ACL2020 | Twitter热议, 香侬科技提出基于span prediction的共指消解模型


在本文中,我们提出一种基于问答(QA)的共指消解(coreference resolution)模型,将每个候选指称(mention)所在句子作为问题,然后模型去抽取文本中所有和该指称共指的文段(span)。这种方法避免了传统共指消解模型的若干问题。
我们提出的模型在数据集CoNLL2012、GAP上取得当前最优结果,分别为83.1和87.5的F1值,大幅度超过之前的最优结果,分别提高了3.5与2.5的F1值。在这篇文章公布之初,就被国际诸多同行在Twitter上热议:
将Coref视为一种QA格式可以大幅提高效果
QA的任务与格式之论:
本文(Coreference Resolution)很有趣而且的确有用!
共指消解(Coreference Resolution)
共指消解是NLP中的一项重要任务,它要求找出文本中指向同一实体的所有文段,这是因为,人们对同一个实体往往有多种不同的说法,如代词、省略词、别名等等。
比如下面一段文本,依次出现了“北京大学”、“北大”、“北京大学校”、“国立北京大学”、“她”,但我们都知道,它们都指向了“北京大学”这个实体,因此说它们说是共指于“北京大学”的,共指消解的目标就是把它们都找出来。
北京大学,简称北大,成立之初为中国最高学府。中华民国建立后,校名改为北京大学校,后又改名为国立北京大学。她现有六个校区。
共指消解在自然语言处理中是一项非常困难的任务,因为它不仅要求理解整段文本的语义,而且还要规避诸多的歧义。比如在上述文本中,模型就很有可能把“学府”此类语义相近的词汇识别为共指词。
过去的共指消解模型大都分为两个步骤处理:
首先考虑文本中所有限定长度的文段,挑出其中可能成为共指词的那部分(称为候选指称);
再按照寻找前驱的方法找到下一个共指词(比如当然已经找到的共指词有{北京大学校、国立北京大学、她},那么下一个前驱共指词就是“北大”,再下一个就是“北京大学”)。
然而,这种做法有两个问题:
在任务层面,第一步被遗漏的共指词就会被永远遗漏,造成错误传递,比如漏选了“北大”之后,它就永远没有机会被选为共指词了;
在算法层面,这些模型通常给一对指称打分,然后根据得分大小判断是否这一对指称共指,这就忽略了显式的上下文信息。
如下图所示,在第一阶段漏选了“北大”,导致最后选择的共指词没有“北大”这个正确答案;在第二阶段错误地将“学府”识别为了“北京大学校”的前驱,从而在最后包含了“学府”这个错误答案。

基于这两个缺点,我们提出用问答(QA)的方式进行共指消解。
首先,我们还是提取出一些候选指称,但是之后,我们对每个指称,将它所在的句子作为问题,将整个文本作为上下文,把二者拼接起来,通过一个问答模型抽取整个文本中该指称的所有的共指词。
还是举上述文本的例子。如下图所示,我们抽取出的候选指称一共有8个,对每个候选,我们都把它所在的那句话作为问题(比如对指称八,我们就选取了“她现有六个校区”作为问题),并且把该指称用一对特殊符号<m></m>包围起来,以区别同一句话内的不同指称;然后再把整个源文本作为上下文。
二者相加,作为输入。模型输出的,就是在源文本中,与当前指称(如指称一的“北京大学”)同指的那些词。在这个例子中,我们抽取出了“北大”、“北京大学校”和“国立北京大学”。之后,我们继续对其他指称进行这个操作,就可以抽取出所有的共指词。

如此一来,由于每个指称既能作为问题,又能作为上下文的一部分,从而就极大降低了它被二次遗漏的可能性。
同时,通过显式提供上下文信息,我们能够更加准确地抽取共指词,实现显著的效果提升。
通过这种方法,我们能够在共指消解标准数据集CoNLL2012和GAP上取得当前最优结果,分别达到了83.1和87.5的F1值,比之前的最优结果分别提高了3.5与2.5。
基于QA的文段抽取式共指消解模型
下图是所提出模型的示意图。该模型由一个指称提取模块和一个指称链接模块组成,前者从原始文本中提取出所有可能的指称,后者将指称聚类为共指词。下面我们来分别介绍这两个模块。
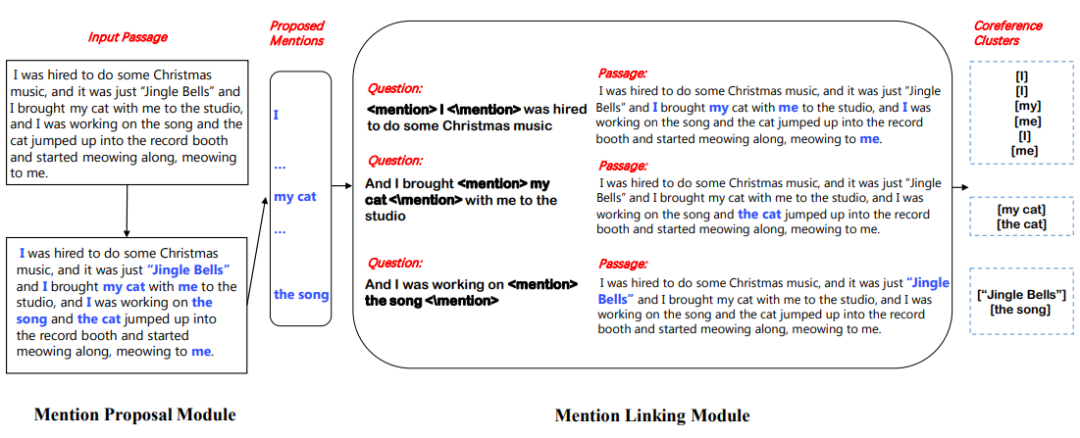
指称提取模块
设输入文本是



对

在得到每个单元的特征表示之后,我们考虑长度最大为

1、指称链接模块
对候选指称中的任意一个指称
具体来说,我们把

此处tag是B/I/O中的一个。然后我们把这个概率拓展到文段级别,得到

显然,要使得上述得分最大,就是要让中括号里面的式子最大,从而就是要对指称
再根据对称性(把

最后再加上两者是指称的得分:

这就是它们最终为共指词的得分。
2、用MRC数据集数据增强
由于该模型是基于问答框架,用问答数据集去预训练它可能会有更好的结果。为此,我们用Quoref和SQuAD两个数据集去预训练指称链接模块。
3、训练与推理
由于所有可能的文段有


此时,每个

我们使用交叉熵去优化它即可。在推理的时候,我们可以得到一个无向图,每个结点是一个候选指称。我们只需要对每个结点保留它的最大得分的边,其构成的连通子图就是某个实体的所有共指词。
实验
我们在共指消解标准数据集GAP和CoNLL2012上进行试验,基线模型有e2e-coref, c2f-coref+ELMo, c2f-coref+BERT-large, EE+BERT-large, c2f-coref+SpanBERT-large。其他设置详见原文。
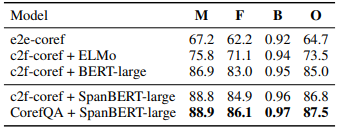
下表是各模型在GAP上的试验结果。其中M是Masculine Examples,F是Feminine Examples,B是Bias factor(F/M),O是Overall F1。
下表是各模型在CoNLL2012上的结果。
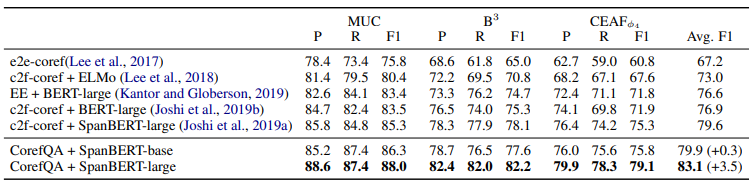
可以看到,在两个数据集上,我们的方法都取得了显著更好的结果,达到了当前这两个数据集上最佳表现。
因子分析
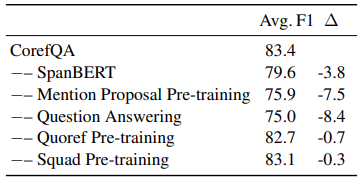
1、各组件影响
下表呈现了所提出模型中各组件的影响,可以看到,SpanBERT影响很大,而QA影响最大,去掉它会降低8.4个F1值,而在问答数据集上的预训练也有较大影响。这说明问答本身对所提出模型是至关重要的。
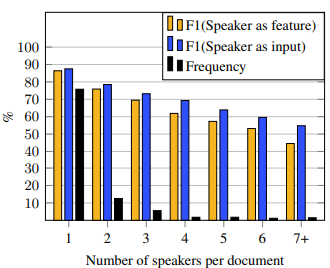
说话者表示的影响
在我们的模型里,我们把每个说话者的姓名当做一个单独的符号处理,而过去的方法则是把说话人转化为二元特征来表示两个指称是否来自同一个说话人。
下图是两种方法的比较,可见,随着说话者数量的增加,我们的方法具有更显著的优势,这是因为单纯的特征表示无法处理说话人多的情况,只有显式地表示每个说话人,才能区别其中的指称。
召回率分析
前面提到,问答的方法可以减少指称提取的错误传递,从而会有更高的召回率。下图证明了这一点。即使平均每个词只保留20个文段作为候选指称,其召回率也有90+。

小结
在本文,我们提出了一个基于问答框架的共指消解模型,通过指称抽取——指称链接两个步骤,完成对共指词的聚类。这种方法能够在两个标准数据集上实现当前最优效果,并通过一系列分析实验证明“问答”本身具体至关重要的作用。
进一步讨论:问答模式是否有益
包含本文在内,我们已经介绍了三篇基于“问答”框架的文章了(前两篇是关系抽取和实体抽取),它们都能获得非常显著的效果提升,甚至实现最优结果。
那么一个自然的问题是,这种问答框架是否对所有NLP任务都适用呢?
其实从直觉上讲,广义上的问答无非是为模型提供了额外的上下文信息,使得模型能够更简单地得到答案。
于是,两个问题随之而来:提供什么信息,怎么提供信息。提供什么信息是要选择怎样的文本作为“问题”,选取怎样的文本作为“上下文”。怎么提供信息是信息组织的方法,也即针对这种形式所设计的模型结构。
当前,对“提供什么信息”这个问题,我们还仅仅是从原始文本中抽取,或者用预先定义的模板;对“怎么提供信息”这个问题,我们仅仅是使用了BERT等预训练模型。我们相信,如何更好地解决这两个要点,是此方法发展的方向。
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京/深圳
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:cenfeng@leiphone.com




