【语音算法系列】Rescore,语言模型的翅膀(一)
语言模型重打分技术(Language Model Rescore)是一种在语音识别系统中使用大语言模型或多语言模型的方法。在本文中,我们将主要介绍语言模型重打分的技术背景,并着重介绍基于N元语法的语言模型重打分技术的基本原理、具体工程实现以及相关优化方法。
为什么引入语言模型重打分技术
语言模型(Language Model)是语音识别系统的重要组成部分,它往往和声学模型配合来使用。语言模型和声学模型的建模质量往往决定整个语音识别系统的准确率和鲁棒性等性能,所以,如何充分利用海量文本的先验知识,对降低语音识别错误率非常重要。
首先引入一张图来解释一下语言模型在语音识别链路中的哪些环节发挥作用。
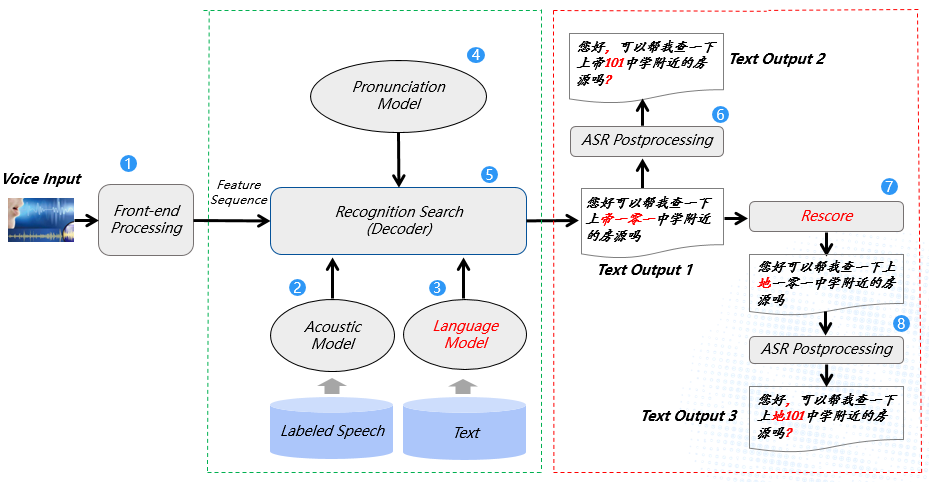
图1 语音识别基本框架
在语音识别基本框架图中,原始语音信号在经过前端信号处理和特征抽取后,流向了标号为5的解码网络进行搜索,然后会输出第一次识别(One Pass)后的最佳文本,在此过程中,标号为3的语言模型发挥作用,其文本序列的概率分布影响了最终识别结果。紧接着,Text Output 1直接经过后处理模块润色后输出包含“上帝101中学”的识别结果,可以发现该识别结果是错误的(“上地”误识别成了“上帝”),出现这样的音同字不同的错误情况,一般是由于语言模型建模质量不佳引起的。为了降低识别的错误,One Pass的识别结果又经过了标号为7的建模质量更佳的语言模型重新进行概率打分调整(Rescore,Two Pass),最终输出了包含“上地101中学”的正确识别结果。
在上图中,我们用到了两个语言模型,分别是用来构图并进行One Pass识别的小语言模型(N元语法模型),另一个是用作Two Pass 重打分的大语言模型(N元语法模型或神经网络语言模型等),看到这里,读者可能心中会有产生疑问:为什么不直接在One Pass过程中就选用一个性能更佳的语言模型呢?
这是由于“构图”和“解码”的原理所致。具体来说,对使用静态解码器的语音识别系统而言,构建语音识别系统的过程包括一个叫做“构图”的步骤。在“构图”的过程中,我们需要将包括语言模型在内的很多信息“编译”成“图”的形式(“图”将在后文原理部分处进行解释),而这一步依赖于N元语法模型的结构,并且“构图”对机器内存的要求非常高,将直接限制可应用模型的大小。
先来看一个具体的实例。
| 声学模型状态数 | 音素上下文 | 词典 | Gram数量 | G.fst内存占用 | HCLG.fst内存占用 |
|---|---|---|---|---|---|
| 1万 | Triphone | 10万 | 4400万 | 4G | 40G |
表1 构图内存占用案例
上表是一个构图过程内存占用的实际案例,语言模型为4元语法模型,共包含了4400万条Gram,词典包含了约10万规模的词语,声学音素上下文为三音素,声学模型状态数约为1W,在语言模型编译成G.fst的过程中,占用约4G的内存,在编译解码网络HCLG.fst的过程中,占用约40G内存。如果开发环境的机器配置在160G内存左右,则估算其实际可以支持包含大约2亿条Gram的语言模型构图。
大数定律定义了在随机事件的大量重复出现中,往往呈现几乎必然的规律,即在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率。这也就决定了在语音识别中,为了训练一个估计概率分布接近语言真实概率分布的模型,训练语料规模一般需要非常巨大(数百GB或TB级别),这样会导致训练后得到的模型也会很大(一般规模会达到数十亿条Gram)。如果语言模型很大,在一遍解码“构图”的过程中,构建HCLG.fst的过程所需的内存会非常巨大(可能超过数百G,甚至超过1T),从而导致构图失败。因此,如果想要使用通过大规模语料训练得到的语言模型,就必须想一些其他的方法。
一种方法就是将大语言模型中不重要的信息去除,尽可能多的保留有用信息,比较常见的方法就是语言模型剪枝技术。
齐夫定律描述了在自然语言的语料库里,一个单词出现的频率与它在频率表里的排名成反比。用一个直观现象描述就是,频率最高的单词出现的频率大约是出现频率第二位的单词的2倍,而出现频率第二位的单词则是出现频率第四位的单词的2倍,以此类推。在语音识别中,聊天说话的内容往往是出现频率较高的词语,这部分词语在词典中往往数量占比不多(一般小于5%),而出现频率低并处于尾部的词语往往很多,即长尾效应,去掉这部分词的一些信息往往对整体影响不大,而且可以消减模型大部分尺寸。
所以,当我们通过大规模文本语料库训练好一个巨大的ARPA格式语言模型后(定义为G.arpa),一般会将其尺寸进行裁剪,以得到一个大小和性能都合适的模型(定义为g.arpa),裁剪方式一般选用交叉熵剪枝方法(Entropy-based Pruning of Backoff Language Models)。下图为应用交叉熵剪枝方法在不同剪枝阈值下的模型性能变化。
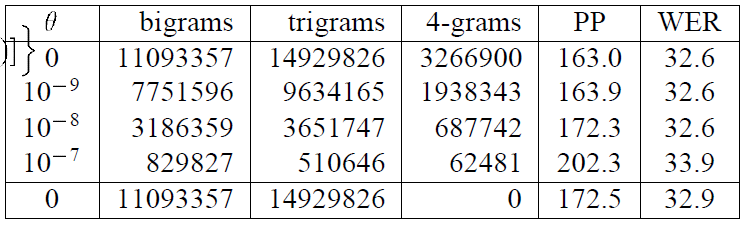
图2 不同剪枝阈值下的模型性能变化
从上图中可以看出,剪枝前后的模型Gram数量变化很大,但是对性能影响却很小,以裁剪系数 为例,剪枝后模型的整体Gram数量下降到了原始Gram数量的4.7%左右,但是对词错误率(Word Error Rate)只有不到4%的性能下降。
一般来说,裁剪后的语言模型或多或少会有一定的性能损失(不同场景可能因为测试集覆盖率较低导致性能损失较小),那有没有什么办法可以充分利用大语料训练的N-Gram语言模型信息或者是结合其他类型的语言模型(如神经网络语言模型)信息到解码器中呢,这就要用到语言模型重打分技术了,在语音识别应用中,其主要可以分为以下两种:
-
基于N元语法的语言模型重打分技术; -
基于神经网络的语言模型重打分技术;
本文将重点介绍基于N元语法的语言模型重打分技术的基本原理和其在语音静态解码器中的应用。
基于N元语法的语言模型重打分技术的基本原理
前面,我们提到了在构建语音识别系统的过程包括一个叫做“构图”的步骤,在“构图”的过程中,需要将包括语言模型在内的很多信息“编译”成“图”的形式,这一步主要包括4个小“图”和一个大“图”的“编译”。
-
声学HMM模型的拓扑结构和状态转移概率会“编译”成H.fst格式的“图”,输入是transition-id (Kaldi 所定义,PDF 及相关转移操作所对应的ID,每一帧语音都会对应一个transition-id),输出是三音素(Triphone); -
音素的上下文关系会“编译”成C.fst格式的“图”,输入是三音素,输出是音素(Phone); -
识别词典会“编译”成L.fst格式的“图”,输入是音素,输出是词; -
ARPA格式的语言模型会“编译”成G.fst格式的“图”语言模型,输入是词,输出也是词;
完成4个小“图”的构建后,还需要再将多个“图”整合到一起,得到一个最终的解码大“图”(HCLG.fst)。如此一来,解码任务(或者说语音识别任务)就转化成了在解码图上搜索最优路径的问题,此时的解码图已经可以完成从transition-id到Triphone,再到Phone,再到Word,最后完成整个Sentence输出的过程。
上述多个“图”整合的过程也可以看作是“图”展开的过程,在“图”一步一步展开的过程中,因为语言模型“图”规模一般非常庞大,所以最终的“构图”内存占用量与语言模型的大小有着最为直接的关系。如果语言模型很大,则构建HCLG.fst的过程会因为所需内存过于巨大从而导致构图失败。
为了充分利用大语言模型的信息,基于WFST的解码方法对这个问题的解决思路是先使用一个较小的语言模型来构造g.fst,从而可以构造出HCLg.fst,然后用这个网络进行一遍解码,可以得到一遍解码Lattice(网格,后文详细介绍),对得到的网格用G.fst 进行语言模型得分修正(减去小语言模型得分,加上大语言模型得分),然后可以得到二遍解码Lattice 或者直接得到识别结果,具体架构如下图所示。
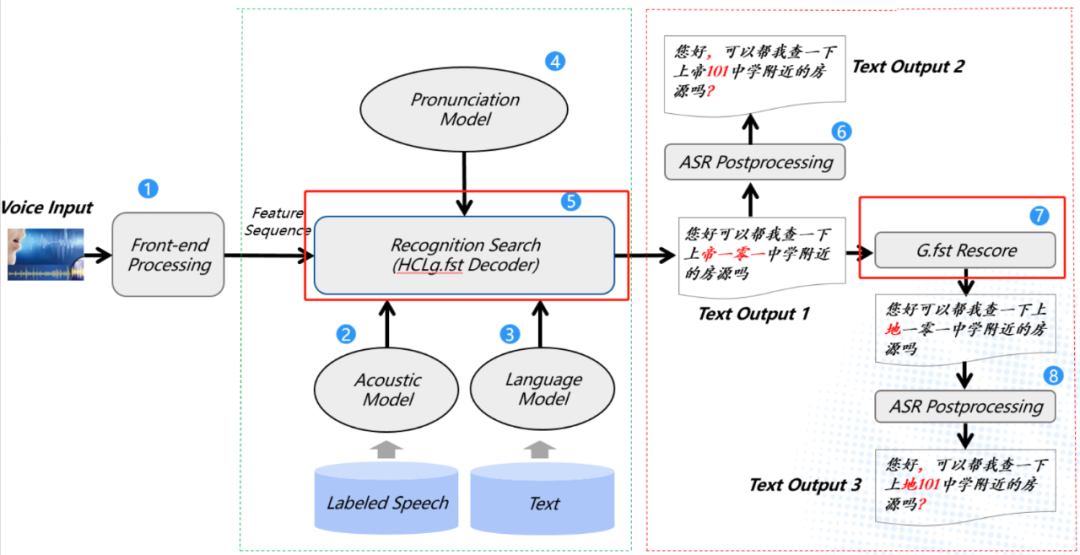
图3 HCLg.fst一遍解码与G.fst Rescore架构图
这样做有几个好处:
-
可以在内存资源有限的情况下充分利用N-Gram大语言模型的信息; -
架构灵活,可以只使用一遍解码模型信息,也可以只使用二遍解码模型信息,也可以共同使用两个模型信息,类似语言模型插值技术; -
在Lattice上面进行得分修正,可以多次重复进行,即支持利用多个语言模型的信息; -
在语音静态解码器架构上面,很容易扩展使用神经网络语言模型进行重打分; -
一遍解码使用小模型,解码速度可以更快,且在一遍解码保证召回的情况下,利用二遍解码可以提高准确率;
构图和解码原理简介
在了解语言模型重打分的实现细节之前,我们首先需要对构图和解码的原理有一些基本的了解。我们首先来介绍FST(Finite State Transducer)。FST是一种有向图,在图上有若干节点,其中有1个起始节点,有若干个最终节点。节点与节点之间由有方向的边来连接,每条边上有Input Label、Output Label、Weight这3个信息。FST可以用来表示2组串之间的关系。具体来说,在FST图上,从起始节点出发,到任意一个最终节点为止的路径,是一条有效路径。把有效路径当中每条边的Input Label连在一起,可以得到一个串;把每条边的Output Label连起来,可以得到另一个串,这条路径的存在,就表明了这2个串之间有关系,而这条路径上的Weight,则可以用来表示这个关系的“程度”。一个FST图中包含很多有效路径,因此一个FST图就可以表示2组串之间的关系。
例如在语音识别中,我们会用到发音词典(Lexicon),发音词典当中包含了音素(Phone)串和词之间的映射关系,我们可以把这种关系用FST的形式来表示。我们习惯将发音词典编译所得的FST图称为L.fst,在L.fst中,Input Label为音素,Output Label为词。L.fst每一条有效路径,都表示了特定的音素串和特定的词之间的关系。同样的,语言模型的信息也可以表示成FST的形式,我们习惯称语言模型编译成的FST图为G.fst。在G.fst中,Input Label与Output Label是一致的,都是词。G.fst中的每一条有效路径,其Label串是一个词串(即句子),而路径的Weight值则是这句话的语言模型概率。与此类似的,我们的声学模型建模单元,一般是三音素(Triphone)的HMM状态(HMM State)再经过聚类所得。因此还可以得到Triphone串和Phone串之间的关系(C.fst),以及HMM State和Triphone之间的关系(H.fst)。
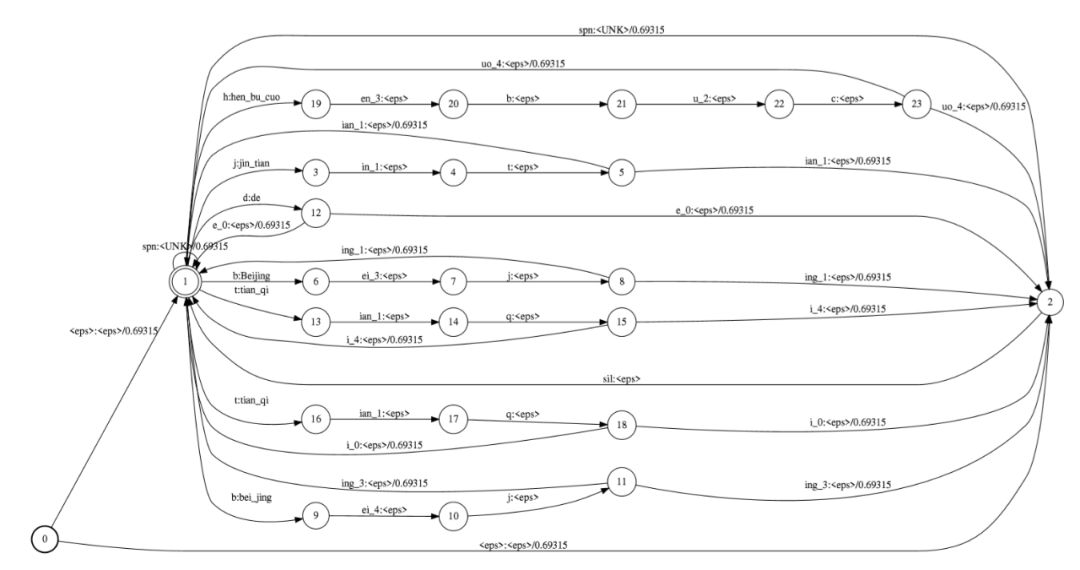
图4 由发音词典“编译”所得的L.fst
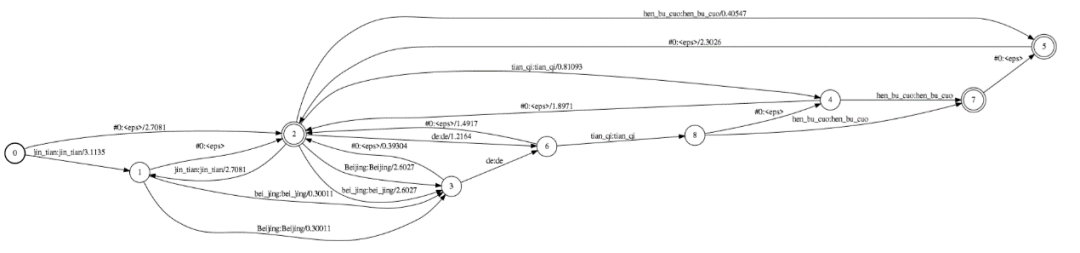
图5 由语言模型“编译”所得的G.fst
FST除了可以用来表示关系之外,还定义了一系列操作,可以对这些“关系图”进行操作。其中最重要的是Compose操作。Compose操作可以将2个图合并成1个图,也就是可以把2个关系合并成1个关系。例如,我们已经有了L.fst(Phone串和词的关系)和G.fst(词和句子的关系),那么如果对L.fst和G.fst做Compose操作,就可以得到LG.fst(Phone串和句子的关系)。在LG.fst中,任何一条有效路径上的Output Label的串都是一个句子,Input Label的串是这句话的Phone串,路径的Weight之和是这句话的同时考虑了发音词典和语言模型之后总的概率,或者更准确地说是总的损失(Cost)。
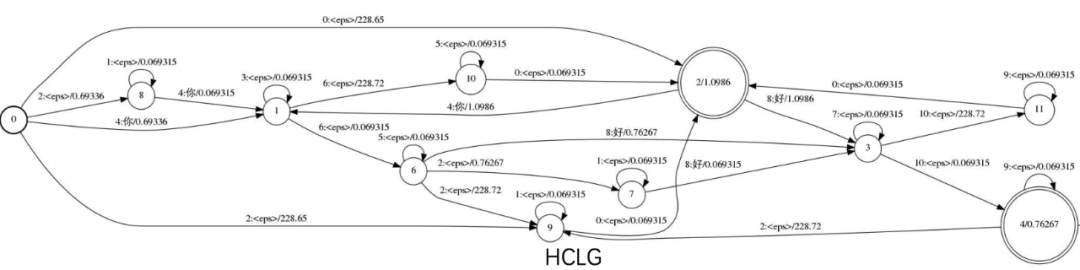
图6 包含“你”和“好”两个词的HCLG.fst
利用Compose操作,我们还可以进一步把C.fst与LG.fst合并为CLG.fst,再将H.fst与CLG.fst合并为HCLG.fst。HCLG.fst就是我们最终的解码图。这个过程就是构图过程。在HCLG.fst中,Output Label的串依然是词串,也就是句子,而Input Label的串是HMM State的串,也即刚好与我们的声学模型建模单元相吻合,这样我们就获取到了声学模型建模单元和语言模型建模单元的关系,就可以把帧级别的声学模型概率和词级别的语言模型概率结合在一起,来搜索最优路径。值得一提的是,构图的方法有很多种,上述介绍的只是其中一种。
解码网格(Lattice)简介
我们知道,解码过程实际上就是在解码图上搜索最优路径的过程,最优指的是这条路径的Cost最低,而Cost实际上分为两部分。其中一部分是解码图中各条边上的Weight值所代表的信息,这部分Cost综合考虑了语言模型概率(G.fst)、Lexicon中的概率(L.fst)、Phone和Triphone的对应关系(C.fst)、HMM结构中的概率(H.fst),称为Graph Cost。另一部分则是声学模型提供的信息,这部分是根据语音信号实时计算,并根据解码图上的Input Label去查找声学模型输出向量的相应维度来获取的,称为AM Cost。
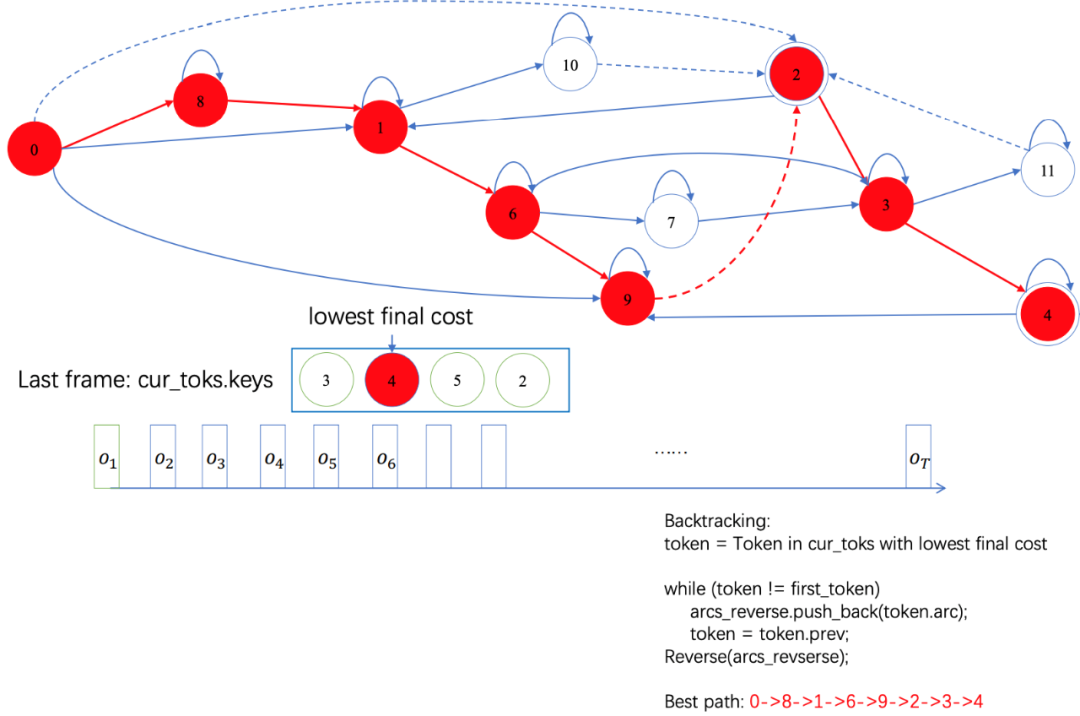
图7 解码器搜索过程
解码网格Lattice本质上也是一个FST,它实际上是经过解码搜索之后,未被剪枝的、被保留下来的解码图的一部分。但它有一个特殊之处。一般的FST每条边上只有一个Weight值,比如在解码图HCLG.fst中,每条边上的Weight对应着解码过程中的Graph Cost。而Lattice的特殊之处在于,每条边上有2个Weight值,分别对应着解码过程中的Graph Cost和AM Cost。
语言模型重打分的工程实现和优化
在后文中,我们用g代表“旧语言模型”,也就是用于构图的语言模型;用G来表示“新语言模型”,也就是真正想要使用的语言模型。在了解了语言模型重打分和构图、解码的基本原理之后,我们知道,LM Rescore的本质,就是要从原有的解码网格中减掉g.fst的概率,然后再加上G.fst的概率。需要注意的是,g.fst的概率并不等同于Graph Cost,因为Graph Cost当中还包含H.fst、C.fst、L.fst中的Weight值。因此想要减掉g.fst的概率,不能直接把Graph Cost置零,然后加上G.fst的概率,这样会丢失H、C、L中的信息。正确的做法是,首先从Graph Cost中减去g.fst的概率,再加上G.fst的概率。
LM Rescore的一种实现方式,是利用FST的Compose操作。我们可以首先利用HCLg.fst进行一遍解码,得到Lattice,然后构造一个g’.fst。g’.fst与g.fst的图结构保持一致,但所有的Weight都取g.fst的相反数。之后把Lattice和g’.fst进行Compose操作,就可以得到一个减去g.fst概率的Lattice’;然后再用Lattice’与G.fst进行Compose操作,这样就得到了我们所需要的使用G.fst进行重打分的Lattice。之后可以利用这个新的Lattice来获取识别结果。但这种做法有一个相当大的弊端,那就是Compose操作相当费时,连续2次Compose操作会导致LM Rescore的速度很慢。由于LM Rescore必须在获取完整的Lattice之后才能进行,因此它会增加实时识别任务的延迟,极度影响用户体验。为了避免这种情况,我们对LM Rescore进行了进一步优化。
首先第一个优化点是Compose操作。实际上,在LM Rescore的过程中,我们只是希望计算新旧语言模型的概率,找到二者之间的差异,并不需要对Lattice和g’.fst做真正的Compose操作,同理Lattice'和G.fst也没有必要做真正的Compose操作。我们只需要在必要时,进行动态的Compose即可。具体而言,我们定义了一种特殊的FST类,形式上把g’.fst和G.fst整合在一起,成为1个diff.fst,但实质上g’.fst和G.fst却依然是2个FST,分别保存在diff.fst对象的私有变量中。只有在我们搜索Lattice的过程中,发现Lattice中特定边的Output Label是一个词,而不是空(eps
值得一提的是,使用这种动态搜索的方法,在g’.fst和G.fst中计算语言模型概率,需要g’.fst和G.fst满足一定的前提条件——从任意一个节点出发,Label为特定值的边只有一条。只有满足这个条件,我们才可以使用这种类似动态Compose的方法。幸运的是,只要FST图是由ARPA格式的N-gram语言模型编译生成的,那么它就天然满足这个条件,这是由ARPA格式的定义和N-gram语言模型计算语言模型概率的方式决定的。
即便用了动态Compose的方法,有时LM Rescore还是相当耗时。主要原因是,如果一遍解码获得的Lattice比较大,或者G.fst比较大,都会导致搜索过程中的候选路径过多,在这种情况下,即使是动态计算语言模型概率,耗时也比较多。因此我们不得不考虑进行另外一种优化——剪枝。
与普通的一遍解码类似,在重打分的过程中,也涉及到搜索最优路径的问题,因此在重打分的过程中,也可以利用一定的规则进行剪枝。比如通过设置Beam来限制搜索过程中,任意时刻存活的路径距离当前局部最优路径的差距不能超过Beam值;再比如通过设置max_arcs来限制lattice中,边的数量不能超过max_arcs等等。除此之外,我们还可以利用启发式的方法,在Compose的过程中,在没有真正到达最终节点之前,就估算出当前Compose所得的各节点,沿着最优路径到达最终节点时的Cost值。因此我们可以使用优先队列来存储、扩展搜索路径。这也在很大程度上提高了搜索的速度。
以下为解码器优化前后效果对比实例。
我们使用了一个包含1351条语音,总时长约2h的测试集,对LM Rescore的速度进行了测试。在此我们只统计LM Rescore的耗时,不包含一遍解码的耗时。
| 耗时(ms) | 平均值 | TP50 | TP90 | TP95 | TP99 |
|---|---|---|---|---|---|
| 优化前 | 41.452 | 19.208 | 63.063 | 113.41 | 473.91 |
| 优化后 | 2.8671 | 1.9710 | 6.3779 | 8.3320 | 13.878 |
表2 LM Rescore优化前后的速度对比
从上表的结果可以看出,通过上述优化方法,LM Rescore的速度有了显著的提升,平均速度提升了十几倍。更重要的是,针对极端情况的耗时,从几百毫秒的量级下降至十几毫秒的量级,这就把对实时识别任务的延迟的影响,降低到了几乎可以忽略的程度。与此同时又提升了语音识别的准确率,并且也给未来使用更大的语言模型提供了可能。
总结及未来展望
本文主要介绍了语言模型重打分的技术背景,并着重介绍了基于N元语法的语言模型重打分技术的基本原理、具体工程实现以及相关优化方法。在不久的将来,我们将对语言模型重打分技术的另一个主要方法:基于神经网络的语言模型重打分技术,进行总结和分享,敬请期待。
作者介绍
阮海鹏,2019年10月加入贝壳,主要从事语音识别-语言模型相关工作。
赵梦原,2019年12月加入贝壳,主要从事语音识别-解码器相关工作。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏