SimVLM:弱监督简单视觉语言模型预训练


发布人:Google Research Brain 团队学生研究员 Zirui Wang 和研究员 Yuan Cao
视觉语言建模基于视觉输入形成相应的语言理解,这对于重要产品和工具的开发非常有用。例如,图像文字说明制作模型能根据其对给定图像的理解生成自然语言描述。虽然此类跨模态研究面临各种挑战,但由于采用了有效的视觉语言预训练 (VLP),过去几年间在视觉语言建模方面已取得显著进展。
工具
https://ai.googleblog.com/2021/05/cross-modal-contrastive-learning-for.html
已取得
https://arxiv.org/abs/2107.06912
VLP 这种方法旨在从视觉输入和语言输入中学习单一特征空间 (feature space),而不是学习两个单独的特征空间(一个用于视觉输入,另一个用于语言输入)。为此,现有的 VLP 通常利用目标检测器,如 Faster R-CNN,在标记的目标检测数据集上进行训练,以隔离感兴趣区域 (Regions-of-interest,ROI),并依赖任务特定的方法(如任务特定的损失函数)共同学习图像和文本的表征。此类方法需要经过标注的数据集或时间,才能设计出特定于任务的方法,因此可扩展性较差。
Faster R-CNN
https://papers.nips.cc/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf
为应对这一挑战,在“SimVLM:弱监督简单视觉语言模型预训练 (SimVLM: Simple Visual Language Model Pre-training with Weak Supervision) ”一文中,我们提出了一种极简且有效的 VLP,名为 SimVLM(“Simple Visual Language Model”的缩写)。SimVLM在大量对齐性不佳的图像-文本对(即与图像配对的文本不一定是对图像的精确描述)上使用统一目标(与语言建模相当)对 SimVLM 进行端到端训练。利用 SimVLM 的易用性,模型可以在规模庞大的数据集上进行高效训练,从而可以在六项视觉语言基准中实现绝佳性能。此外,SimVLM 可学习统一的多模态表征,无需微调或仅对文本数据进行微调,即可实现强大的零样本跨模态迁移 (zero-shot cross-modality transfer) ,可用于开放式视觉问答 (Question answering)、图像文字说明制作和多模态翻译等任务。
SimVLM:弱监督简单视觉语言模型预训练
https://arxiv.org/abs/2108.10904


现有的 VLP 方法采用类似于掩码语言建模(如在 BERT 中)的预训练过程。与此类方法不同,SimVLM 采用序列到序列框架,并使用单一前缀语言模型 (PrefixLM) 目标进行训练,该目标通过接收序列的前导部分(前缀)作为输入,然后对其后续内容进行预测。例如,如果序列 “A dog is chasing after a yellow ball” 被随机截断并以 “A dog is chasing” 作为前缀,模型会预测其后续内容。前缀的概念同样适用于图像。图像可划分为若干个“图块”,然后这些图块的子集作为输入依次馈送给模型,这称为“图块序列”。对于 SimVLM 中的多模态输入(例如,图像及其文字说明),前缀是由编码器接收的图块序列和前缀文本序列串联而成的,然后解码器会预测文本序列的后续内容。与之前结合多个预训练损失的 VLP 模型相比,PrefixLM 损失是唯一的训练目标,这大大简化了训练过程。SimVLM 的这种方法最大限度地提高了模型在适应不同任务设置方面的灵活性和通用性。
最后,由于 Transformer 架构在语言和视觉任务(如 BERT 和 ViT)方面均有突出的表现,我们将其作为了模型的主干。与之前基于 ROI 的 VLP 方法不同,我们的模型利用该架构能够直接将原始图像作为输入。
Transformer
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
BERT
https://arxiv.org/abs/1810.04805
ViT
https://openreview.net/pdf?id=YicbFdNTTy
此外,受 CoAtNet 的启发,我们采用了由 ResNet 前三个块组成的卷积暂存区,提取上下文图块。从中我们发现这比原始 ViT 模型中的朴素线性投影更有优势。整体模型架构如下图所示。
CoAtNet
https://ai.googleblog.com/2021/09/toward-fast-and-accurate-neural.html
ResNet
https://arxiv.org/abs/1512.03385

SimVLM 模型架构概览
我们针对图像文本和纯文本输入在大型网络数据集上对该模型进行了预训练。对于视觉和语言联合数据,我们使用了 ALIGN 训练集,其中包含大约 18 亿个有噪图像-文本对。对于纯文本数据,我们使用 T5 引入的 Colossal Clean Crawled Corpus (C4) 数据集,其中共有 800G 网络抓取文档。
T5
https://arxiv.org/abs/1910.10683
Colossal Clean Crawled Corpus (C4)
https://tensorflow.google.cn/datasets/catalog/c4
预训练后,我们在以下多模态任务中对模型进行了微调:VQA、NLVR2、SNLI-VE、COCO Caption、NoCaps 和 Multi30K En-De。例如,对于 VQA,模型获取图像和有关输入图像的相应问题,并生成答案作为输出。我们按照与 ViT 中相同的设置评估三种不同大小的 SimVLM 模型(基础:8600 万参数,大型:3.07 亿参数和巨大:6.32 亿参数)。
VQA
https://visualqa.org/challenge.html
NLVR2
https://lil.nlp.cornell.edu/nlvr/
SNLI-VE
http://SNLI-VE
COCO Caption
https://github.com/tylin/coco-caption
NoCaps
https://eval.ai/web/challenges/challenge-page/355/leaderboard/1011
Multi30K En-De
https://github.com/multi30k/dataset
我们将结果与现有的强大基线(如 LXMERT、VL-T5、UNITER、OSCAR、Villa、SOHO、UNIMO、VinVL)进行比较,发现虽然 SimVLM 更简单,但其在所有这些任务中都实现了绝佳性能。
LXMERT
https://aclanthology.org/D19-1514/
VL-T5
https://proceedings.mlr.press/v139/cho21a.html
UNITER
https://arxiv.org/abs/1909.11740
OSCAR
https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123750120.pdf
Villa
https://proceedings.neurips.cc/paper/2020/file/49562478de4c54fafd4ec46fdb297de5-Paper.pdf
SOHO
https://arxiv.org/abs/2104.03135
UNIMO
https://arxiv.org/abs/2012.15409
VinVL
https://openaccess.thecvf.com/content/CVPR2021/html/Zhang_VinVL_Revisiting_Visual_Representations_in_Vision-Language_Models_CVPR_2021_paper.html

包含 6 个视觉语言基准的子集与现有基线模型相比的评估结果。上表用到的指标(数据越大越好):BLEU-4 (B@4)、METEOR (M)、CIDEr (C)、SPICE (S)。同样,对 NoCaps 和 Multi30k En-De 的评估也证明了该模型的绝佳性能
CIDEr
https://arxiv.org/abs/1411.5726
SPICE
https://arxiv.org/abs/1607.08822
我们使用了大量视觉和文本模态的数据对 SimVLM 进行训练,我们很想知道其是否能够执行零样本跨模态迁移。为此,我们在多个任务中检验该模型,包括图像文字说明制作、多语言文字说明制作、开放式 VQA 和视觉文本完成。我们采用预训练的 SimVLM 并直接将其解码以用于多模态输入,仅对文本数据进行微调或完全不进行微调。下图给出了一些示例,可以看出,该模型不仅能够生成高质量的图像文字说明,还能够生成德语描述,同时实现跨语言和跨模态迁移。

SimVLM 零样本泛化示例。(a) 零样本图像文字说明制作:如果给出带文本提示的图像,预训练模型无需微调即可预测图像内容。(b) 德语图像文字说明制作中的零样本跨模态迁移:即使从未针对德语图像文字说明制作数据对该模型进行微调,其也能生成德语字幕。(c) 生成性 VQA:该模型能够在原始 VQA 数据集的候选对象之外生成答案。(d) 零样本视觉文本完成:预训练模型基于图像内容完成文本描述;(e) 零样本开放式 VQA:在使用 WIT 数据集进行持续预训练后,该模型为有关图像的问题提供了事实性答案。图像来自 NoCaps,这是 2.0 版 CC 协议下的 Open Images 数据集
WIT
https://arxiv.org/abs/2103.01913
Open Images
https://opensource.google/projects/open-images-dataset
为量化 SimVLM 的零样本性能,我们采用预训练的固化模型,并使用 COCO Caption 和 NoCaps 基准对其进行解码,然后与监督基线进行比较。即使没有监督微调(中间几行),SimVLM 也可以达到接近监督方法质量的零样本文字说明制作质量。
COCO Caption
https://arxiv.org/pdf/1504.00325.pdf
NoCaps
https://nocaps.org/
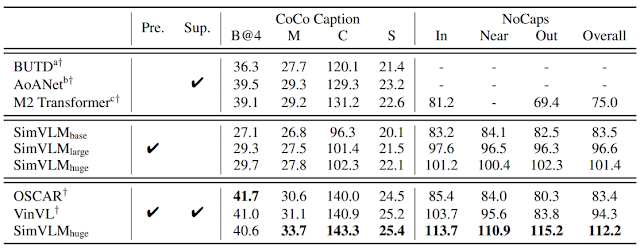
零样本图像文字说明制作结果。此处的“Pre.”表示模型经过预训练,而“Sup.”则表示该模型在特定于任务的监督下进行了微调。对于 NoCaps,In、Near、Out 分别指域内、近域和域外。我们比较了 BUTD、AoANet、M2 Transformer、OSCAR 和 VinVL的结果。上表用到的指标(数据越大越好):BLEU-4 (B@4)、METEOR (M)、CIDEr (C)、SPICE (S)。对于 NoCaps,模型会报告 CIDEr 编号
BUTD
https://openaccess.thecvf.com/content_cvpr_2018/CameraReady/1163.pdf
AoANet
https://openaccess.thecvf.com/content_ICCV_2019/papers/Huang_Attention_on_Attention_for_Image_Captioning_ICCV_2019_paper.pdf
M2 Transformer
https://openaccess.thecvf.com/content_CVPR_2020/papers/Cornia_Meshed-Memory_Transformer_for_Image_Captioning_CVPR_2020_paper.pdf
我们提出的 VLP 框架既简单又有效。与先前使用目标检测模型和特定于任务的辅助损失的研究不同,我们的模型是使用单一前缀语言模型目标进行端到端训练的。在各种视觉语言基准中,这种方法不仅获得了绝佳性能,还在多模态理解任务中表现出了有意思的零样本能力。
感谢 Jiahui Yu、Adams Yu、Zihang Dai、Yulia Tsvetkov 参与 SimVLM 论文的编写,感谢 Hieu Pham、Chao Jia、Andrew Dai、Bowen Zhang、Zhifeng Chen、Ruoming Pang、Douglas Eck、Claire Cui 和 Yonghui Wu 提供有价值的讨论,感谢 Krishna Srinivasan、Samira Daruki、Nan Du 和 Aashi Jain 在数据准备方面提供的帮助,感谢 Jonathan Shen、Colin Raffel 和 Sharan Narang 在实验设置方面提供的帮助,感谢 Brain 团队其他成员在整个项目过程中提供的支持。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看


