从两篇ECCV 2020来看视频Re-ID中的特征对齐与增强
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:Whn丶nnnnn | 知乎专栏:论文学习
https://zhuanlan.zhihu.com/p/263086263
本文已由原作者授权,不得擅自二次转载
前言
前段时间阅读了两篇与视频行人重识别(Re-ID)相关的文章,出自同一个实验室的,被ECCV2020接收。个人认为,虽然这两篇文章的理论出发点比较简单,但是建模实现过程和行文逻辑构建还是比较有趣的,值得一看。
一、Appearance-Preserving 3D Convolution for Video-based Person Re-identification
论文:https://arxiv.org/abs/2007.08434
代码:https://github.com/guxinqian/AP3D
相对于静态图像行人Re-ID来说,视频Re-ID含有更丰富的表观和时间信息,也更有难度和挑战性。这篇论文提出一种基于外观信息保留的3D卷积,用于增强3D卷积在视频Re-ID中的作用,方法本质是表观特征对齐。
作者提出Appearance-Preserving 3D convolution (AP3D)来解决表观特征不对齐的问题。AP3D的实现流程是,首先,扩充一倍输入特征图得到下面一条分支,然后分别采样每一帧的前、后帧得到上面一条分支,两条分支经Appearance-Preserving Module (APM)后生成与当前帧表观信息对齐的重建的前、后相邻帧,再将原始每一帧插入这些重建帧当中得到integrated feature maps,最后经过3×3×3的3D卷积获得输出。
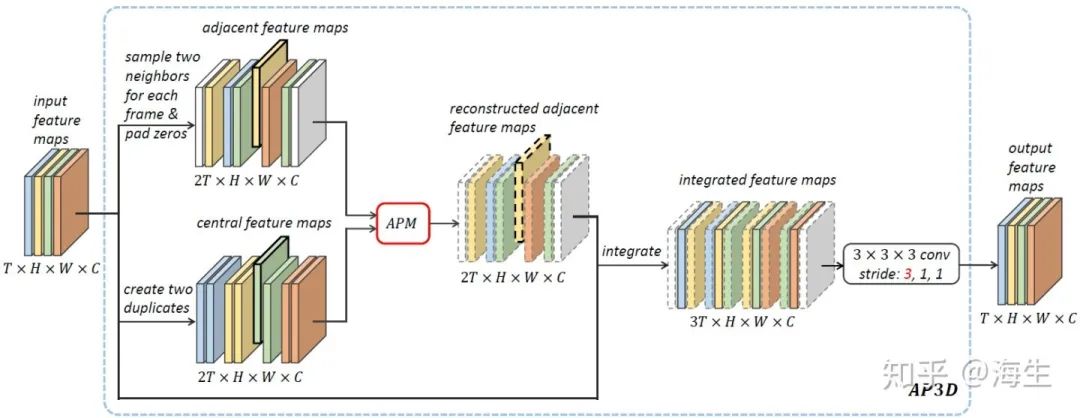
APM是实现对齐的一个关键模块,包含Feature Map Registration和Contrastive Attention两部分。
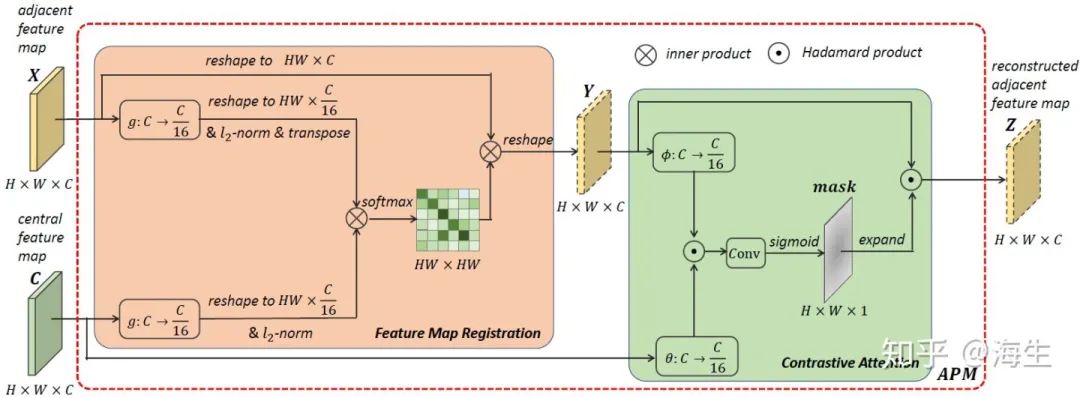
Feature Map Registration
选定central feature map C 及其对应的adjacent feature map X,然后分别经1×1卷积、变形和归一化后通过softmax得到相似度矩阵,再与X 做矩阵乘法得到相似度响应图Y (相似特征响应高)。通过Feature Map Registration就可以让X 与C 的相似特征实现对齐。
Contrastive Attention
事实上,相邻两帧之间可能没有公共的body parts,此时Registration将不准确。为此,作者提出了Contrastive Attention来寻找Y 和C 的不相似区域。并通过系列操作获得基于语义相似度的mask,再与Y 加权后用于抑制不匹配的body parts的特征表达,最后生成重建特征图Z。
最后,作者探究了几种AP3D与现有3D卷积的结合方式,并用实验结果论证了AP3D在不同网络层所起的作用。
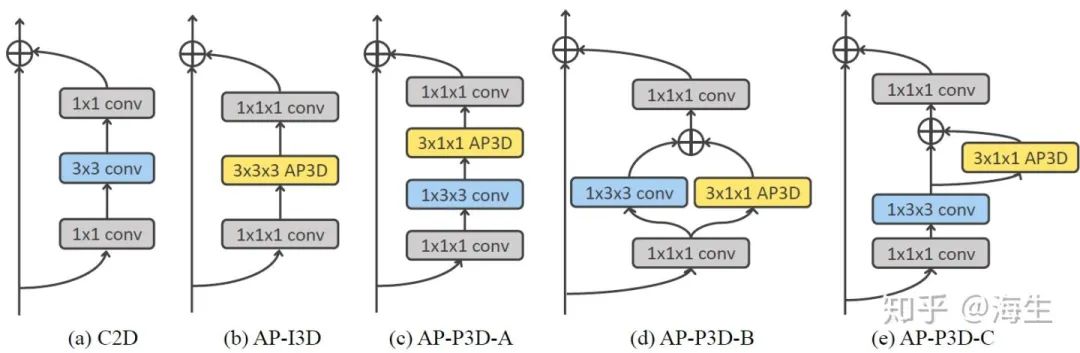
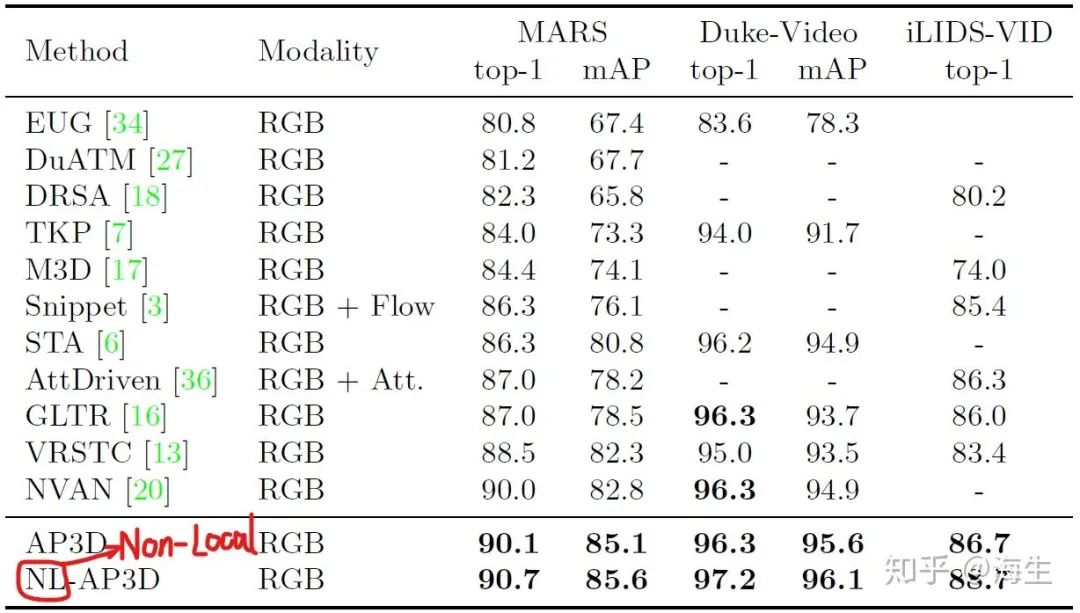
小结
论文的基本思路比较简单,但作者的实现思路还是具有一定创新性的,通过重建的方式对齐行人公共表观特征。在论文写作上,也比较严谨,从问题的分析到数学模型的构建和参数的选择,都值得学习。
二、Temporal Complementary Learning for Video Person Re-Identification
论文:https://arxiv.org/abs/2007.09357
代码:https://github.com/blue-blue272/VideoReID-TCLNet
如果有关注近几年的数据增强方法的话,就会发现random erase[1]是一个行之有效的提点操作。但一般的random erase是用在输入图像的,而这篇论文是在特征层面实施定向erase,提出一种用于视频Re-ID的时间互补学习的算法。
作者指出,现有大部分方法都没有充分利用行人视频中丰富的时空线索,主要是这些视频中有很多相似的帧,而现有方法在这些帧上执行相同/统一的特征提取操作,得到的冗余特征往往不具很高辨别性。
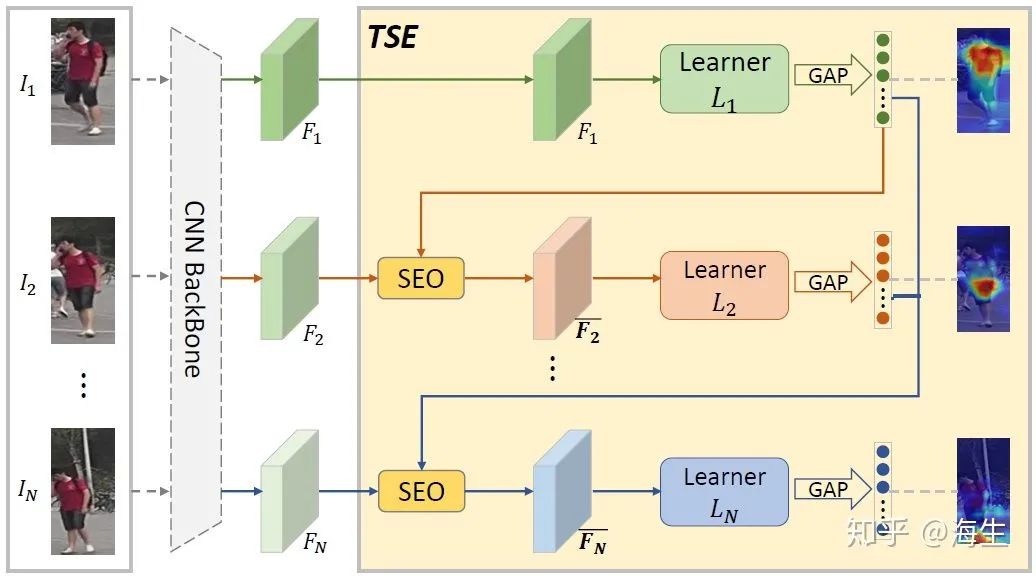
于是作者提出Temporal Complementary Learning Network (TCLNet),用于充分利用视频数据的时空信息。TCLNet包含两个关键部件,分别是Temporal Saliency Erasing和Temporal Saliency Boosting。
Temporal Saliency Erasing (TSE)
TSE的基本原理是利用系列对抗性的学习器在连续的视频帧中提取互为补充的特征。在TSE中,首先第一个学习器为视频序列的第一帧提取最显著的特征,然后在第二帧的特征图上,执行saliency erasing operation(SEO)利用时间线索来擦除对应第一个学习器的显著区域,再利用第二个学习器进一步探索新的显著特征。通过不断擦除所有先前帧的显著特征,这些学习器就可以挖掘出连续帧的互补显著区域,获得行人丰富的整体判别性特征。
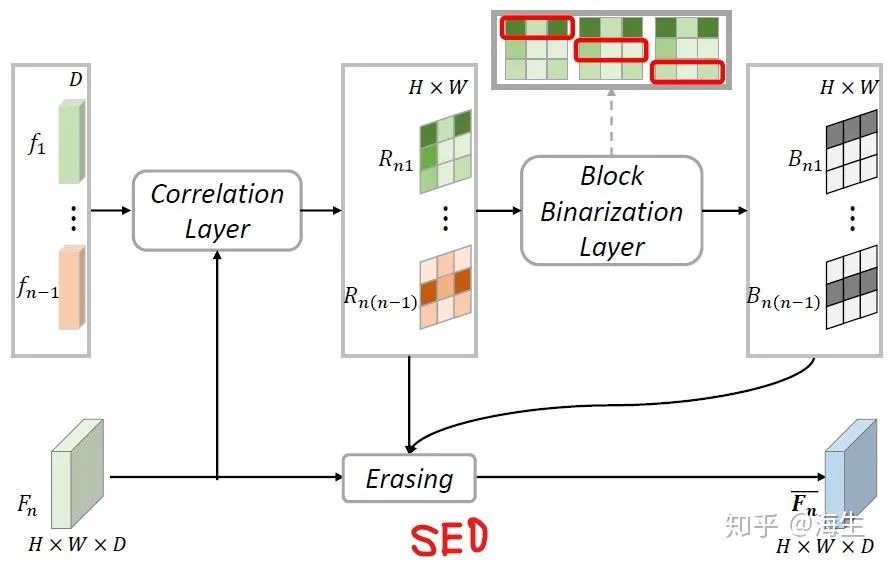
SEO的输入是当前帧的特征图Fn 和之前帧的特征向量。首先,correlation layer根据两个输入,利用点积计算获得一系列的相关图Rn,然后通过Block Binarization Layer得到二值化的mask(Bn)用于标示需要擦除的区域。mask是使用滑块搜索相关图中最突出的连续区域得到的(详细操作可以参考原文)。注意,对于高响应区域,在mask中的值对应为0。最终,这些mask做逐像素相乘,与经过逐像素相乘和softmax的相关图逐像素相乘得到gate map Gn,再作用于Fn 获得擦除后的特征图。
Temporal Saliency Boosting (TSB)
虽然TSE可以提取序列帧的互补的特征,但SEO可能会带来信息丢失的问题。为此,作者提出TSB用于增强最显著特征的表达能力。
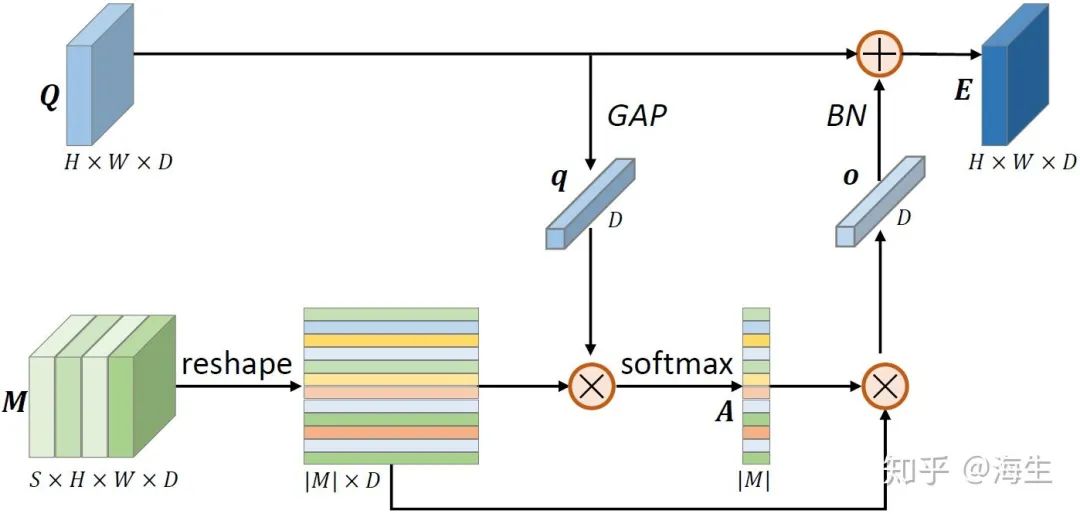
TSB仿照query-memory 注意力机制,将每一帧的特征视为query(Q ),将所有帧的特征视为memory(M ),然后通过变形、点积、softmax和求和等系列操作,增强Q 的表达能力。通过这种query-memory匹配,质量不高的帧在TSB中会有较低的权重,在前向传播期间的表达被弱化。
作者以ResNet-50为backbone,为了减少计算量,所有学习器的前两个残差模块的参数共享。训练时是将一段视频分为若干小段,对每一小段提取特征,然后利用时域平均池化来生成最终的一个特征向量;测试时是提取整段视频的行人特征得到特征向量,用于计算ID相似度。
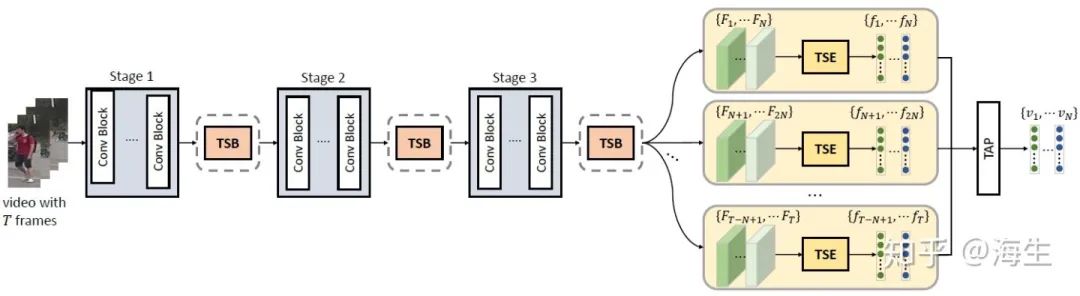
实验的定量结果与上篇论文的差不多,一个直观的定性结果如下图(c)所示。
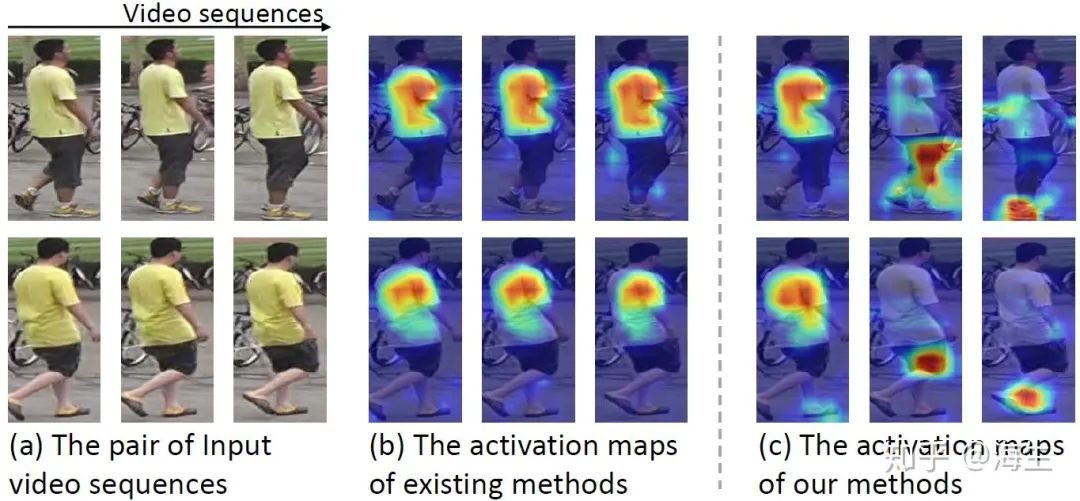
小结
这篇论文在特征层定向地实施erase操作,迫使学习器提取行人丰富且全面的显著性特征,有一定的新颖性和独到性。如果引入特征对齐的话,或许可以将SEO改造成增量式的,就不用一直考虑之前所有帧的特征向量了。
参考资料
[1] Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; and Yang, Y. Random erasing data augmentation. arXiv preprint arXiv:1708.04896 (2017).
上述两种视频Re-ID方法都是离线的,目前单独研究在线的视频Re-ID的相关文章还比较少。要想充分发挥Re-ID在在线多目标跟踪(MOT)的作用,设计与MOT场景相匹配的视频Re-ID模型还是很有必要的。
如有不足之处,欢迎批评指正!
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-Re-ID交流群成立
扫码添加CVer助手,可申请加入CVer-Re-ID 微信交流群,目前已满300+人,旨在交流行人重识别、车辆重识别等事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Re-ID+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



