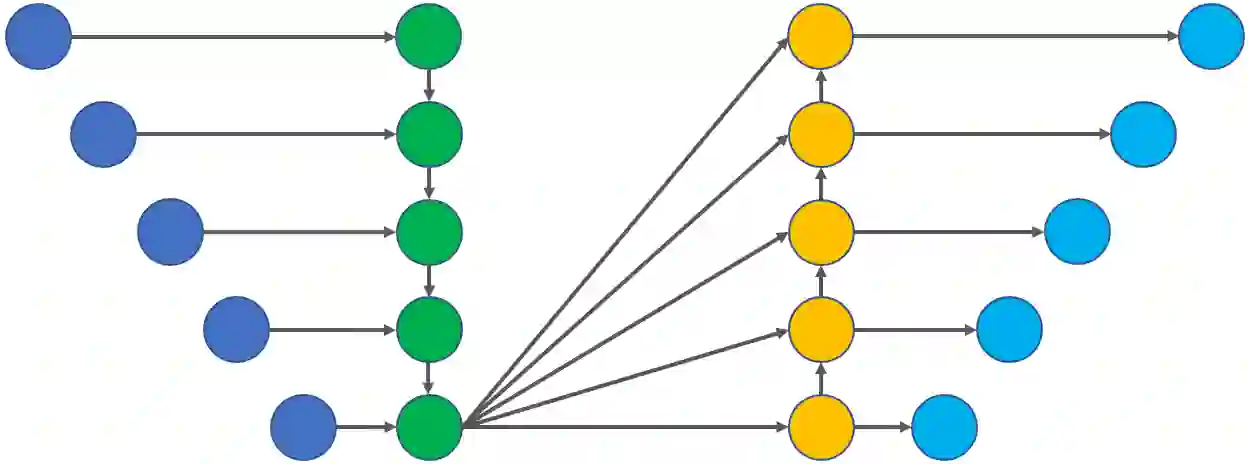
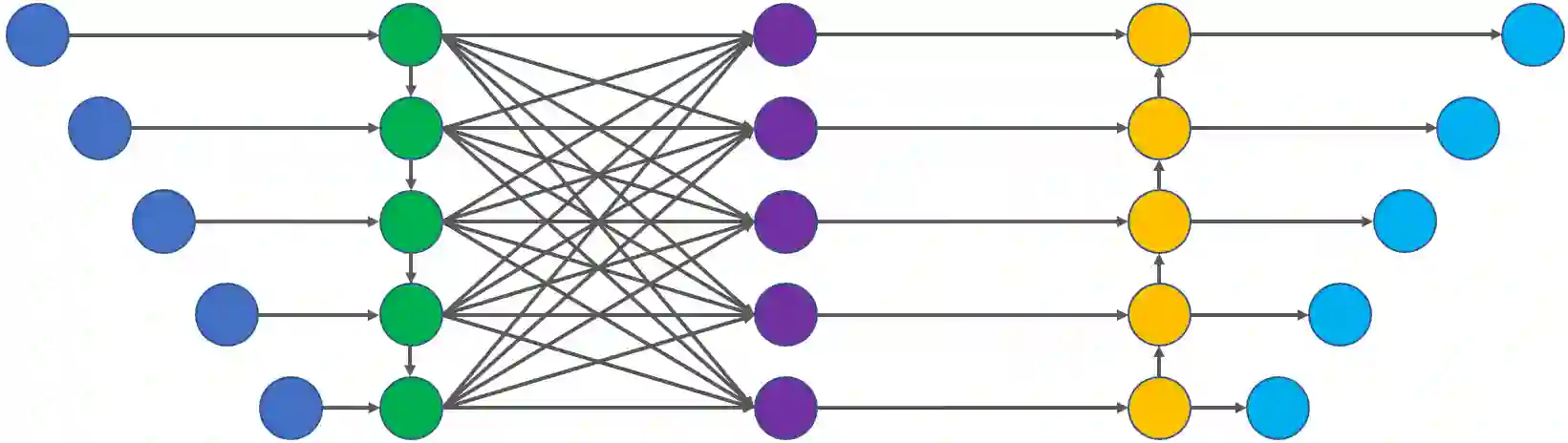
Over the last several years, the field of natural language processing has been propelled forward by an explosion in the use of deep learning models. This survey provides a brief introduction to the field and a quick overview of deep learning architectures and methods. It then sifts through the plethora of recent studies and summarizes a large assortment of relevant contributions. Analyzed research areas include several core linguistic processing issues in addition to a number of applications of computational linguistics. A discussion of the current state of the art is then provided along with recommendations for future research in the field.
翻译:在过去几年里,自然语言处理领域因使用深层学习模式的爆炸性发展而向前推进,该调查简要介绍了实地情况,并简要概述了深层学习结构和方法,然后通过大量近期研究筛选,并概述了大量相关贡献。分析研究领域除了若干计算语言应用外,还包括若干核心语言处理问题。然后,对当前技术现状进行讨论,同时提出有关今后实地研究的建议。