人大金琴团队:基于Transformer的「视频-语言」预训练综述
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:AI科技评论 作者丨熊宇轩
受到基于 Transformer 的预训练方法在自然语言和计算机视觉任务上取得的成功的启发,研究人员已经开始将 Transformer 用于视频处理。本文旨在全面概述基于 Transformer 的视频-语言学习预训练方法。
本文首先简要介绍了 Transformer 的相关背景知识(包括注意力机制、位置编码等)。本文从代理任务、下游任务和常用视频数据集三个方面介绍了典型的「视频-语言」处理的「预训练-微调」范式。接下来,本文将 Transformer 模型分为单流和多流结构,重点介绍了它们的创新之处,并比较了它们的性能。最后,本文分析、讨论了「视频-语言」预训练目前面临的挑战和未来可能的研究方向。

Transformer 是一种先进的深度学习模型。与传统的深度学习网络(例如,多层感知器、卷积神经网络、循环神经网络)相比,Transformer 的架构很容易加深,且具有更小的模型偏置,更适合于「预训练-微调」范式。典型的「预训练-微调」范式是指,首先(通常以自监督方式)在大量训练数据上对模型进行训练,然后针对下游任务在较小的数据集上进行微调。预训练有助于模型学习通用表征,进而有利于下游任务。
基于 Transformer 的预训练方法首先被提出用于自然语言处理任务,并取得了显著的性能提升。Vaswani 等人于 2017 年首次提出将使用自注意力机制的 Transformer 架构用于机器翻译和英语成分句法分析任务。Devlin 等人于 2018 年提出的 BERT 是自然语言处理(NLP)领域的里程碑式工作,它用 Transformer 网络在无标签文本语料库上进行预训练,并在 11 项下游任务上取得了目前最优的性能。GPTv1-GPTv3 是一系列通用语言模型,具有不断增加的参数量,在越来越大的训练数据上训练,其中具有 1,750 万的 GPT-3 在 45TB 的压缩纯文本数据上得以训练。
受到 NLP 领域中基于 Transformer 的预训练方法的启发,计算机视觉(CV)领域的研究人员也将 Transformer 用于各类任务中。例如,Carion 等人于 2020 年提出的 DETR 基于 Transformer 网络去掉了目标检测任务中的边界框生成阶段。Dosovitskiy 等人于 2021 年提出了一个纯 Transformer 视觉模型 ViT,它直接处理图像块的序列,并在在使用大训练集训练时具有很好的图像分类性能。
由于视频天然地带有多模态信息,视频的分析与理解就更加困难。视频描述生成和视频检索是典型的「视频-语言」任务, 现有的方法重点关注如何基于视频帧序列和相应的文本描述学习视频的语义表征。本文全面地概述了基于 Transformer 「视频-语言」预训练方法的最新进展,包括对比基准相应的度量标准、各类现有的模型设计、对未来工作的探讨。
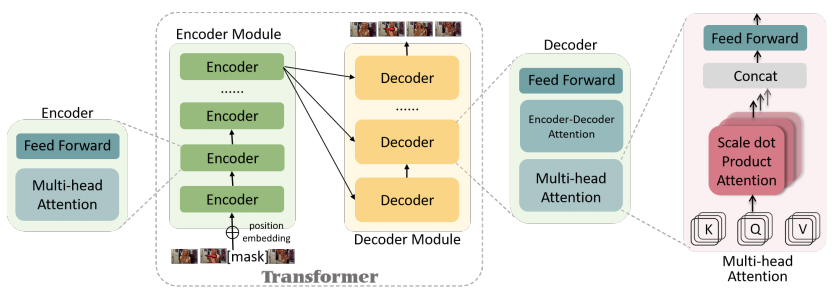
图 1:原始 Transformer 架构示意图。
Transformer 由编码器模块和解码器模块组成,上述两个模块分别包含一系列堆叠起来的编码器和解码器。每个编码器由一个多头注意力层和一个前馈网络层构成,其中前馈神经网络包含两个线性变换和一个 ReLU 激活单元。相较于编码器,每个解码器还包含一个「编码器-解码器」注意力层。多头注意力机制首先将输入序列转化为 h 组 {K,Q,V} 特征矩阵(其中,h 为注意力头数)并将每组自注意力输出结果拼接起来作为最终的输出。
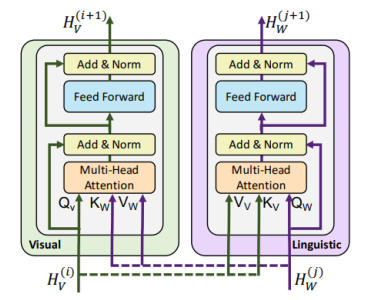
图 2:联合注意力 Transformer 层示意图。
在原始 Transformer 的基础之上,研究者们提出了各种变体来解决跨模态编码和时空编码问题。对于跨模态编码,研究者们通常将不同的模态用作跨模态交互的 Query 和 Key。ViLBERT 提出了一种联合注意力 Transformer 架构,通过交换多头注意力中的 key-value 对来构建跨模态交互。ActBERT 和 MulT 将跨模态注意力扩展到了 3 种模态的交互。就时空编码而言,由于视频同时由时间和空间维度构成,作者本质上使用 Transformer 处理单个信息序列。
还有一些研究者研究如何同时编码时间和空间信息。例如,ViViT 提出了四种将 ViT 扩展至视频处理的方法:
(1)从三维视频数据中提取不重叠的时空 token,直接输入原始的 ViT;
(2)首先对从同一时间索引中提取的图像 token 之间的交互作用进行建模,然后根据每个时间索引生成一个潜在表征;
(3)在一个单独的自注意力模块中叠加空间和时间转换器,并交替编码空间和时间维度;
(4) 通过只在空间维度或时间维度上计算点积注意力,将多头注意力分为空间头和时间头。考虑到计算成本,视频时空编码的工作主要关注将图像预训练中的知识迁移到视频相关任务中。
与卷积神经网络(CNN)和循环神经网络(RNN)相比,Transformer 的主要优势在于能够捕获全局信息,并进行并行计算。此外,Transformer 简洁、可堆叠的架构可以使大规模数据集上的训练成为了可能,从而促进了「预训练-微调」自监督学习的发展。
对于基于 Transformer 的模型来说,预训练-微调已成为一种典型的学习范式:首先在大规模数据集上采用有监督或无监督的方式进行预训练,然后再通过微调将预训练后的模型适配到更小的数据集上,用于特定的下游任务。这种范式可以避免为不同的任务或数据集从头训练新的模型。
研究表明,在更大的数据集上进行预训练有助于学习通用表征,从而提高下游任务的性能。例如,在 BooksCorpus 数据集上预训练的 NLP Transformer 模型 GPT,在 9 个下游对比基准数据集上获得了平均10%的绝对提升。视觉 Transformer 模型 ViT-L/32 在包含 3 亿张图像的 JFT-300M 数据集上进行预训练后,在 ImageNet 测试集上获得了 13% 的绝对准确率提升。
随着预训练模型在 NLP 和 CV 任务中的成功应用,越来越多的研究开始探索跨模态任务(包括「视觉-语言」和「视频-语言」)任务。视觉语言任务和视频语言任务的主要区别在于前者关注的是图像和文本模态,如基于语言的图像检索和图像描述,而后者关注的是视频和文本模态,在图像模态上增加了时间维度。
代理任务
代理任务对预训练模型最终的性能至关重要,因为它直接决定了模型的学习目标。代理任务可分为三类:填空任务、匹配任务和排序任务。
(1)填空任务旨在重建输入的被屏蔽的 token,使模型具有构建模态内或模态间关系的能力。典型的任务包括 Masked Token 建模(MLM)、Masked Frame 建模(MFM)、Masked Token 建模(MTM)、Masked Modal 建模(MMM)和语言重建(LR)。
(2)受 BERT 中 Nest Sentence Prediction(NSP)任务的启发,匹配任务旨在学习如何对齐不同的模态。例如,视频语言匹配(Video-Language Matching,VLM)是一种典型的匹配任务,旨在匹配视频和文本模态。一些研究人员还引入了音频模态来进一步匹配目标。
(3)排序任务是打乱输入序列的顺序,迫使模型识别出原始的序列顺序。例如,Frame Ordering 建模(FOM)是专门为利用视频序列的时序特性而设计的,Sentence Ordering 建模(SOM)是为文本模态而设计的。
在所有常用的代理任务中,自监督学习(SSL)是针对预训练需要大量训练数据的情况而采用的主要策略。SSL 是一种自动生成标签数据的无监督学习,它启发模型学习数据的内在共现关系。在视频语言预训练中,MLM 和 MFM 是两种广泛使用的 SSL 代理任务。
对比学习(CL)最近成为视频语言预训练的自监督学习的重要组成部分。与通过测量 L2 距离来生成 Masked Token 不同,该算法将相同的样本嵌入到彼此接近的位置,同时试图推开不同样本的嵌入的距离。
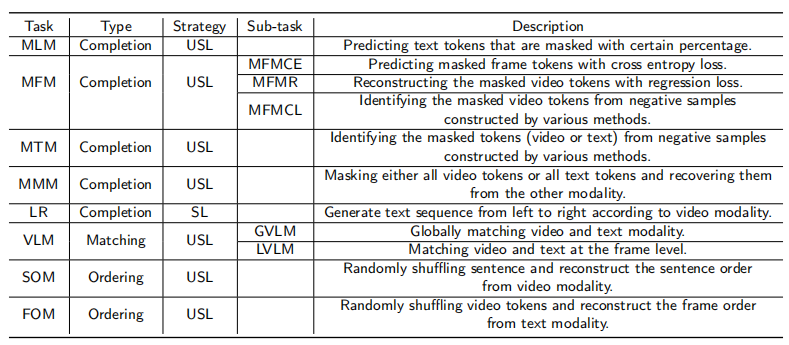
图 3:「视频-语言」预训练中的常用代理任务一览
「视频-语言」下游任务
预训练旨在通过迁移学习更好地将从大型语料库中学习到的知识适配到下游任务中。一些典型的下游任务在评估预训练模型的过程中也扮演重要的角色。为此,我们需要考虑模型的结构,并为每个下游任务选择合适的迁移方法。「视频-语言」预训练中常见的下游任务包括生成任务和分类任务:
(1)基于文本的视频检索:给定输入的文本查询,检索相关的视频/视频片段,要求模型将视频和文本模态映射到一个共同语义嵌入空间中。
(2)动作识别:对给定视频/视频片段的动作类别进行分类。
(3)动作分割:在帧的级别上预测给定视频/视频片段的动作类别。
(4)动作步骤定位:识别教学视频中的动作步骤,与动作识别的区别在于,动作步骤定位中的时间是通过人工短语描述的,而不是通过标签词典表述的。
(5)视频问答:给定上下文视频,旨在自动回答自然语言问题,分为多项任务和填空任务。
(6)视频描述:为给定的视频生成自然语言描述。
「视频-语言」数据集
与 CNN 相比,基于 Transformer 的架构严重依赖于大规模收集(尤其是对预训练而言)。视频数据集的质量和数量与模型性能息息相关。如图 4 所示,常用的视频数据集可分为:(1)基于标签的数据集(2)基于文本描述的数据集(3)其它数据集。
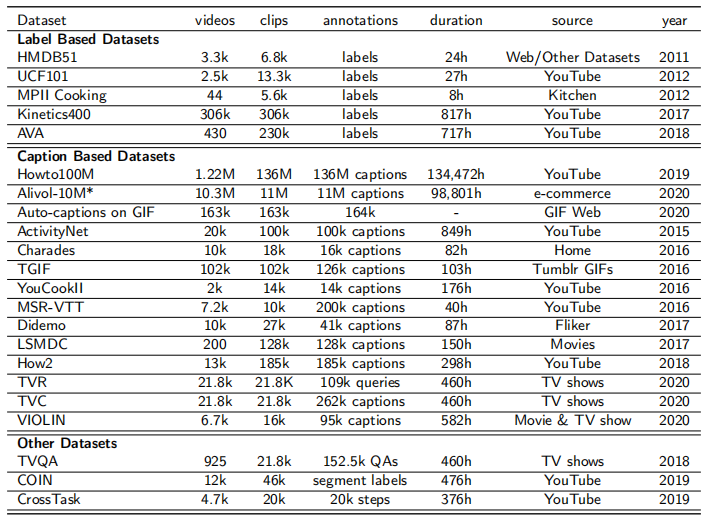
图 4:常用视频-语言预训练调优数据集。
用于「视频-语言」预训练的 Transformer 模型可分为:
(1)单流 Transformer。将不同模态的特征/嵌入输入到同一个 Transformer 中,捕获模态内核模态间的信息。
(2)多流 Transformer。将每个模态输入到独立的 Transformer 中捕获模态内的信息,通过其它方式(例如,另一个 Transformer)来构建跨模态关系。
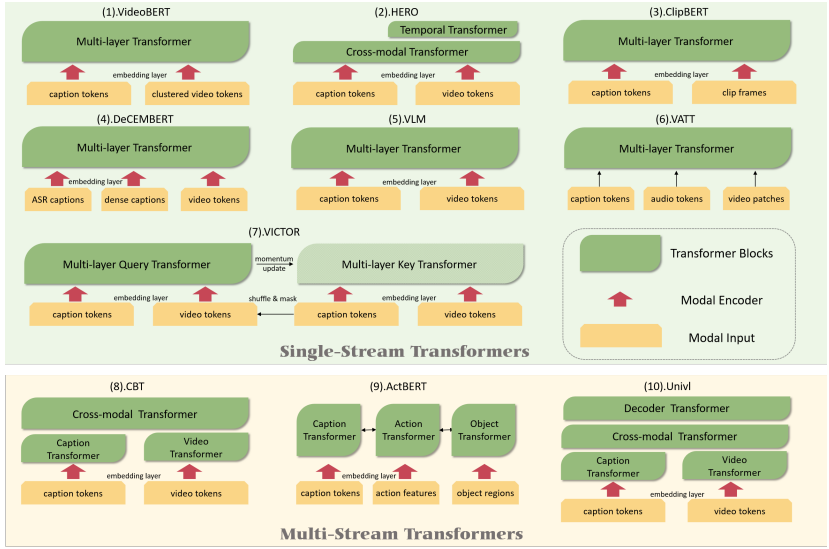
图 5:用于「视频-语言」表征学习的 Transformer 模型一览。
尽管在模型结构上存在差异,但大多数模型都将文本描述 token 和视频 token 作为输入,而 DeCEMBERT 将 ASR 文本描述作为附加文本信息,ActBERT 将对象区域作为附加视觉信息,VATT 将音频作为附加模态信息输入。大多数模型采用模态编码器来提取模态特征,而 VATT 放弃了这种方法。
不同预训练方法的输入、代理任务、下游任务、对比基准如图 6 所示:
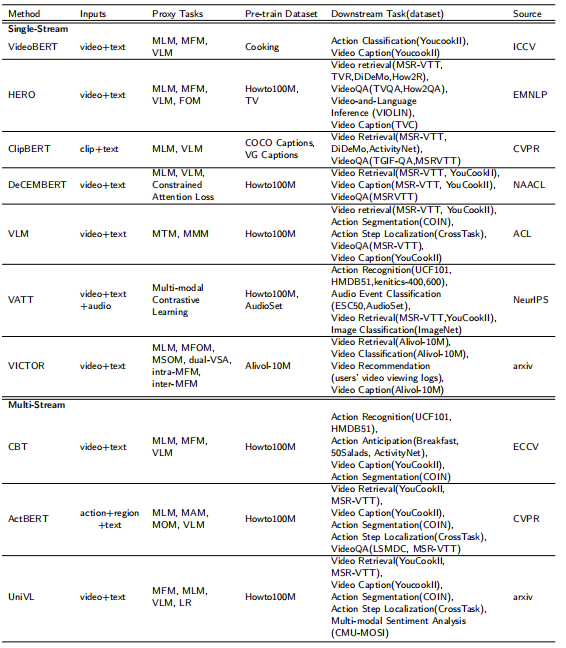
图 6:「视觉-语言」预训练方法一览
预训练已成为自然语言处理领域的流行方法,并被进一步应用于视觉任务中。与其它视觉语言预训练工作相比,视频语言领域的预训练工作较少。
本文对视频语言处理的预训练方法进行了全面的综述,首先回顾了 Transformer 相关的背景知识,然后通过介绍常见的代理任务和下游任务,总结了视频语言学习的「预训练-微调」过程。
此外,本文根据规模、标注类别等因素对常用的视频数据集进行了概述,总结了最先进的视频-语言学习 Transformer 模型,强调了其主要优势,比较了它们在下游任务中的性能。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看






