论文浅尝 | 通过依赖预测和信息流控制提高关系提取的跨领域性能
论文笔记整理:王狄烽,南京大学硕士,研究方向为知识图谱、知识库补全。

链接:https://arxiv.org/abs/1907.03230
动机
现有关系抽取模型中利用依赖树信息的方式主要是通过沿着依赖关系树的结构引导其计算来利用依赖树结构信息,其存在至少以下两点问题:
1、模型中的信息流仅限于树的结构,因此依赖树在模型中的直接应用可能无法捕获超出此依赖树结构覆盖范围之外的重要的上下文信息。如图一中所示,对于实体“he”和“Cane Mike”,两者最短路径中忽略了“not”这个重要的上下文信息,从而可能导致关系分类错误。
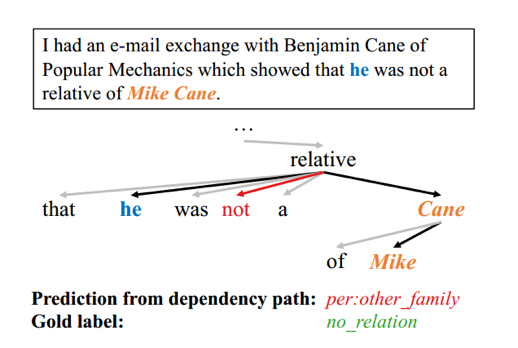
图1
2、在跨领域场景中,训练数据和测试数据的句子来自于不同的领域,训练数据的依赖树结构和测试数据中的依赖树结构可能存在较大的差异。如果使用训练数据的结构对模型进行训练,则可能无法将其推广到测试数据的依赖结构中,从而导致跨领域场景下模型性能不佳。
相关工作
现有的深度学习模型中利用依赖树结构信息的方式主要有以下四种:
1、赖树化简为实体之间的最短依赖路径;
2、实体的最低公共祖先下方的依赖树或者子树执行自下而上或自上而下的计算;
3、TreeLSTM:直接将依赖树作为输入。
4、GCN:使用图卷积网络来学习依赖树结构信息。
贡献
1、本文提出了一种新的基于依赖关系预测任务的利用依赖树结构信息的方法,该方法能够避免以往利用依赖树方式的缺陷。
2、本文提出了一种新的控制机制来控制句子中每个单词的特征表示,以为关系抽取任务定制化每个word的表示。
3、在多个公开数据集上取得了state-of-the-art的效果。
方法
1、依赖关系预测任务
引入依赖关系预测任务,通过预测句子中任两个词之间是否存在依赖关系,使得词的向量表示捕捉到依赖树结构信息。通过该种方式利用依赖树信息,间接的使用依赖关系结构来鼓励其表示能够兼顾语义和结构表示,且更加泛化。
2、控制机制
通过控制机制定制化每个词的表示,具体来说,通过两个实体的向量生成控制向量,基于控制向量将每个词向量中移除不相关的信息,从而使得每个词的表示和RE任务相关。
模型
模型主体由三部分组成:(1)表示学习:基于依赖树结构信息和上下文语义信息为每个词学习得到特征表示。(2)表示控制:基于两个entity mention决定每个词的表示中哪一个维度的特征用于最终的关系预测的表示。(3)关系预测:基于最终词的表示,预测两个entity mention之间的关系。
1、表示学习
1.1 词初始化表示
对于句子中的每个词 x_i,其初始化表示,由7个向量拼接而成。
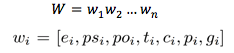
其中,e_i是预训练的词向量表示。po_i 和 ps_i 的该词距离两个实体 mention 距离的向量表示。t_i 和 c_i 是词 x_i 在 BIO 标签体系上实体信息和分词信息的向量表示。p_i是表示该词 x_i 是否在两个entity mention最短依赖路径上的二元表示,1表示在,0表示不在。g_i 是该词拥有的依赖关系种类的one-hot表示。
1.2 上下文表示
w_i 仅捕捉了当前词的信息,为了捕捉句子中丰富的上下文信息,本文使用BiLSTM模型捕获上下文信息,最终将隐藏层向量作为该句子中每个token的上下文表示。
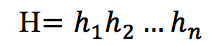
1.3 Self-Attention Representation
通过BiLSTM获取的上下文表示依旧存在长距离信息丢失情况,为了解决该问题,本文使用自注意力机制,使得每个词可以直接贡献向量表示到其他词中,其主要公式如下。
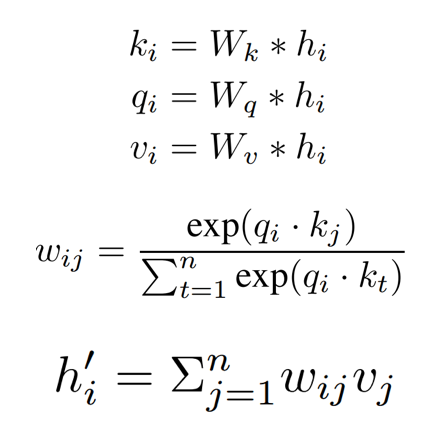
最终,我们获取得到自注意力表示 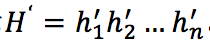
1.4依赖关系预测
当前自注意力表示 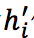
给定句子中两个词 x_i 和 x_j,我们首先计算这两个词之间在依赖树结构中存在边的概率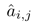
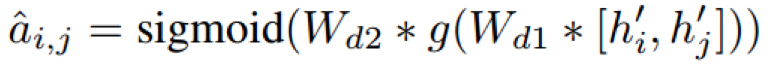
最终通过最大化似然概率使得捕获得到依赖树结构化信息。
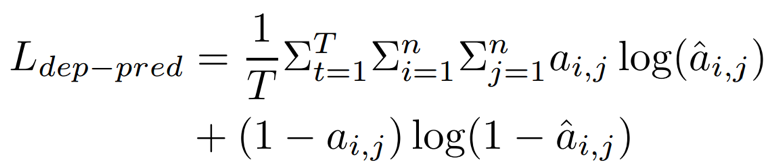
2、表示控制
除了间接使用依赖关系树之外,本为针对RE任务引入了一种新的控制机制,该机制根据两个实体mention 感兴趣的内容来调整token的表示。其主要原理来自两个方面:
(1)对于RE任务,两个实体mention的信息是至关重要的,因此每个word的最终有效的表示应该仅保留和这两个实体mention相关的信息,控制机制能够对每个word的表示起到信息过滤的作用。
(2)在注意力机制中,我们为每个单词计算了权重,但是假设每个单词的表示向量中每个维度/特征的权重是相同的。然而,在实践中,如果我们可以调节各个维度/特征,则可能更加灵活,因此通过控制机制,对于每个word的表示调整各维度特征信息,控制机制将有助于量化每个维度/特征的贡献。
本文,将控制机制同时应用到了上下文表示 H 和自注意力表示 H',其做法如下。
首先,对于上下文表示 H。我们首先利用首尾实体 x_s 和 x_o 的上下文表示生成控制向量p。
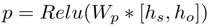
然后我们将控制向量作用到每个word的上下文向量中,获取过滤之后的向量表示。
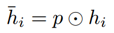
接着,对于自注意力表示。我们利用首尾实体 x_s 和 x_o 的上下文表示和向量生成控制向量c,具体公式为。
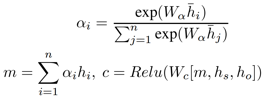
其过滤后的向量表示为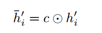
3、关系预测
最终本文利用学习得到的多种向量信息,进行最终的关系预测。
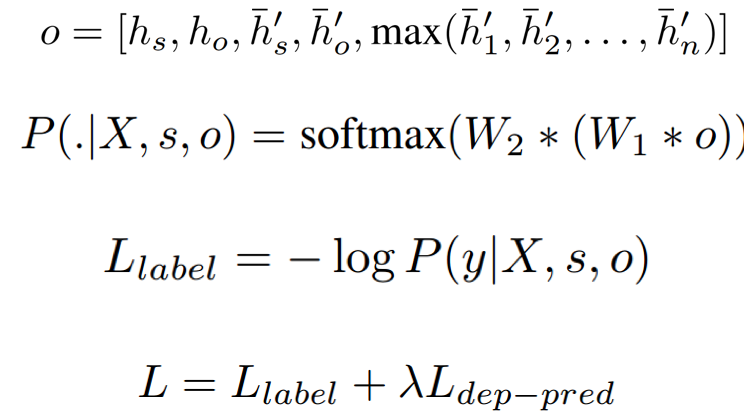
实验
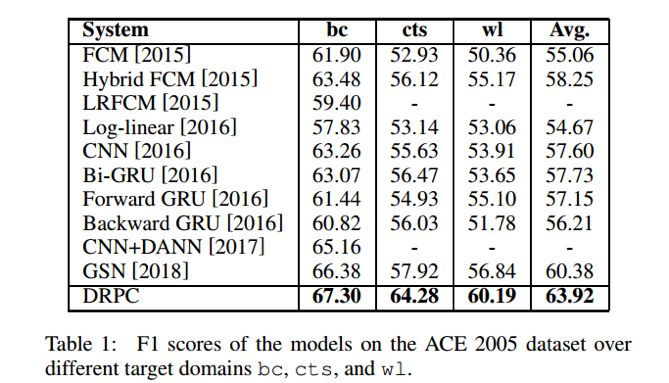
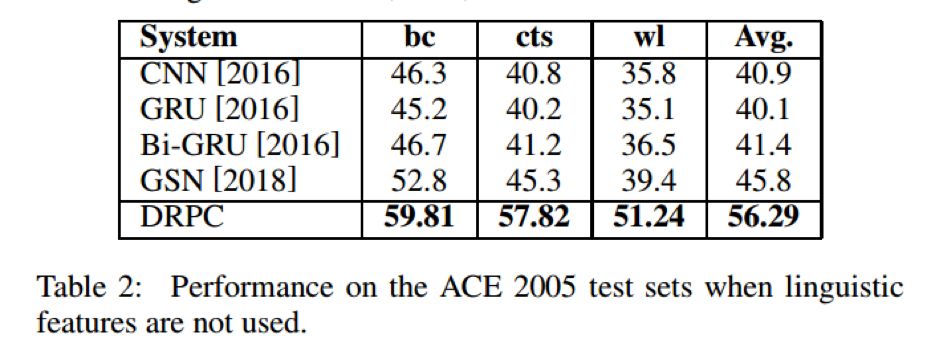
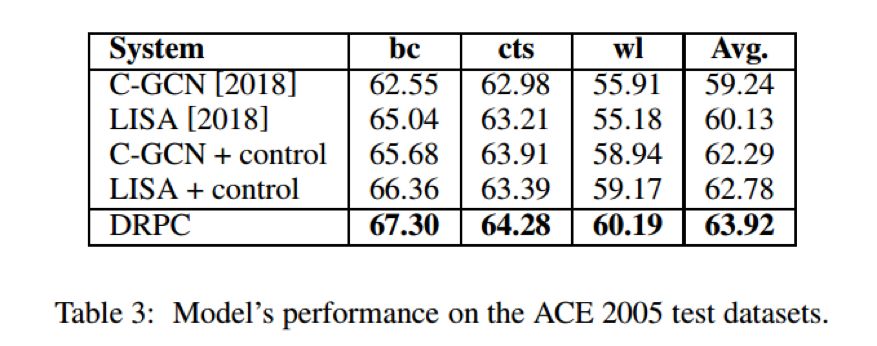
最终,本文在ACE2005的数据集上进行了跨领域设定下关系抽取任务,结果表明了该模型的有效性。
总结
文本提出了一种领域无关/跨领域的一种新的利用依赖树结构信息的方式来进行关系抽取,即依赖关系预测任务,同时提出了一种信息控制机制,使得每个词的向量表示根据RE任务实现定制化,最终模型在多个公开数据集上取得了state-of-art的效果。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。

