工程之道,深度学习的工业级模型量化实战


背景
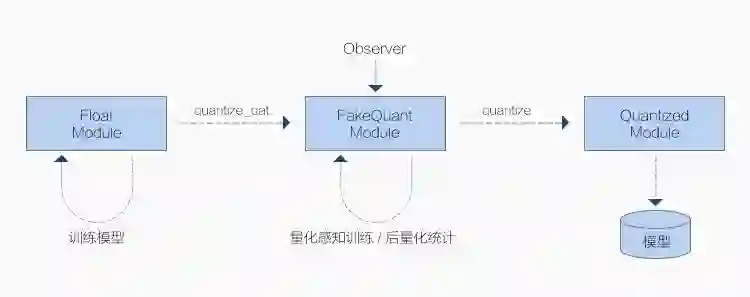
原理
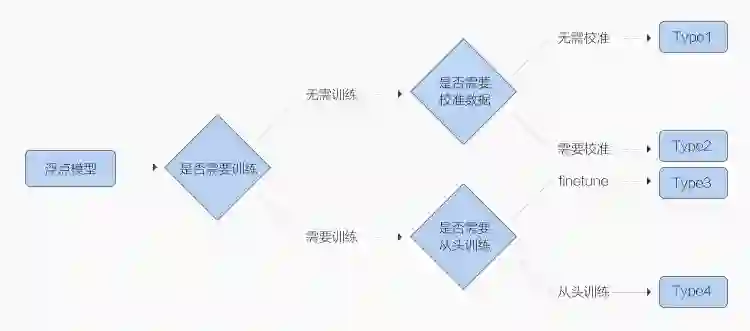
-
Type1 和 Type2 由于是在模型浮点模型训练之后介入,无需大量训练数据,故而转换代价更低,被称为后量化(Post Quantization),区别在于是否需要小批量数据来校准(Calibration); -
Type3 和 Type4 则需要在浮点模型训练时就插入一些假量化(FakeQuantize)算子,模拟量化过程中数值截断后精度降低的情形,故而称为量化感知训练(Quantization Aware Training, QAT)。
-
拉近 QFloat 和 Q:这样训练阶段的精度可以作为最终 Q 精度的代理指标,这一阶段偏工程; -
拔高 QFloat 逼近 Float:这样就可以将量化模型性能尽可能恢复到 Float 的精度,这一阶段偏算法。

ARM 平台
-
ARM v8.2 主要的特性是提供了新的引入了新的 fp16 运算和 int8 dot 指令,MegEngine基于此进行一系列细节优化(细节:四个int8放到一个128寄存器的32分块里一起算),最终实现了比浮点版本快2~3倍的速度提升 -
而对于v8.2之前的ARM处理器,MegEngine则通过对Conv使用nchw44的layout和细粒度优化,并创新性地使用了int8(而非传统的int6)下的winograd算法来加速Conv计算,最使实现能够和浮点运算媲美的速度。
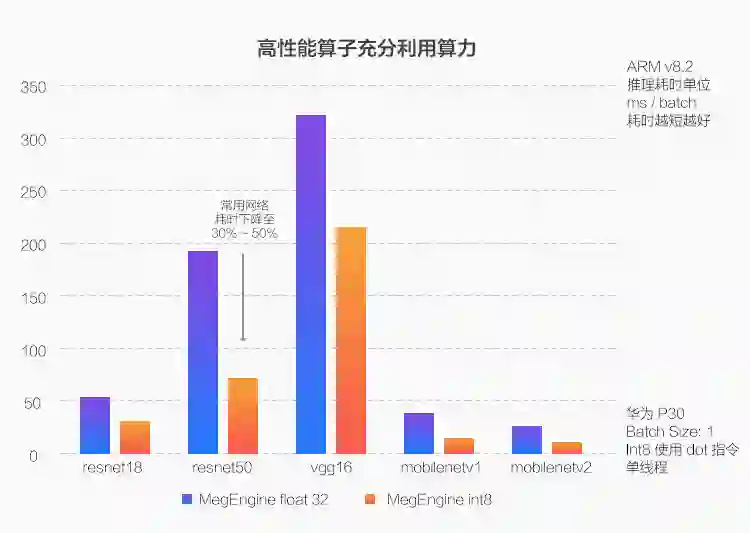
CUDA 平台
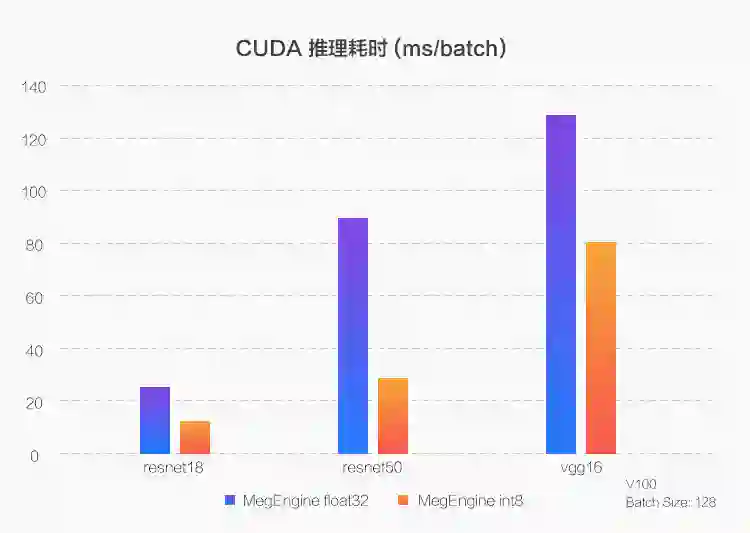
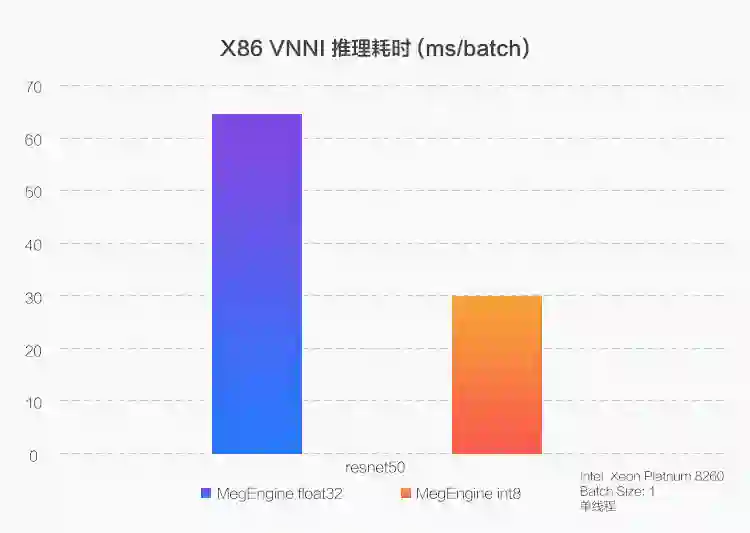
X86 平台
-
在新一代至强(Xeon)处理器上,通过使用 VNNI(Vector Neural Network Instructions)指令,MegEngine 将 CPU 的 int8 推理性能优化到了浮点性能的 2~3 倍。 -
而对于不支持 VNNI 指令的 CPU,一般只提供最低 int16 的数值类型支持,则通过使用 AVX2(Advanced Vector Extensions)这一向量格式,实现了 int8 推理性能与浮点性能持平。
使用
ema_fakequant_qconfig = QConfig( weight_observer=partial(MinMaxObserver, dtype="qint8", narrow_range=True), act_observer=partial( ExponentialMovingAverageObserver, dtype="qint8", narrow_range=False ), weight_fake_quant=partial(FakeQuantize, dtype="qint8", narrow_range=True), act_fake_quant=partial(FakeQuantize, dtype="qint8", narrow_range=False),)
from megengine.quantization import ema_fakequant_qconfigfrom megengine.quantization.quantize import quantize_qat # 使用fuse好的Module搭建的网络model = ResNet18() # 使用默认的配置进行模型转换quantize_qat(model, ema_fakequant_qconfig) # 与 Float 模型完全一致的训练函数train(model)
from megengine.quantization.quantize import quantize# 使用fuse好的Module搭建的网络model = ResNet18()# 执行模型转换quantize(model)# 将模型进行编译,infer_func是trace类的实例,通过trace方法进行编译infer_func(processed_img).trace()# 调用dump方法将模型导出,用于部署infer_func.dump(output_file, arg_names=["data"])
总结
欢迎访问
-
MegEngine Website:
https://megengine.org.cn -
MegEngine GitHub(欢迎Star):
https://github.com/MegEngine
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


登录查看更多
相关内容



相关VIP内容
相关资讯