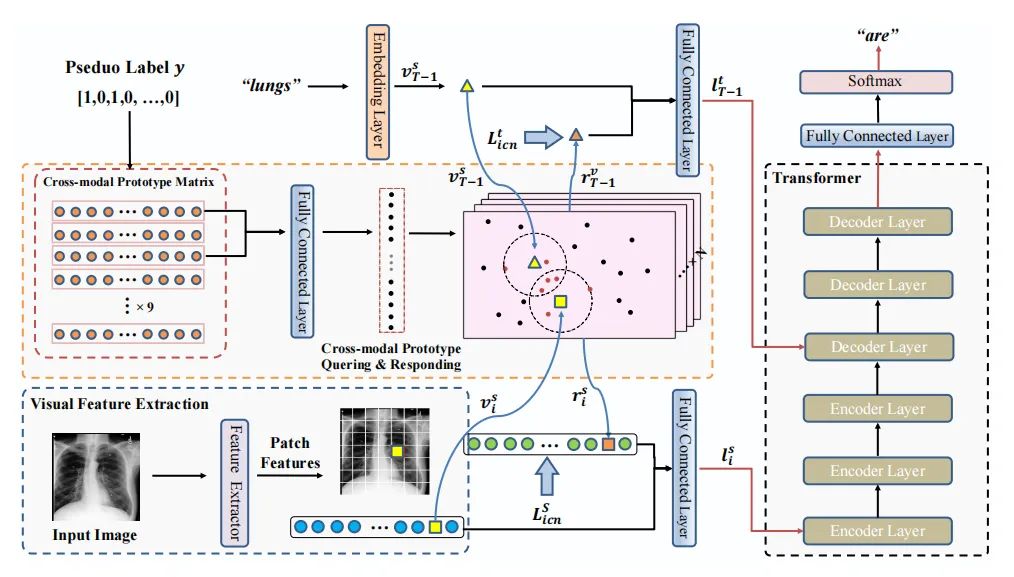
小样本学习
paper:https://arxiv.org/abs/2112.03494
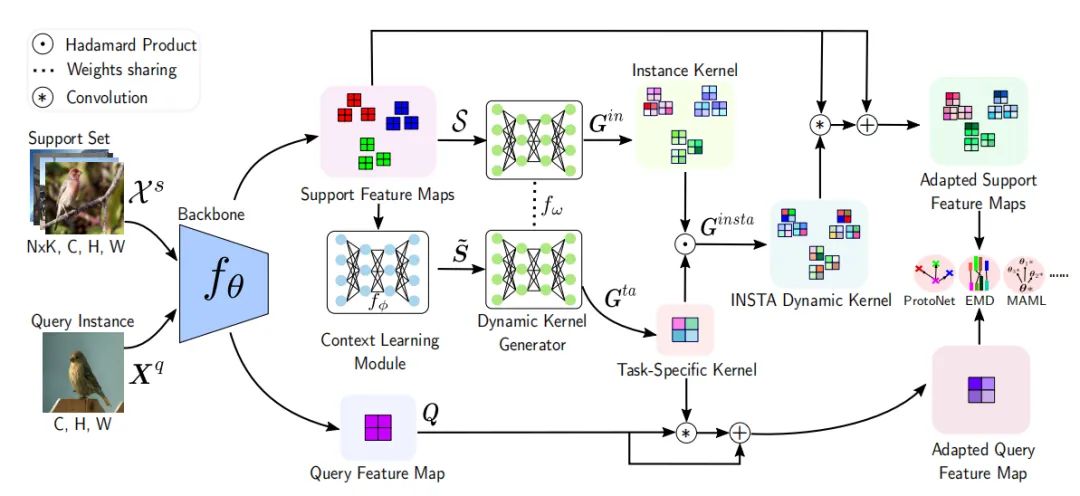
迁移学习/自适应
paper:https://arxiv.org/abs/2207.03337
code:https://github.com/adamdad/knowledgefactor
paper:https://arxiv.org/abs/2203.16244
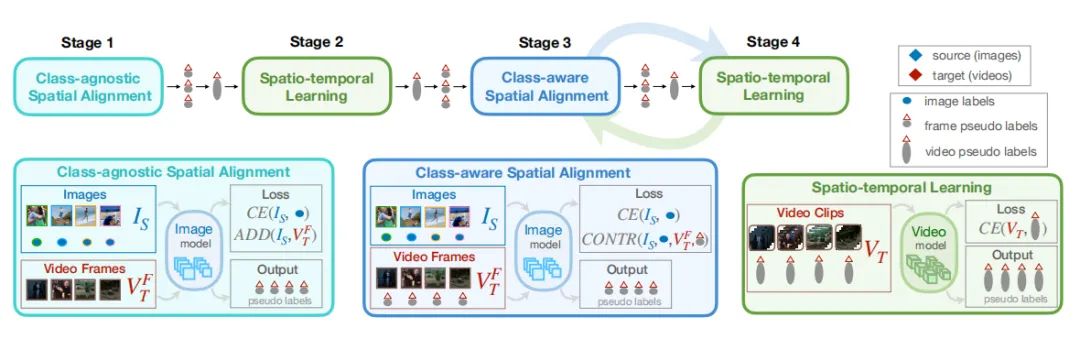
强化学习
paper:https://arxiv.org/abs/2207.01166
code:https://github.com/neouyghur/sess
公众号后台回复“ECCV2022”获取论文分类资源下载~

“
点击阅读原文进入CV社区
收获更多技术干货
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年9月19日
Arxiv
0+阅读 · 2022年9月15日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年9月19日
Arxiv
0+阅读 · 2022年9月15日