机器之心 & ArXiv Weekly Radiostation
本周论文包括:美国加州劳伦斯利弗莫尔国家实验室国家点火装置(National Ignition Facility)研究者的一项研究登上了最新一期的《自然》杂志的封面;苏黎世联邦理工学院计算机视觉实验室(CVL)的研究者提出了 RePaint,可以在极端情况下修复图像。
Burning plasma achieved in inertial fusion
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
LaMDA: Language Models for Dialog Applications
VIDT: AN EFFICIENT AND EFFECTIVE FULLY TRANSFORMER-BASED OBJECT DETECTOR
Ten Lessons From Three Generations Shaped Google’s TPUv4i
OMNIVORE: A Single Model for Many Visual Modalities
UniFormer: Unifying Convolution and Self-attention for Visual Recognition
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Burning plasma achieved in inertial fusion
摘要:今日,美国加州劳伦斯利弗莫尔国家实验室国家点火装置(National Ignition Facility)研究者的一项研究登上了最新一期的《自然》杂志的封面。研究者成功地激发了一种持续很短时间的聚变反应,这是一项重大的壮举,因为聚变需要非常高的温度和压力,很容易熄灭。这项研究的最终目标是像太阳产生热量一样实现发电,通过压碎氢原子并使它们彼此靠近,然后生成氦以释放大量的能量。但是,自理论提出以来,人们和这个目标的距离一直是「需要数年时间」。
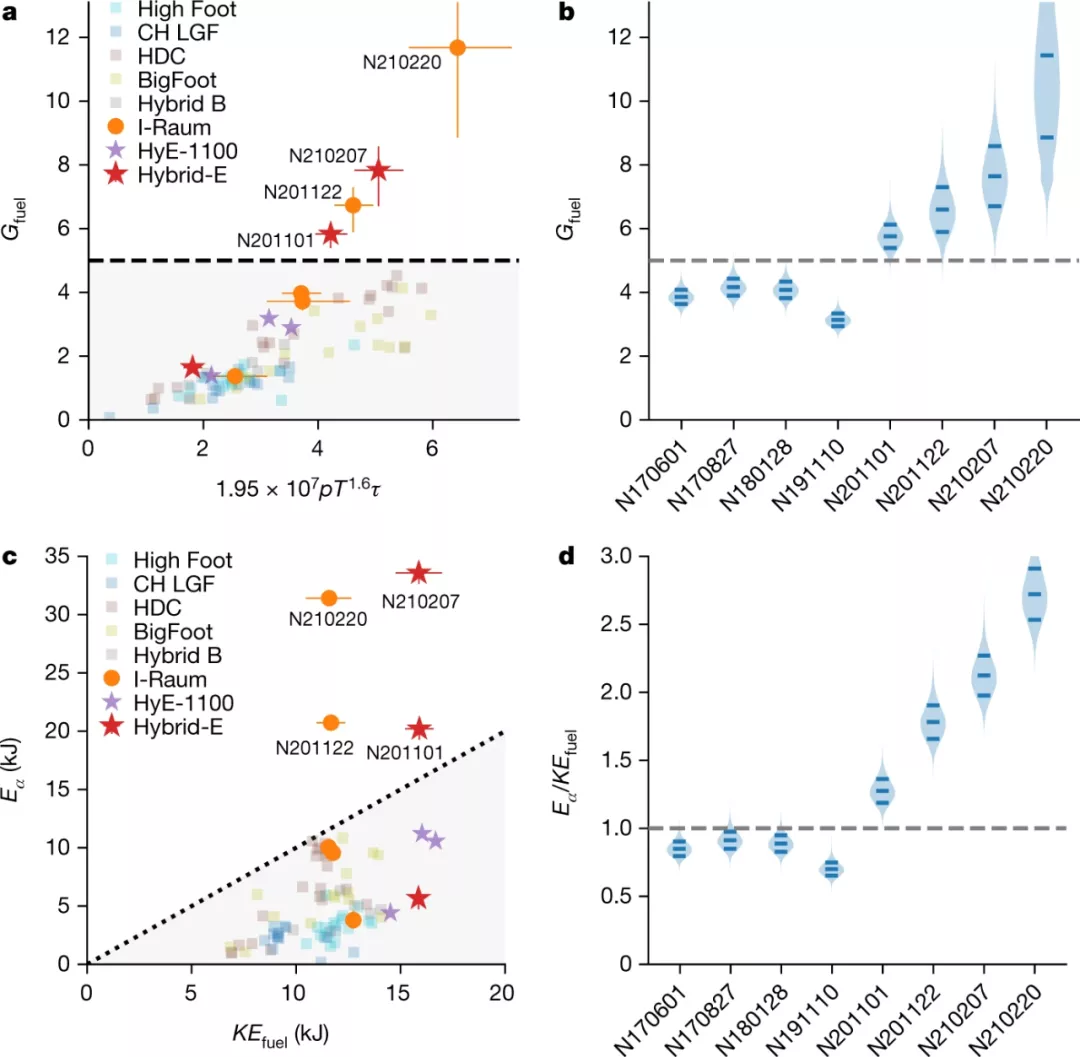
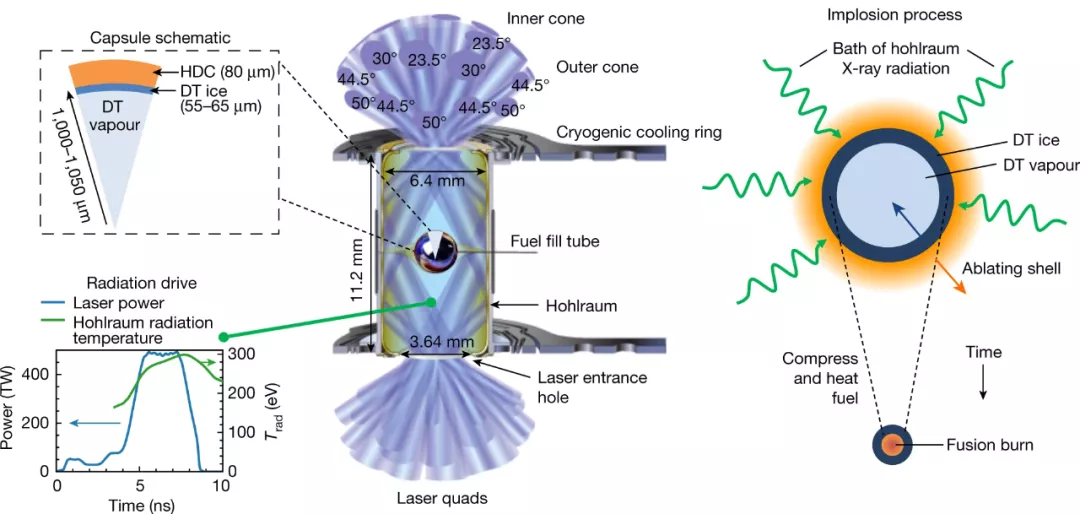
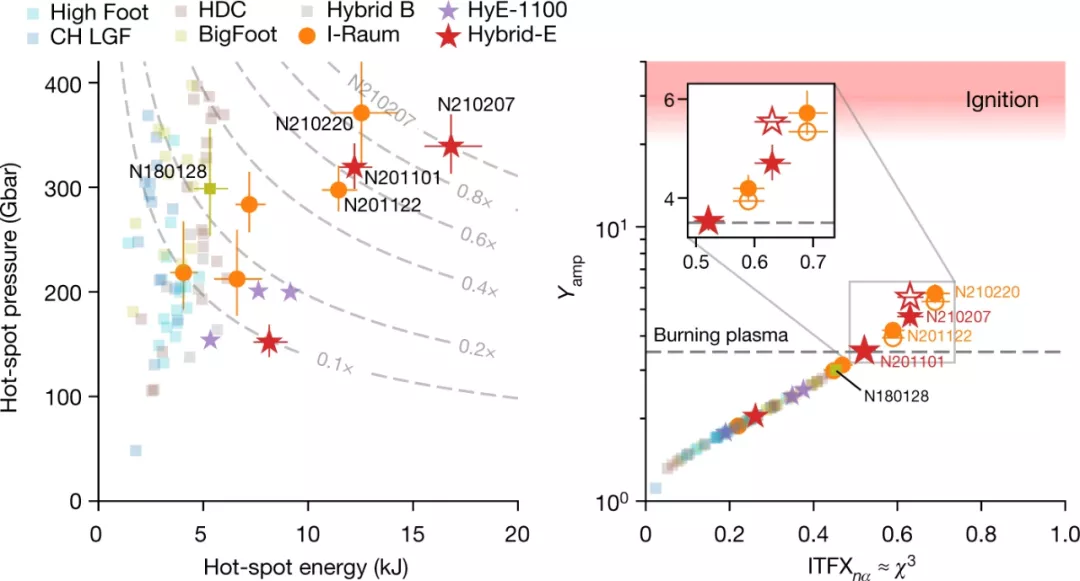
获得燃烧等离子体是实现自持(self-sustaining)聚变能量的关键一步。燃烧等离子体是一种等离子体,其中聚变反应本身是等离子体中加热的主要来源,对于维持和传播燃烧是必需的,可以实现高能量增益。经过数十年的聚变研究,研究者在实验室中实现了燃烧等离子体状态,其中一个激光装置可以在燃料胶囊中提供高达 1.9 兆焦耳的脉冲能量,峰值功率高达 500 太瓦。他们使用激光在辐射腔中产生 X 射线,然后通过 X 射线烧蚀压力间接驱动燃料胶囊,从而使得内爆过程通过机械功压缩和加热燃料。这些实验表明,聚变自热(fusion self-heating)超过了注入内爆的机械功,满足了几项燃烧等离子体指标。此外,研究者描述了一个似乎已经跨越静态自热边界的实验子集,其中聚变加热超过了辐射和传导的能量损失。这些结果为在实验室中研究以 α 粒子为主的等离子体和燃烧等离子体物理学提供了机会。
![]()
此前,研究者在实验室中已经花了好几年的时间,而且很多尝试都失败了。他们做出了调整:将燃料胶囊( fuel capsule)增大了 10%。燃料胶囊装在一个微小的黄金金属柱体中,研究者将 192 束激光对准该柱体。研究者将它加热到 1 亿度,在燃料胶囊内部产生的压力比太阳中心内部的压力高出 50% 左右。Alex Zylstra 表示,这些实验创造了持续了仅万亿分之一的燃烧等离子体,但这足以被认为是成功的。
![]()
总的来说,该研究中做的四项实验(分别做于 2020 年 11 月和 2021 年 2 月)产生了 0.17 兆焦耳(megajoule)的能量,远远超出了以往的尝试,但仍然不到启动该过程所用能量的十分之一。作为对比,一兆焦耳的能量大约可以将一加仑(约 3.8 升)的水加热到 100 华氏度(约 37.8 摄氏度)。
![]()
根据之前的信息,2021 年晚些时候所做实验的初步结果仍在接受其他科学家的审查,当时研究者能量输出达到了 1.3 兆焦耳,并持续了 100 万亿分之一秒。但即便如此,这个数值也低于达到收支平衡所需的 1.9 兆焦耳。
推荐:
Nature 封面:可控核聚变里程碑式新进展,燃烧等离子体实现。
论文 2:RePaint: Inpainting using Denoising Diffusion Probabilistic Models
摘要:
图像修复旨在填充图像中的缺失区域,被修复区域需要与图像的其余部分协调一致,并且在语义上是合理的。为此,图像修复方法需要强大的生成能力,目前的修复方法依赖于 GAN 或自回归建模。近日,来自苏黎世联邦理工学院计算机视觉实验室(CVL)的研究者提出了 RePaint,这是一种基于 DDPM(Denoising Diffusion Probabilistic Model,去噪扩散概率模型)的修复方法,该方法还可以适用于极端情况下的蒙版。
它的修复效果是这样的,RePaint 使用扩散模型填充缺失的图像部分:下面示例中,蓝色部分是图像缺失部分,也就是需要 RePaint 修复的部分,RePaint 会根据已知的部分生成缺失的部分。它的修复过程是这样的:首先从纯粹的噪音开始,然后对图像逐级降噪,中间的每一步使用图像已知部分来填充未知部分。
![]()
RePaint 还能重新绘制不同内容和形状的缺失区域,创建许多有意义的填充物。如面部表情和特征,如耳环或痣:
![]()
上述图像修复过程采用预训练的无条件 DDPM 作为生成先验。为了调节生成过程,该研究仅通过使用给定的图像信息对未掩码区域进行采样来改变反向扩散迭代。由于该技术不会修改或调节原始 DDPM 网络本身,因此该模型可以为任何修复形式生成高质量和多样化的输出图像。在实验部分,该研究使用标准和极端蒙版验证了面部和通用图像修复方法。RePaint 在六种掩码分布中至少有五种优于 SOTA 自回归和 GAN 方法。
推荐:
优于 GAN、带上口罩都能还原,用去噪扩散概率模型极限修复图像。
论文 3:LaMDA: Language Models for Dialog Applications
摘要:
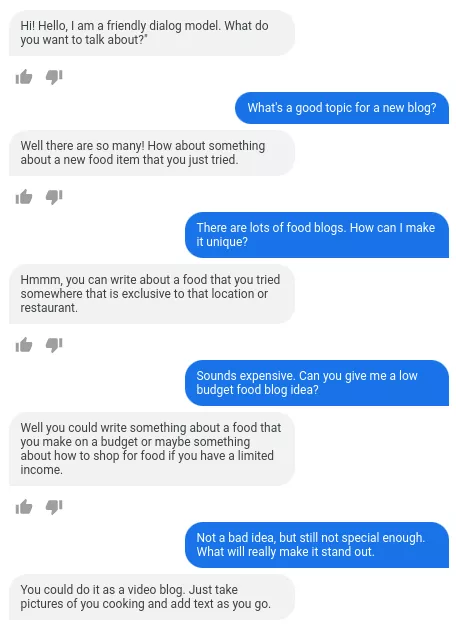
近日,超过 50 多位谷歌研究者参与撰写的论文《 LaMDA: Language Models for Dialog Applications 》介绍了语言模型 LaMDA 的最新进展。论文概括了他们如何在安全、可靠和高质量的对话应用程序方面取得进展。LaMDA 通过微调一系列专门用于对话的、基于 Transformer 的神经语言模型构建的,具有多达 137B 个参数,模型还可以利用外部知识源进行对话。
在定义了目标和度量之后,谷歌描述了 LaMDA 的两阶段训练:预训练和微调。
LaMDA 预训练在预训练阶段,谷歌首先从公共对话数据和其他公共网页文档中收集并创建了一个具有 1.56T 单词的数据集,是用于训练以往对话模型的单词量的近 40 倍。在将该数据集标记为 2.81T SentencePiece token 之后,谷歌使用 GSPMD 预训练模型,以预测句子中的所有下一个 token。预训练的 LaMDA 模型已被广泛应用于谷歌的自然语言处理研究中,包括程序合成、零样本学习、风格迁移等。
LaMDA 微调:在微调阶段,谷歌训练 LaMDA,执行混合生成任务以生成对给定上下文的自然语言响应,执行关于响应是否安全和高质量的分类任务,最终生成一个两种任务都能做的多任务模型。LaMDA 生成器被训练预测限制为两个作者之间来回对话的对话数据集上的下一个 token,LaMDA 分类器被训练预测使用注释数据在上下文中生成的响应的安全与质量(SSI)评级。对话期间,LaMDA 生成器首先在给定当前多轮对话上下文时生成几个候选响应,然后 LaMDA 预测每个候选响应的 SSI 和安全分数。安全分数低的候选响应首先被过滤掉,剩下的候选响应根据 SSI 分数重新排名,并选择分数最高的作为最终响应。谷歌使用 LaMDA 分类器进一步过滤掉用于生成任务的训练数据,以增加高质量候选响应的密度。
![]()
![]()
LaMDA 通过合理、特异和有趣的方式处理任意用户输入。
推荐:
1370 亿参数、接近人类水平,谷歌对话 AI 模型 LaMDA 放出论文。
论文 4:VIDT: AN EFFICIENT AND EFFECTIVE FULLY TRANSFORMER-BASED OBJECT DETECTOR
摘要:
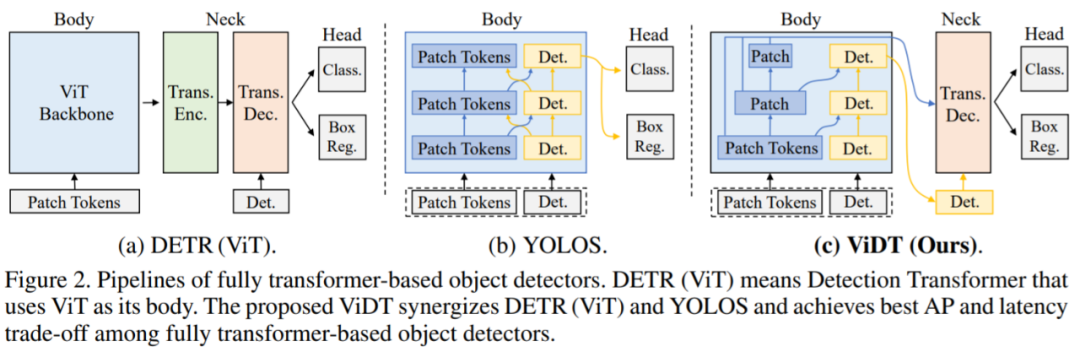
Transformer 在 NLP 任务中取得不错的发展,许多研究将其引入到计算机视觉任务中。毫不夸张的说,Transformer 正在改变计算机视觉的格局,尤其是在识别任务方面。例如 Detection transformer 是第一个用于目标检测的、端到端的学习系统,而 vision transformer 是第一个完全基于 transformer 的图像分类架构。在本文中,一篇被 ICLR 2022 接收的匿名论文集成了视觉和检测 Transformer (Vision and Detection Transformer,ViDT) 来构建有效且高效的目标检测器。
ViDT 引入了一个重新配置的注意力模块(reconfigured attention module),将 Swin Transformer 扩展为一个独立的目标检测器,之后是一个计算高效的 Transformer 解码器,该解码器利用多尺度特征和辅助(auxiliary)技术,在不增加计算负载的情况下提高检测性能。
在 Microsoft COCO 基准数据集上的评估表明,ViDT 在现有的完全基于 transformer 的目标检测器中获得了最佳的 AP 和延迟权衡,其对大型模型的高可扩展性,可达 49.2AP。
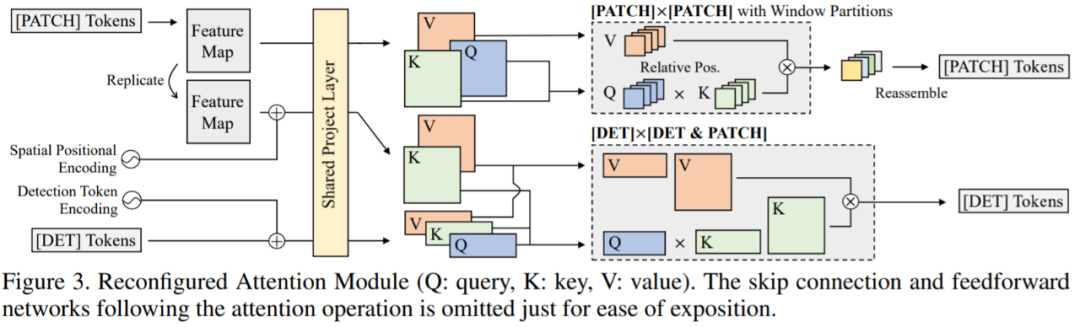
首先,ViDT 引入了一种改进的注意力机制,名为 Reconfigured Attention Module (RAM),该模块有助于 ViT 变体处理附加的 [DET(detection tokens)] 和 [PATCH(patch tokens)] token 以进行目标检测。因此,ViDT 可以将最新的带有 RAM 的 Swin Transformer 主干修改为目标检测器,并利用其具有线性复杂度的局部注意力机制获得高可扩展性;
其次,ViDT 采用轻量级的无编码器 neck 架构来减少计算开销,同时仍然在 neck 模块上启用额外的优化技术。请注意,neck 编码器是不必要的,因为 RAM 直接提取用于目标检测的细粒度表示,即 [DET ] token。结果,ViDT 获得了比 neck-free 对应物更好的性能;
最后,该研究引入了用于知识蒸馏的 token 匹配新概念,它可以在不影响检测效率的情况下从大型模型到小型模型带来额外的性能提升。
![]()
RAM 模块该研究引入了 RAM 模块,它将与 [PATCH] 和 [DET] token 相关的单个全局注意力分解为三个不同的注意力,即 [PATCH]×[PATCH]、[DET]× [DET] 和 [DET] × [PATCH] 注意力。如图 3 所示,通过共享 [DET] 和 [PATCH] token 的投影层,全部复用 Swin Transformer 的所有参数,并执行三种不同的注意力操作:
![]()
推荐:
完全基于 Transformer 的目标检测器。
论文 5:Ten Lessons From Three Generations Shaped Google’s TPUv4i
摘要:
作为图灵奖得主、计算机架构巨擘,David Patterson 在 2016 年从伯克利退休后,以杰出工程师的身份加入了谷歌大脑团队,为两代 TPU 的研发做出了卓越贡献。
几个月前谷歌强势推出了 TPUv4,并撰写论文讲述了研发团队的设计思路和从前几代 TPU 中吸取的经验。
当前,深度神经网络在商用领域的特定体系架构 (DSA) 已初步建立。该论文对四代 DSA 的进化进行了回顾和扩展,展示了这一类架构的演变。生产经验推动了新设计的诞生,不再受限于 CPU 的缓慢发展和摩尔定律的衰退。
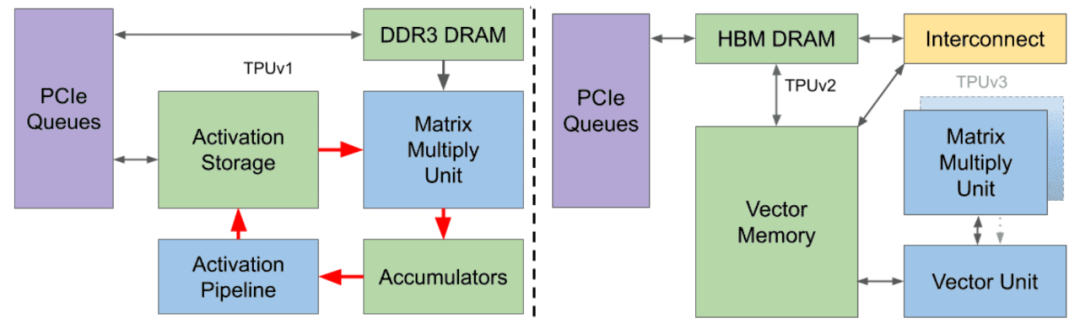
![]()
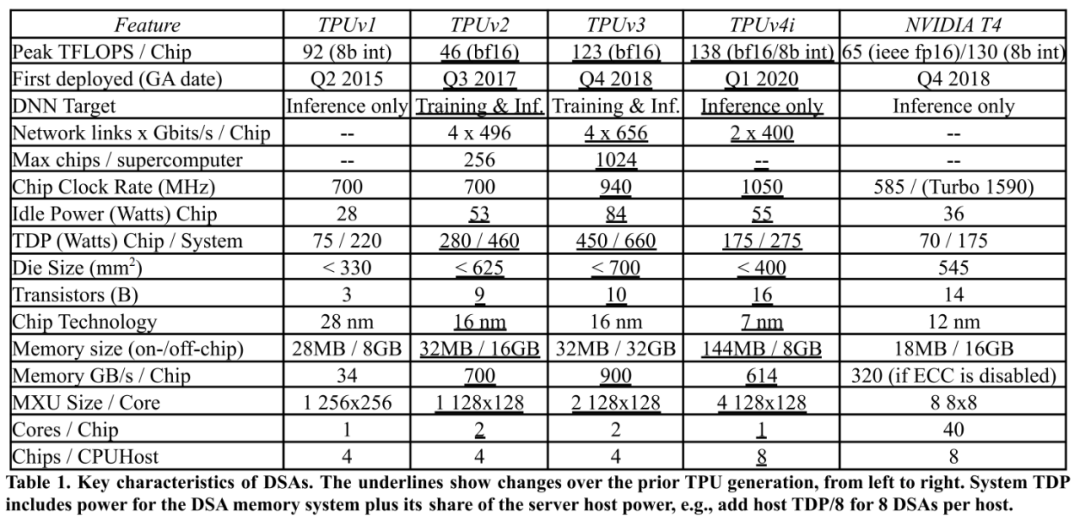
图 1:从 2015 年开始部署在谷歌数据中心的 3 个 TPU 的框图。
下表 1 展示了上图 3 个 TPU 的关键特性:
![]()
TPUv1 是谷歌第一代 DNN DSA(图 1 左),能够处理推理任务。近年来,模型训练的规模逐渐增大,所以一种新的改进是添加一个片到片的定制互连结构 ICI,使得搭载 TPUv2 的超级计算机芯片数量可多达 256 个。
与 TPUv1 不同,TPUv2 每个芯片有两个 TensorCore。芯片上的全局线不会随着特征尺寸的缩小而缩小 ,因此相对延迟会增加。每个芯片有两个较小的核,以避免单个大型全芯片核的过度延迟。谷歌并没有继续增加核的数量,因为他们相信两个强大的核比许多不够强的核更易于高效地编译程序。
TPUv3 则在 TPUv2 的基础上微调了设计,采用相同的技术,拥有 2 倍的 MXU 和 HBM 容量,并将时钟频率、内存带宽和 ICI 带宽提高至 1.3 倍。一台 TPUv3 超级计算机可以扩展到 1024 个芯片。TPUv3 在使用 16 位浮点 (bfloat16 vs IEEE fp16) 时与 Volta GPU 相当。然而,Volta 需要使用 IEEE fp32 来训练谷歌的生产工作负载,使得 TPUv3 快了 5 倍以上。一些扩展到 1024 个芯片的应用程序可以获得 97%-99% 的完美线性加速。
TPUv4i 中 i 代表的是「推理」,谷歌在论文中介绍了其 5 年多以来在建设和部署中积累的经验。
论文 6:OMNIVORE: A Single Model for Many Visual Modalities
摘要:
Meta AI 推出了 Omnivore 模型,可以对不同视觉模态的数据进行分类,包括图像、视频和单视角 3D 数据。OMNIVORE 易于训练,使用现成的标准数据集,并且与相同大小的特定模态模型的性能相当或更好。实验结果显示,Omnivore 在图像分类数据集 ImageNet 上能达到 86.0% 的准确率,在用于动作识别的 Kinetics 数据集上能达 84.1%,在用于单视角 3D 场景分类的 SUN RGB-D 也获得了 67.1%。
经过微调后,Omnivore 在各种视觉任务上的表现优于先前的工作,并且可以泛化各种模态。OMNIVORE 的共享视觉表示自然能够实现跨模态识别,而无需访问模态之间的对应关系。
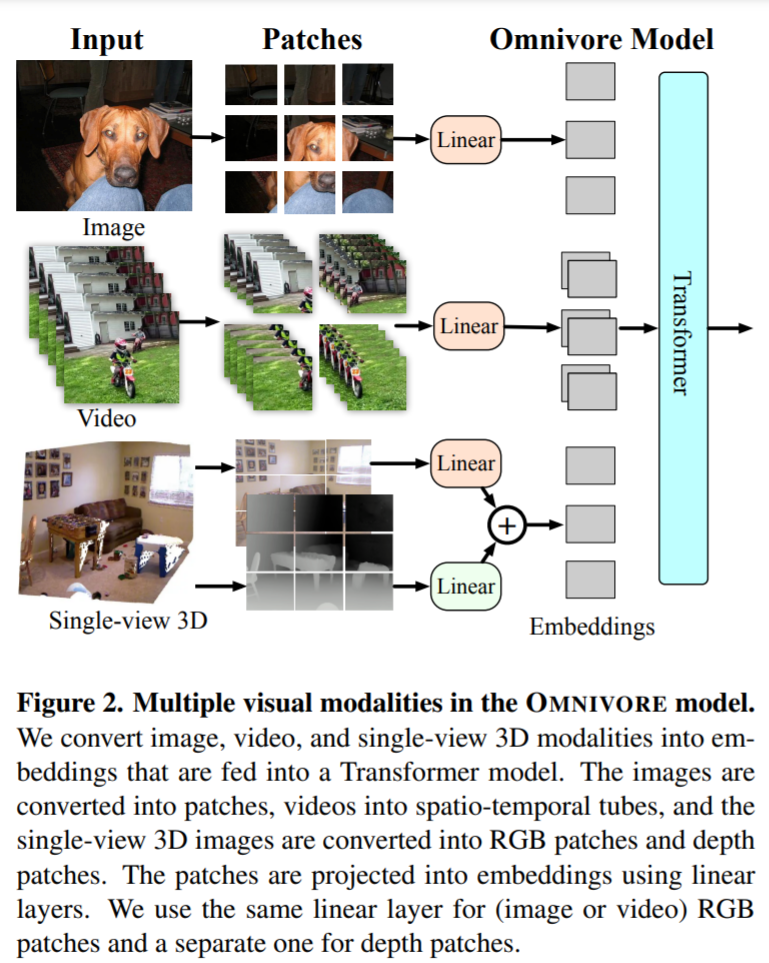
Omnivore 是基于 Transformer 体系结构,并针对不同模态的分类任务进行联合训练。模型架构如下:
![]()
Omnivore 将输入的图像、视频和单视角 3D 图像转换为嵌入,并输入到 Transformer 中。
推荐:
一个模型搞定图像、视频和 3D 数据三大分类任务。
论文 7:UniFormer: Unifying Convolution and Self-attention for Visual Recognition
摘要:
由于图像和视频中存在大量的局部冗余和复杂的全局依赖关系,因此学习图像和视频的区别表示是一项具有挑战性的任务。CNN 与 ViTs(Vision Transformers)是两种主流的架构,CNN 可以通过在小邻域内的卷积有效地减少局部冗余,但有限的接收域使其难以捕获全局依赖;而 ViT 凭借自注意力可以捕获长距离依赖,但盲相似性比对会导致过高的冗余。
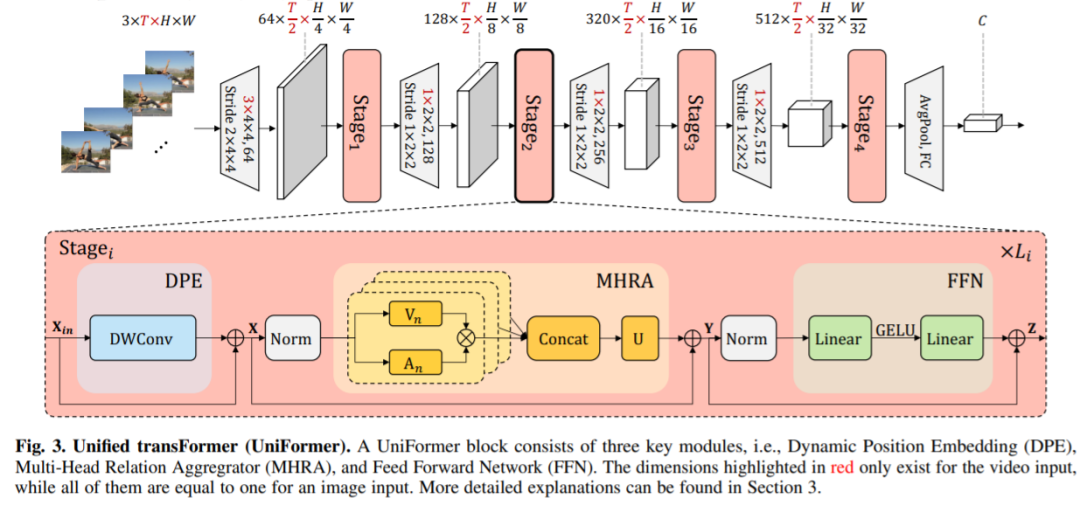
为解决上述问题,研究者提出一种新的 UniFormer(Unified transFormer),它能够将卷积与自注意力的优点通过 transformer 进行无缝集成。不同于典型的 Transformer 模块,UniFormer 模块的相关性聚合在浅层与深层分别配置了局部全局 token,允许处理冗余和依赖,以实现高效和有效的表示学习。
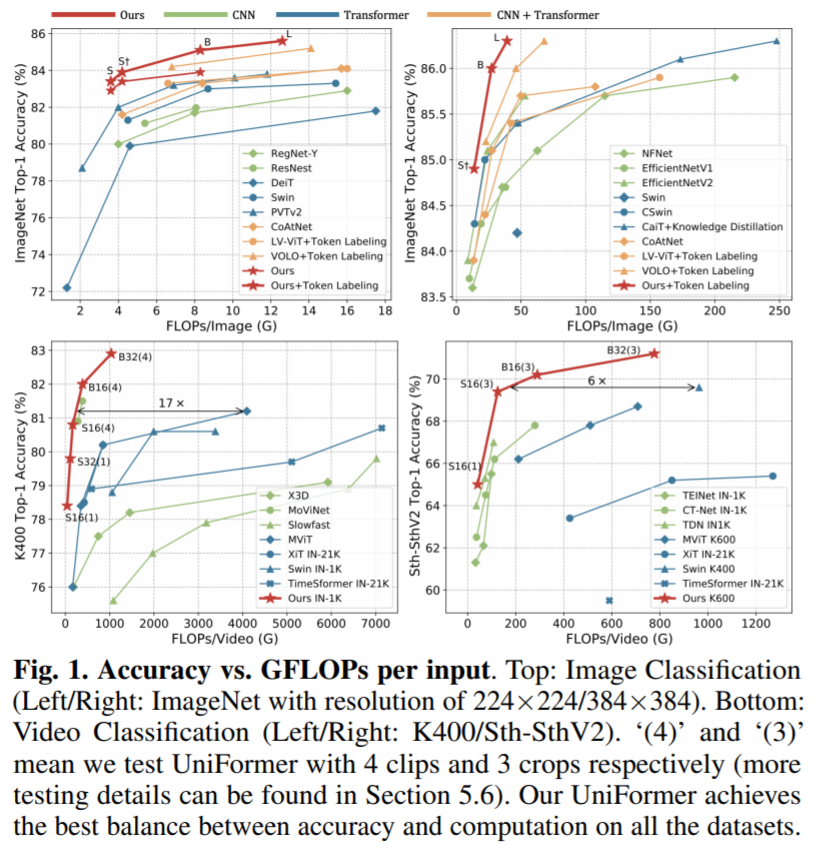
最后,研究者灵活地将 UniFormer 块堆叠成一个新的强大主干,并将其用于从图像到视频领域、从分类到密集预测的各种视觉任务。在没有任何额外训练数据的情况下,UniFormer 在 ImageNet-1K 分类上达到了 86.3 的 top-1 准确率。仅通过 ImageNet-1K 预训练,它可以简单地在广泛的下游任务中实现最先进的性能,例如,它在 Kinetics-400/600、60.9/71.2 上获得 82.9/84.8 的 top-1 准确度,在 Something-Something V1/V2 数据集上的 60.9%/71.2%,在 COCO 目标检测任务上的 53.8 box AP 和 46.4 mask AP,在 ADE20K 语义分割任务上的 50.8 mIoU,在 COCO 姿态估计任务上的 77.4 AP。
![]()
![]()
推荐:
CNN 和 Transformer 组合成 UniFormer。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. GreaseLM: Graph REASoning Enhanced Language Models for Question Answering. (from Christopher D. Manning, Jure Leskovec)
2. SciBERTSUM: Extractive Summarization for Scientific Documents. (from C Lee Giles)
3. Black-box Prompt Learning for Pre-trained Language Models. (from Tong Zhang)
4. Whose Language Counts as High Quality? Measuring Language Ideologies in Text Data Selection. (from Noah A. Smith)
5. A Causal Lens for Controllable Text Generation. (from Li Erran Li)
6. Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation. (from Michael Brudno)
7. Text and Code Embeddings by Contrastive Pre-Training. (from Alec Radford)
8. Description-Driven Task-Oriented Dialog Modeling. (from Yonghui Wu)
9. Chinese Word Segmentation with Heterogeneous Graph Neural Network. (from Jun Wang)
10. Human Interpretation of Saliency-based Explanation Over Text. (from Yoav Goldberg)
1. PONI: Potential Functions for ObjectGoal Navigation with Interaction-free Learning. (from Jitendra Malik, Kristen Grauman)
2. Rayleigh EigenDirections (REDs): GAN latent space traversals for multidimensional features. (from Aleix Martinez, Pietro Perona)
3. Natural Language Descriptions of Deep Visual Features. (from Antonio Torralba)
4. Deep Image Deblurring: A Survey. (from Ming-Hsuan Yang)
5. Learning To Recognize Procedural Activities with Distant Supervision. (from Marcus Rohrbach, Shih-Fu Chang)
6. Deeply Explain CNN via Hierarchical Decomposition. (from Ming-Ming Cheng, Liang Wang, Philip Torr)
7. Ranking Info Noise Contrastive Estimation: Boosting Contrastive Learning via Ranked Positives. (from Thomas Brox)
8. Contrastive and Selective Hidden Embeddings for Medical Image Segmentation. (from Dimitris Metaxas)
9. Investigating the Potential of Auxiliary-Classifier GANs for Image Classification in Low Data Regimes. (from Aggelos K. Katsaggelos)
10. What Can Machine Vision Do for Lymphatic Histopathology Image Analysis: A Comprehensive Review. (from Jian Wu)
1. Online Active Learning with Dynamic Marginal Gain Thresholding. (from Michael I. Jordan)
2. Enhancing Hyperbolic Graph Embeddings via Contrastive Learning. (from Jiahong Liu)
3. Distributed Bandits with Heterogeneous Agents. (from Lin Yang, Don Towsley)
4. Achieving Personalized Federated Learning with Sparse Local Models. (from Dacheng Tao)
5. Online Attentive Kernel-Based Temporal Difference Learning. (from Yang Gao)
6. Deconfounding to Explanation Evaluation in Graph Neural Networks. (from Tat-Seng Chua)
7. Approximation bounds for norm constrained neural networks with applications to regression and GANs. (from Yang Wang)
8. A Systematic Study of Bias Amplification. (from Laurens van der Maaten)
9. Environment Generation for Zero-Shot Compositional Reinforcement Learning. (from Honglak Lee)
10. Variational Model Inversion Attacks. (from Richard Zemel)
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com