
题目: IMAGEBERT: CROSS-MODAL PRE-TRAINING WITH LARGE-SCALE WEAK-SUPERVISED IMAGE-TEXT DATA
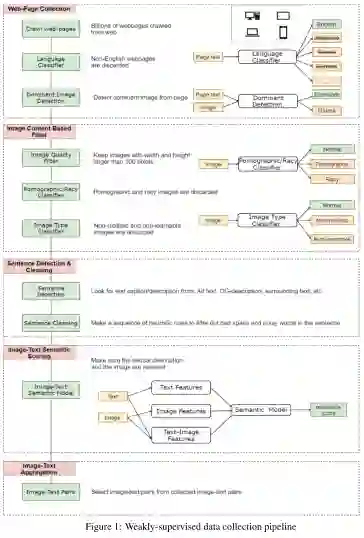
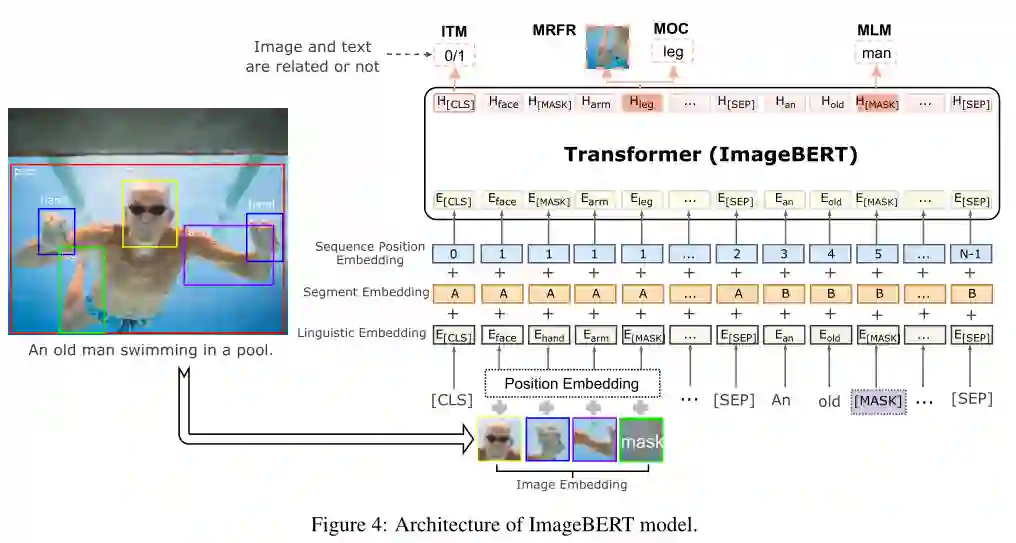
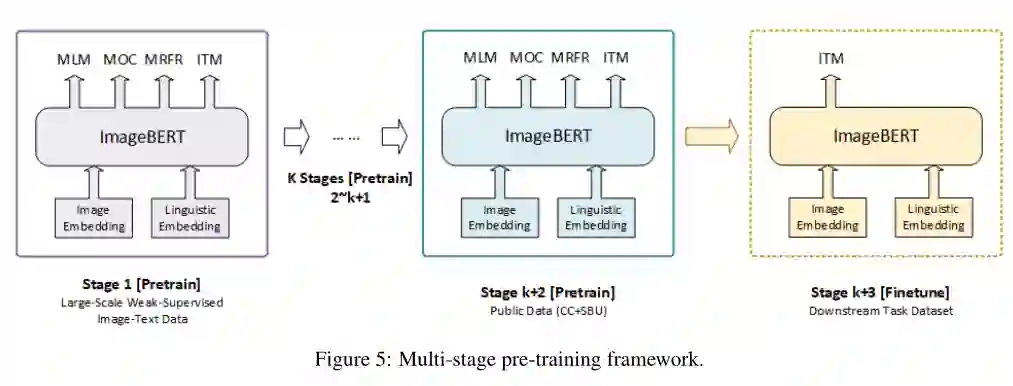
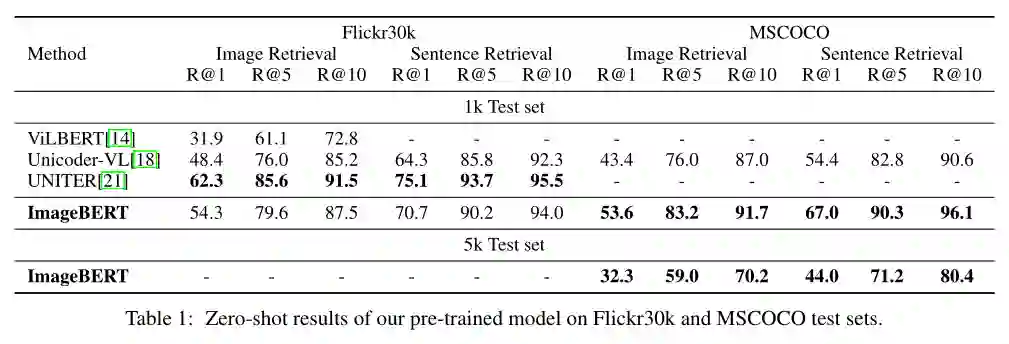
摘要: 本文介绍了一种新的用于图像-文本联合嵌入的视觉语言预训练模型图像BERT。我们的模型是一个基于Transformer的模型,它以不同的模态作为输入,对它们之间的关系进行建模。该模型同时进行了四项任务的预训练:掩蔽语言建模(MLM)、掩蔽对象分类(MOC)、掩蔽区域特征回归(MRFR)和图像文本匹配(ITM)。为了进一步提高预训练的质量,我们从Web上收集了一个大规模的弱监督图像-文本(LAIT)数据集。我们首先在这个数据集上对模型进行预训练,然后对概念字幕和SBU字幕进行第二阶段的预训练。实验结果表明,多阶段预训练策略优于单阶段预训练策略。我们还在图像检索和文本检索任务上对预先训练好的ImageBERT模型进行了调优和评估,并在MSCOCO和Flickr30k数据集上获得了最好的效果。
成为VIP会员查看完整内容


相关内容

弱监督学习:监督学习的一种。大致分3类,第一类是不完全监督(incomplete supervision),即,只有训练集的一个(通常很小的)子集是有标签的,其他数据则没有标签。这种情况发生在各类任务中。例如,在图像分类任务中,真值标签由人类标注者给出的。从互联网上获取巨量图片很容易,然而考虑到标记的人工成本,只有一个小子集的图像能够被标注。第二类是不确切监督(inexact supervision),即,图像只有粗粒度的标签。第三种是不准确的监督(inaccurate supervision),模型给出的标签不总是真值。出现这种情况的常见原因有,图片标注者不小心或比较疲倦,或者某些图片就是难以分类。
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
51+阅读 · 2020年3月7日
Arxiv
7+阅读 · 2019年2月3日
相关主题


相关VIP内容
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
51+阅读 · 2020年3月7日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年2月3日