CVPR 2022 Oral | 人大高瓴AI学院提出:面向动态视音场景的问答学习机制
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
标 题:CVPR2022 Oral | 人大高瓴AI学院提出面向动态视音场景的问答学习任务
作 者:李光耀†,卫雅珂†,田亚鹏†,徐辰良,文继荣,胡迪*

你知道AI可以自己欣赏音乐会吗?而且AI可以知道演奏场景中每一个乐器的演奏状态,这是不是很神奇?对人类而言,欣赏美妙的音乐会是一件很享受的事情,但对于机器来说,如何将优美的旋律和激昂的演奏画面珠联璧合来提升欣赏体验却颇有挑战。
最近,中国人民大学高瓴人工智能学院GeWu实验室就针对这一问题提出了一种新的框架,让AI能像人一样观看和聆听乐器演奏,并对给定的视音问题做出跨模态时空推理。
目前这一成果已被 CVPR 2022 接收并选为 Oral Presentation,相关数据集和代码已经开源。
论文:https://gewu-lab.github.io/MUSIC-AVQA/static/files/MUSIC-AVQA.pdf
代码(已开源):https://github.com/GeWu-Lab/MUSIC-AVQA
项目地址:https://gewu-lab.github.io/MUSIC-AVQA/
接下来让我们一起来看一下这个有趣的工作!
1. 引言
我们在日常生活中被视觉和声音信息所包围,这两种信息的结合利用提高了我们对场景的感知和理解能力。想象一下,当我们身处在一场音乐会中时,同时观看乐器演奏动作和聆听音乐的旋律可以很好地帮我们享受演出。受此启发,如何让机器整合多模态信息,尤其是视觉和声音等自然模态,以达到与人类相当的场景感知和理解能力,是一个有趣且有价值的课题。因此,我们专注于视听问答(Audio-Visual Question Answering, AVQA)任务,旨在回答有关不同视觉对象、声音及其在视频中的关联的问题。显然,必须对视听场景进行全面的多模态理解和时空推理才能做出正确的回答。
近年来,研究人员在声音对象感知、音频场景分析、视听场景解析和内容描述等方面取得了显著进展。尽管这些方法能将视觉对象与声音关联,但它们中的大多数在复杂视听场景下的跨模态推理能力仍然有限。相比之下,人类可以充分利用多模态场景中的上下文内容和时间信息来解决复杂的场景推理任务,如视听问答任务等。现有的视觉问答(VQA)和声音问答(AQA)方法等往往只关注单一模态,从而不能很好的在真实的视音场景中进行复杂的推理任务。
如下图所示的单簧管双重奏场景,当回答“哪个单簧管先发声?”的问题时,需要在视听场景中先定位出发声的单簧管,并在时序维度上重点聚焦于哪个单簧管先发出声音。要正确回答这个问题,本质上需要有效地对视听场景理解和时空推理。

图1 AVQA任务问题样例展示
对于上面这个例子,若我们仅考虑基于视觉模态的VQA模型则很难对问题中涉及的声音信息进行处理,相反,若我们只考虑基于声音模态的AQA模型,同样难以对问题中涉及的空间位置信息进行处理。但是,我们可以看到同时使用听觉和视觉信息可以很容易的对场景进行理解并正确的回答上述问题。
2. 数据集
为了更好的探索视听场景理解和时空推理的问题,我们构建了一个专注于问答任务的大规模的视听数据集(Spatial-Temporal Music AVQA, MUSIC-AVQA)。我们知道高质量的数据集对于视音问答任务的研究具有相当大的价值,因此,考虑到乐器演奏是一个典型的视音多模态场景,并由丰富的视听成分及其交互组成,非常适合用于探索视听场景理解和推理任务。故我们从YouTube上收集了大量用户上传的乐器演奏视频,构建数据集中的视频包括了独奏、重奏的合奏等多种演奏形式。具体来说,我们一共选取了22种不同的乐器(如吉他、钢琴、二胡、唢呐等),设计了九种问题模板并涵盖了声音、视觉和视音三种不同的模态场景类型。

表1 MUCIS-AVQA数据集与其他QA数据集多维对比
如表1所示,我们发布的MUSIC-AVQA数据集具有以下优势:
1)MUSIC-AVQA数据集涵盖大量的声音问题、视觉问题和视听问题的问答对,比其他问答类数据集更全面丰富。对于大多数问答任务数据集(ActivityNet-QA, TVQA等)来说,仅包含了视觉问题,难以探索视听相关的研究。虽然现有的AVQA数据集(AVSD, Pano-AVQA等)也提供了视听问答对,但它们更专注于相对简单的问题(Existential或Location),只需要空间推理即可做出回答。
2)MUSIC-AVQA数据集由包含丰富视听成分的乐器演奏场景组成,有助于更好地研究视听交互场景理解和推理,并可以在一定程度上避免场景中的噪声问题。大多数公开问答类数据集(ActivityNet-QA, AVSD等)中的声音信息通常与其视觉对象不匹配,会产生严重的噪声(如背景音乐),这使得它们难以探索不同模态之间的关联。此外,TVQA数据集虽然包含视觉和声音模态,但其声音是由人类说话声组成的,在其问答对构建过程中也只使用了相应的字幕信息,并不是真正的视音关联场景。
最终数据集包含了9,288个视频并包含了22种乐器,其总时长超过150小时。并且以众包的形式形成了45,867个问答对,平均每个视频约5个问答对,这些问答对涵盖了不同模态下的9类问题类型以及33个不同的问题模板。丰富而多样复杂的数据集对AVQA任务的研究具有相当大的价值和意义。
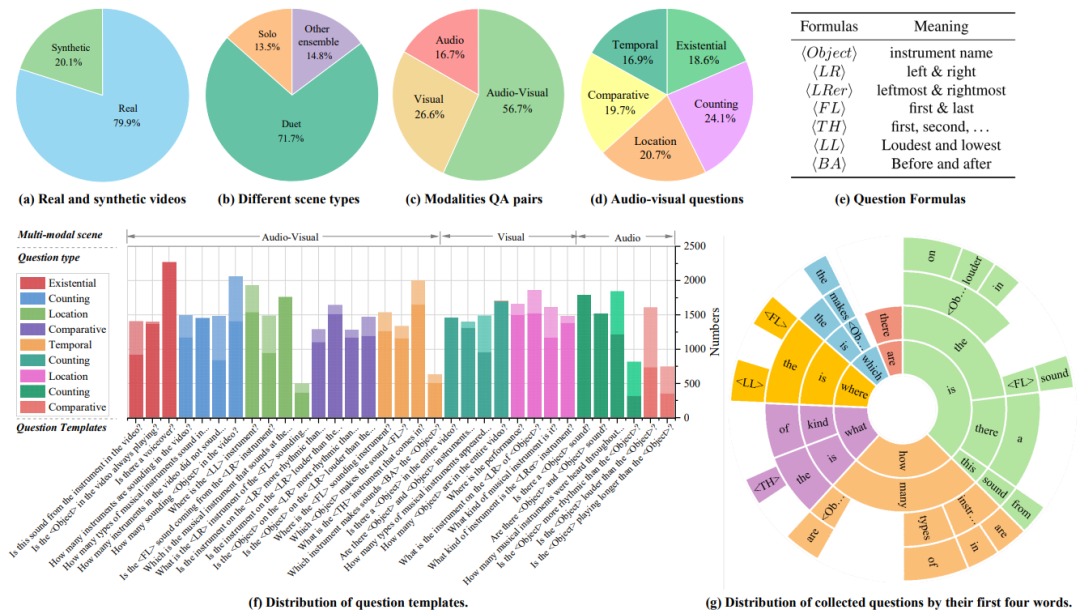
图 2 MUSIC-AVQA数据集多维统计分析
3. 模型方法
为了解决上述 AVQA 任务,我们分别从空间和时序感知的角度出发,提出了一种动态视音场景下的空间-时序问答模型(如下图所示)。首先,声音及其视觉源的位置反映了视听模态之间的空间关联,这有助于将复杂的场景分解为具体的视听关联。因此我们提出了一个基于注意力机制的声源定位的空间模块来模拟这种跨模态的关联。其次,由于视听场景随时间动态变化,因此捕捉和突出与问题密切相关的关键时间戳至关重要。因此,我们提出了使用问题特征作为查询的时间基础模块来聚焦关键时间片段,以有效地编码问题感知音频和视觉的嵌入。最后,融合上述空间感知和时间感知的视听特征,得到问答的联合表示,以预测视频关联问题的答案。
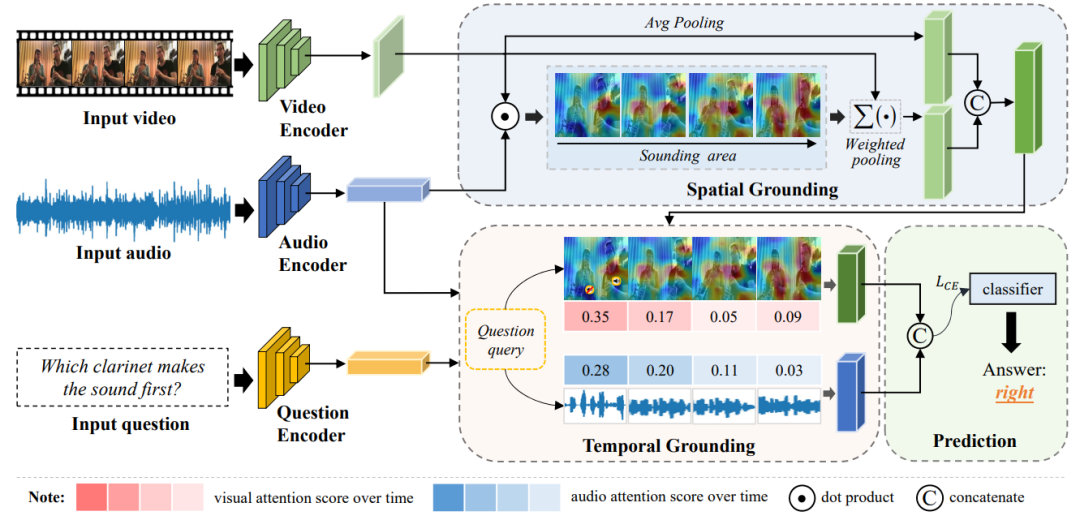
图3 动态视音场景的空间-时序问答模型
4. 实验结果
如表2所示,引入Audio和Visual模态信息都有助于模型性能的提升。此外,能明显看到当结合声音和视觉模态时,AV+Q 模型的性能比A+Q和V+Q模型要好得多,这表明多感官感知有助于提升问答任务的性能。我们也能看到视音空间关联模块和时序关联模块都能够很明显的提升模型的性能,从而更好地对场景进行理解。
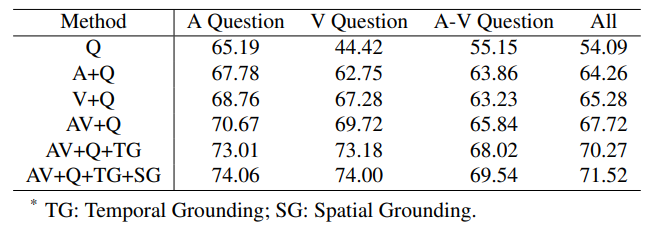
表2 不同模态消融实验表
表3展示了一些最近的QA方法在我们的MUSIC-AVQA数据集上的结果。结果首先表明所有的AVQA方法都要好于VQA、AQA和VideoQA方法,这说明多模态感知可以有益于AVQA任务。其次我们的方法在大多数视听问题上取得了相当大的进步,尤其是对于需要空间和时序推理的视听问题更为明显(如Temporal和Localization等)。
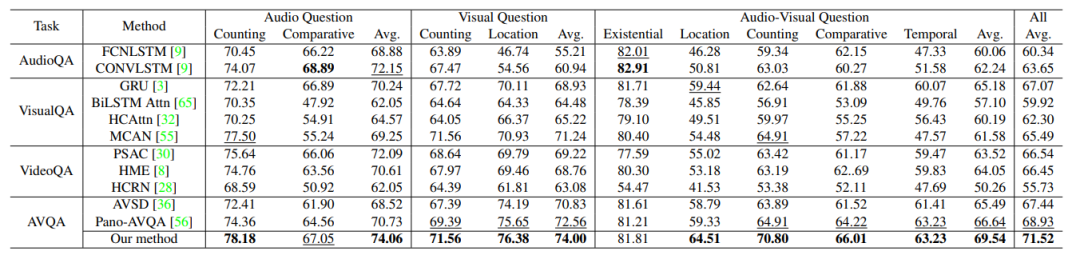
表3 与其他QA类方法对比
为了进一步说明所提模型的有效性和可解释性,我们进行了一些可视化展示。其中热力图表示声源的位置,热力图下方的表格表示时序上的注意力分数。从可视化结果可以明显看出所提的模型在多模态视听场景中具有很好的理解和推理能力。

图4 可视化结果
5. 总述
总体来说,本文探索了如何回答有关不同视觉对象、声音及其在视频中的关联的问题,从而对动态复杂的视音场景进行细粒度理解和推理。作者团队构建了一个包含45,867个不同视听模态和多种问题类型问答对的大规模MUSIC-AVQA数据集,以及提出了一个简单高效的视音时序-空间模型来很好的解决AVQA问题。我们相信提出的MUSIC-AVQA数据集可以成为评估视听场景细粒度理解和时空推理的基准平台,同时也认为这项工作是探索视听推理的开篇之作,为该领域开创了一个良好的开端,并借此希望能够激励更多的研究者同我们一道去探索这一领域。
团队主要来自人大AI学院
本项研究由中国人民大学高瓴人工智能学院主导,与美国罗彻斯特大学合作完成,通讯作者为GeWu实验室胡迪助理教授,主要内容由GeWu实验室博士生李光耀负责。
GeWu实验室目前具体的研究方向主要包括多模态场景理解、多模态学习机制和跨模态交互与生成等,最近半年实验室同学已发表多篇高质量文章,如TPAMI(人工智能领域影响因子最高的期刊,IF=17.861)和多篇CVPR(均为Oral)。
PS:我们发现常用的多模态模型存在欠优化的单模态表征,这是由某些场景中另一种主导模态导致的。为此我们设计了OGM-GE方法,通过监控不同模态对学习目标的贡献差异来自适应地调制每种模态的优化,从而缓解了这种优化上的不平衡。这篇工作也被CVPR2022接收为Oral Presentation,具体内容我们将在后续发布中解说。
此外,GeWu实验室非常欢迎对上述研究方向感兴趣的同学加入(本、硕、博和访问学生),详情请进一步查看实验室招生宣传 :
https://zhuanlan.zhihu.com/p/496452639)

ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer或者目标检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer或者目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看







