盼星星盼月亮:首期模型CPM-Ant训练完成啦!
2022 年 8 月 5 日,CPM-Live 直播训练迎来了它的第一个里程碑:
盼星星盼月亮,经过一个月的评测与打磨,我们很高兴能够在今天发布 CPM-Ant 的全部内容。
从大模型训练、微调、推理到应用,不管你是大模型研发者还是大模型技术的爱好者,相信你都能够从 CPM-Ant 的发布内容中有所收获,快来看看吧!

👀 概览
CPM-Ant 是一个开源的中文预训练语言模型,拥有 10B 参数。它是 CPM-Live 直播训练过程中的第一个里程碑。训练过程是低成本和环境友好的。基于增量微调(delta tuning)方法,CPM-Ant 在 CUGE 基准测试中取得了优异的结果。除了完整的模型,我们还提供各种压缩版本以适应不同的硬件配置。CPM-Ant 相关代码、日志文件和模型参数在一个开放的许可协议下完全开源。具体来说,CPM-Ant 具有如下特点:
-
计算高效 BMTrain[1] 工具包让我们能够充分利用分布式计算资源的能力以高效训练大模型。CPM-Ant 的训练持续了 68 天,花费了 43 万 人民币,是谷歌训练 T5-11B 模型约 130 万 美元费用的 1/20 。训练 CPM-Ant 的温室气体排放量约为 4872kg CO₂e,而训练 T5-11B 的排放量为 46.7t CO₂ e [9],我们的方案约为其排放量的 1/10 。
-
性能优异 OpenDelta [3] 工具让我们能够非常方便地通过增量微调将 CPM-Ant 适配到下游任务。在我们的实验中,CPM-Ant 仅仅 微调了 6.3M 参数 就在 3/6 个 CUGE 任务上取得了最好的结果。 这一结果超越了其他全参数微调的模型,举例来说:CPM-Ant 的微调参数量仅为 CPM2(微调了 11B 参数) 的 0.06% 。
-
部署经济 BMCook [7] 和 BMInf[4] 工具包让我们能够在有限的计算资源下驱动 CPM-Ant。基于 BMInf,我们能够替代计算集群 在单块 GPU 上进行大模型推理 (即便是一块 GTX 1060 这样的消费级显卡)。为了使 CPM-Ant 的部署更加经济,我们使用 BMCook 进一步将原始的 10B 模型压缩为不同的版本。压缩后的模型(7B,3B,1B,300M)能够 适应不同低资源场景下的需求 。 -
使用便捷 不管是原始 10B 模型还是相关的压缩版本,通过几行代码就能够轻松地加载与运行。我们也会将 CPM-Ant 加入到 ModelCenter [8] 中,对模型的进一步开发会变得更加容易。
-
开放民主 CPM-Ant 的训练过程 完全开放。我们发布了所有的代码、日志文件和模型存档并提供开放获取。CPM-Ant 也采用了允许商业化的开放许可协议。

- 官方网站二维码
To 大模型提供者
—
对于有能力进行大模型训练的厂商与研究机构,CPM-Ant 训练过程提供了一份完整的中文大模型训练实战记录。
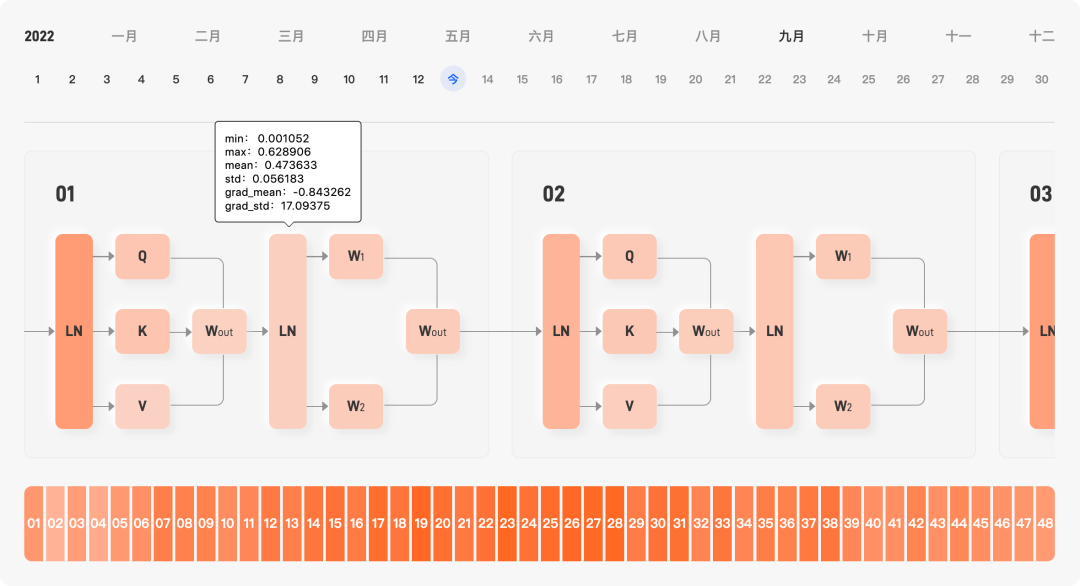
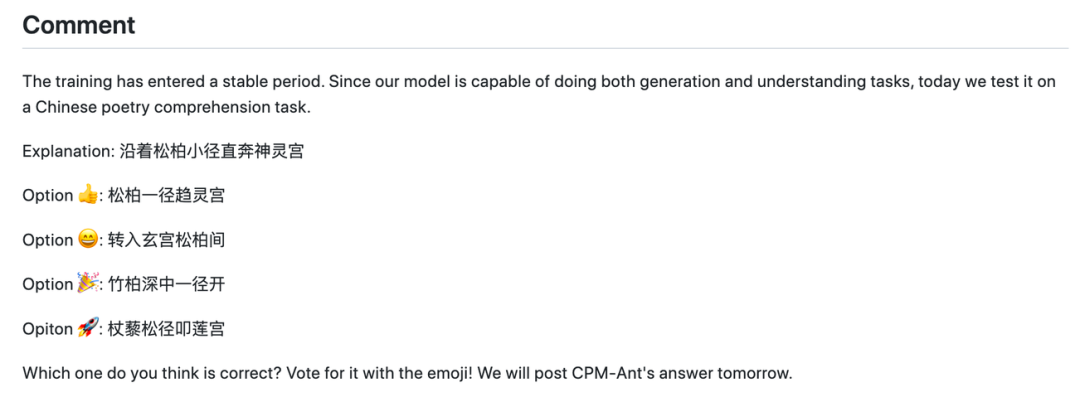
- 日志中的一次猜谜活动
除此之外,我们还提供了 成本经济 的训练方案,使用 BMTrain[1] 工具包,百亿大模型 CPM-Ant 训练的算力花费仅 43 万人民币(当前花费依照公有云价格计算,实际成本会更低),是 11B 大模型 T5 外界估算成本 130 万美元的约 1/20。对于实际有大模型训练需求的企业,通过 OpenBMB 相关训练加速技术,训练成本已经降低到可以接受的水平。
To 大模型研究者
—
具体而言,我们使用参数高效微调,即增量微调(delta tuning)来评估 CPM-Ant 在六个下游任务上的性能。我们在实验中采用了 LoRA[2],它在每个注意层中插入了两个可调整的低秩矩阵,并冻结了原始模型的所有参数。使用这种方法,我们为每个任务只微调了 6.3M 的参数,仅占总参数的 0.067%。
在 OpenDelta[3] 的帮助下,我们进行了所有的实验,而没有修改原始模型的代码。需要指出的是,在下游任务上评测 CPM-Ant 模型时,我们没有使用任何数据增强的方法。实验结果如下表所示:
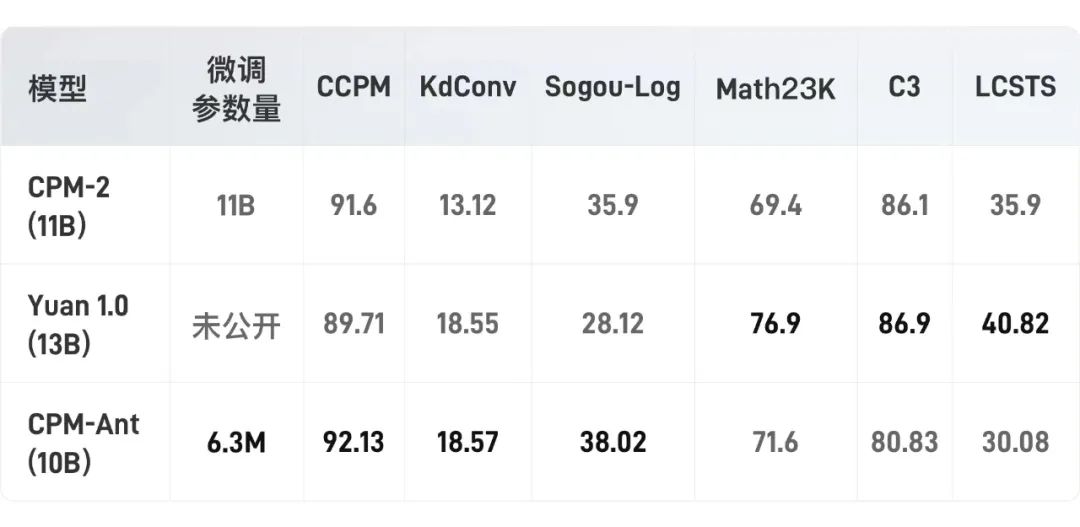
可以看到在仅微调极少参数的情况下,我们的模型在三个数据集上的性能已经超过了 CPM-2 和源 1.0。同时我们也发现,有些任务(例如 LCSTS)在微调参数极少时可能会比较难以学习。
CPM-Live 的训练过程将会继续,我们会进一步打磨 CPM-Live 在各个任务上的性能。我们也欢迎各位研究者使用 CPM-Ant 和 OpenDelta,进一步探索 CPM-Ant 在其他任务上的能力。
To 大模型使用者
一系列硬件友好的推理方式
对于大模型使用者,我们提供了一系列硬件友好的使用方式,能够较为方便地在不同硬件环境下运行不同的模型版本。
使用 BMInf[4] 工具包,使用者可以将 CPM-Ant 运行在单卡 1060 这样的 低资源环境 中。除此之外,我们还将 CPM-Ant 进行了压缩。这些压缩的模型包括 CPM-Ant-7B/3B/1B/0.3B。而所有这些模型压缩尺寸都可以对应于现有的开源预训练语言模型的经典尺寸。
考虑到用户可能会在我们发布的检查点上进行进一步的开发,我们主要使用 任务无关的结构化剪枝 来压缩 CPM-Ant。剪枝过程也是渐进的,即从 10B 到 7B,从 7B 到 3B,从 3B 到 1B,最后从 1B 到 0.3B。
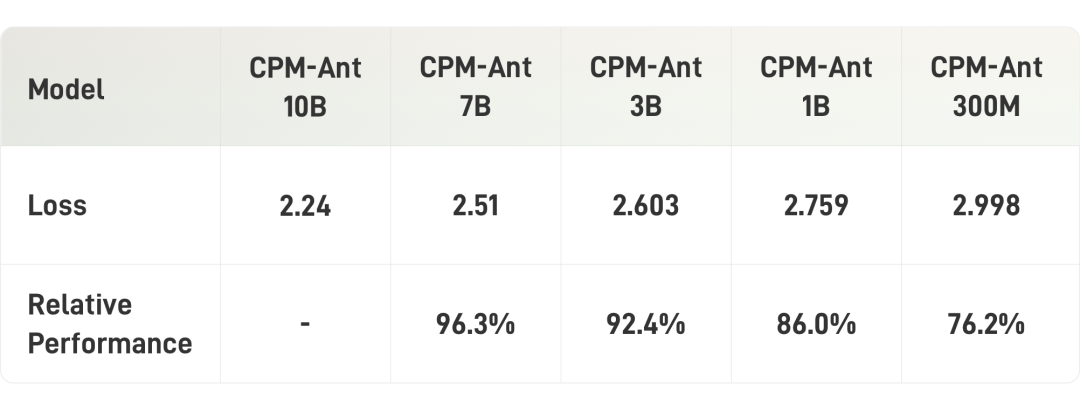
在具体的剪枝过程中,我们会训练一个 动态的可学习的掩码矩阵,然后用这个掩码矩阵来 裁剪相应的参数。最后,根据掩码矩阵的阈值修剪参数,该阈值是根据目标稀疏度确定的。更多压缩的细节可以参考我们的 技术博客[5]。下表展示了模型压缩的结果:
To 大模型开发者
对于大模型开发者与爱好者,您可以基于 CPM-Ant 开发任何 文本趣味应用。
为了进一步验证模型的有效性并提供范例,我们在 CPM-Ant 基础上微调了一个劲爆标题生成器以展示模型能力。只需要把正文内容粘贴到下方文本框,一键点击生成,就可以得到大模型提供的劲爆标题!
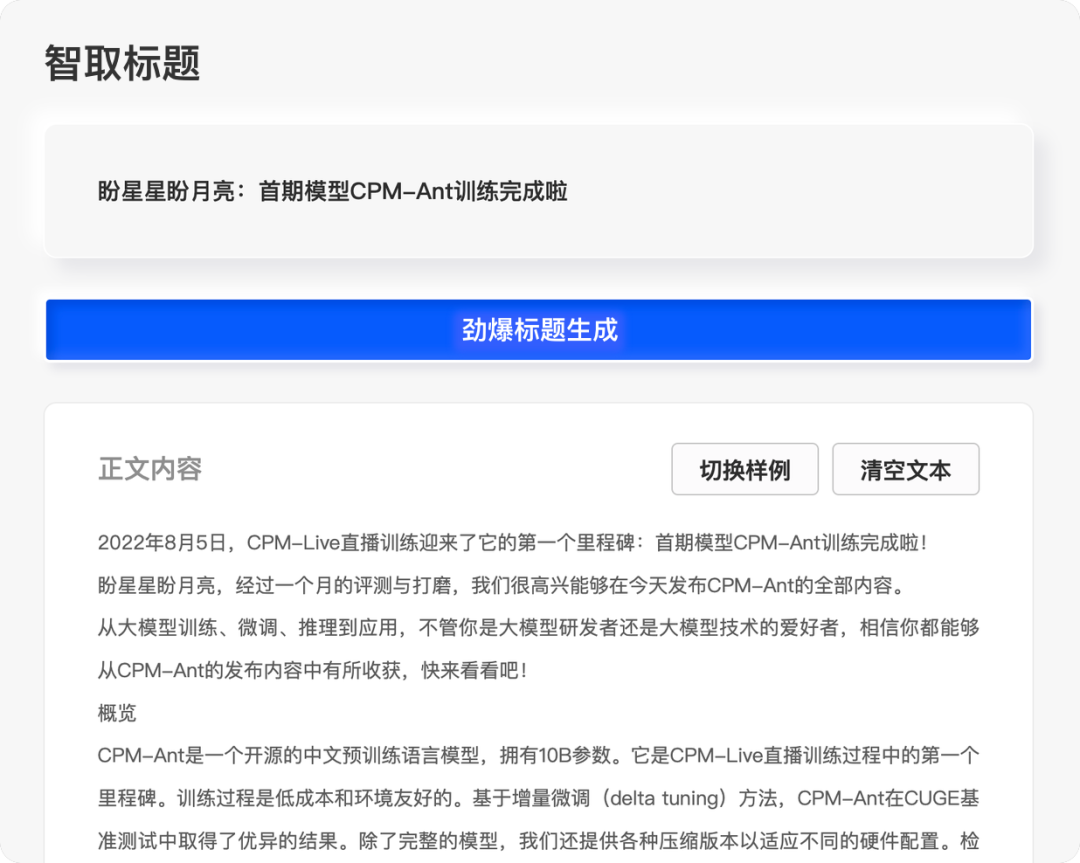
我们会不断打磨这款 demo,并且将会添加更多的功能,提高用户体验。
感兴趣的用户也可以使用 CPM-Ant 构建您自己的展示应用。如果您有任何应用想法、需要技术支持或者使用我们的 demo 遇到任何问题,欢迎您随时在我们的 论坛[6] 发起讨论!
结语&参考资料
—
作为首个直播训练中文大模型,CPM-Ant 在大模型训练、微调、压缩、推理、应用等环节均提供了一份可行的实践方案,希望能为不同的关注者提供不同的帮助与参考。
未来 CPM-Live 仍将持续学习,简单剧透一下,下一期的训练中将新增 多语言支持、结构化输入输出 等新特性,欢迎各位读者继续关注,一起为 CPM-Live 加油打 call!
关注“OpenBMB开源社区”公众号,后台回复CPM-Live,即可加入CPM-Live加油群
项目 GitHub 地址:
🔗 https://github.com/OpenBMB/CPM-Live
Demo 体验地址(仅限 PC 访问):
🔗 https://live.openbmb.org/ant
📃 参考资料
1. BMTrain:
https://github.com/OpenBMB/BMTrain
2. LoRA:
Low-Rank Adaptation of Large Language Models. ICLR 2021.
3. OpenDelta:
https://github.com/thunlp/OpenDelta
4. BMInf:
https://github.com/OpenBMB/BMInf
5. 技术博客:
https://www.openbmb.org/community/blogs/blogpage?id=98afef2ce45f4fe9a4bc15a66d7ccb92
6. CPM-Live 论坛:
https://github.com/OpenBMB/CPM-Live/discussions/categories/application-ideas-%E5%BA%94%E7%94%A8%E6%83%B3%E6%B3%95
7. BMCook:
https://github.com/OpenBMB/BMCook
8. Model Center:
https://github.com/OpenBMB/ModelCenter
9. Carbon emissions and large neural network training.
https://arxiv.org/pdf/2104.10350.pdf
