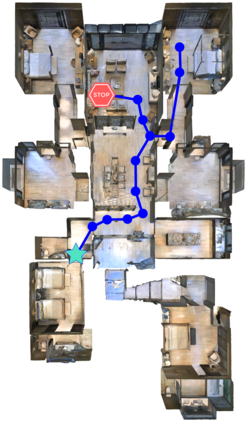
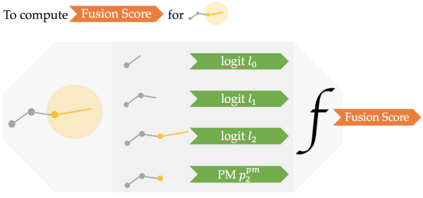
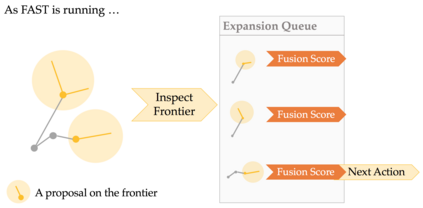
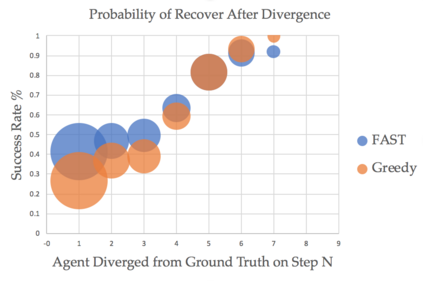
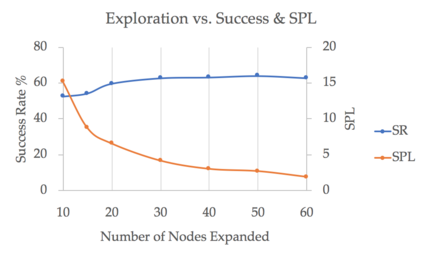
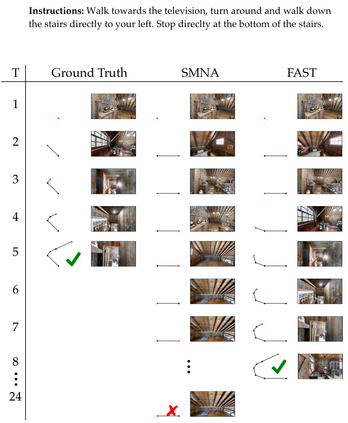
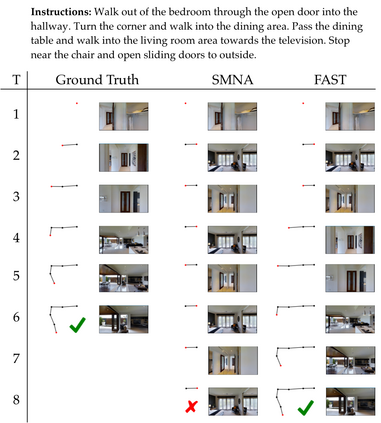
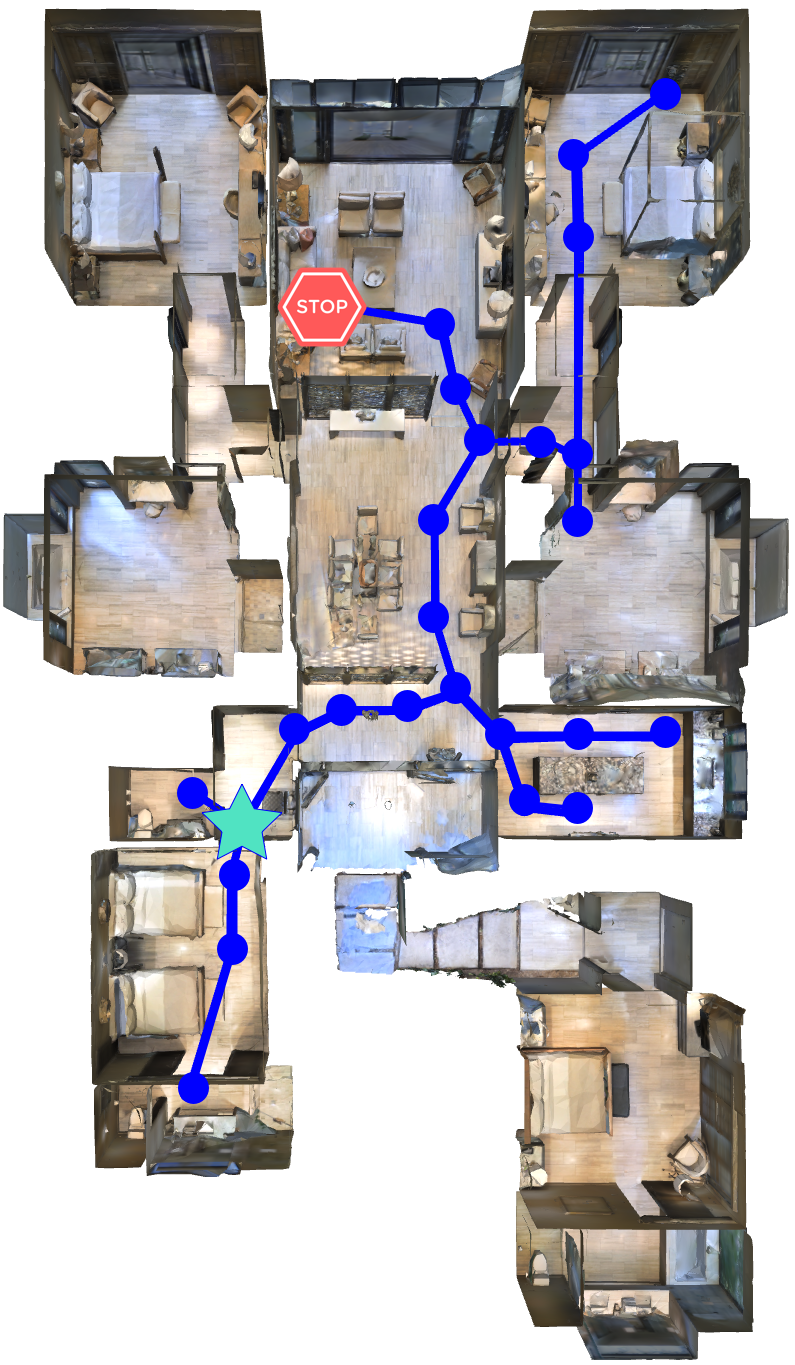
We present FAST NAVIGATOR, a general framework for action decoding, which yields state-of-the-art results on the recent Room-to-Room (R2R) Vision-and-Language navigation challenge of Anderson et. al. (2018). Given a natural language instruction and photo-realistic image views of a previously unseen environment, the agent must navigate from a source to a target location as quickly as possible. While all of current approaches make local action decisions or score entire trajectories with beam search, our framework seamlessly balances local and global signals when exploring the environment. Importantly, this allows us to act greedily, but use global signals to backtrack when necessary. Our FAST framework, applied to existing models, yielded a 17% relative gain over the previous state-of-the-art, an absolute 6% gain on success rate weighted by path length (SPL).
翻译:我们提出了FAST NAVIGATOR(AFST NAVIGATOR),这是一个总的行动解码框架,它为最近Anderson等人(2018年)的“房间对房间对房间(R2R)”的视野和语言导航挑战提供了最新的最新结果。鉴于对先前看不见的环境的自然语言教学和摄影现实图像观点,该代理器必须尽快从一个来源向目标地点航行。 尽管目前的所有方法都以对梁搜索的方式作出地方行动决定或分到整个轨迹,但我们的框架在探索环境时无缝地平衡了当地和全球信号。 重要的是,这允许我们采取贪婪的行动,但在必要时使用全球信号反向轨道。 我们的FAST框架适用于现有的模型,比以前的“状态”取得了17%的相对收益,即成功率按路径长度加权的绝对6%的收益(SPL ) 。