FAIR最新视觉论文集锦:FPN,RetinaNet,Mask和Mask-X RCNN(含代码实现)
这篇文章会从 FAIR 在基本模块上的创新开始,谈到 CNN,再到 one-shot 物体检测。之后会讲实例分割的创新。最后聊聊依靠弱半监督模型来扩展实例分割。
AI 科技评论按:本文为雷锋字幕组编译的技术博客,原标题 Recent FAIR CV Papers - FPN, RetinaNet, Mask and Mask-X RCNN,作者为 Krish。
翻译 | 李石羽 林立宏 整理 | 凡江
特征金字塔网络 (FPN) [1] 发表在 2017 年的 CVPR 上。如果你关注最近两年计算机视觉的发展,就知道冥冥之中存在着那样一些优秀的算法,而你要做的,就是等着大神们把它写出来、训练好、再公开源码。认真地说,FPN这篇论文写的非常不错,很合我胃口。能构建出一个简单易行的基本模型,在各种不同的任务都好使,并不是一件容易的事。深究细节之前先强调一点,FPN 是基于一个特征提取网络的,它可以是常见的 ResNet 或者 DenseNet 之类的网络。在你最常用的深度学习框架下取一个预训练模型,就可以用来实现 FPN 了。
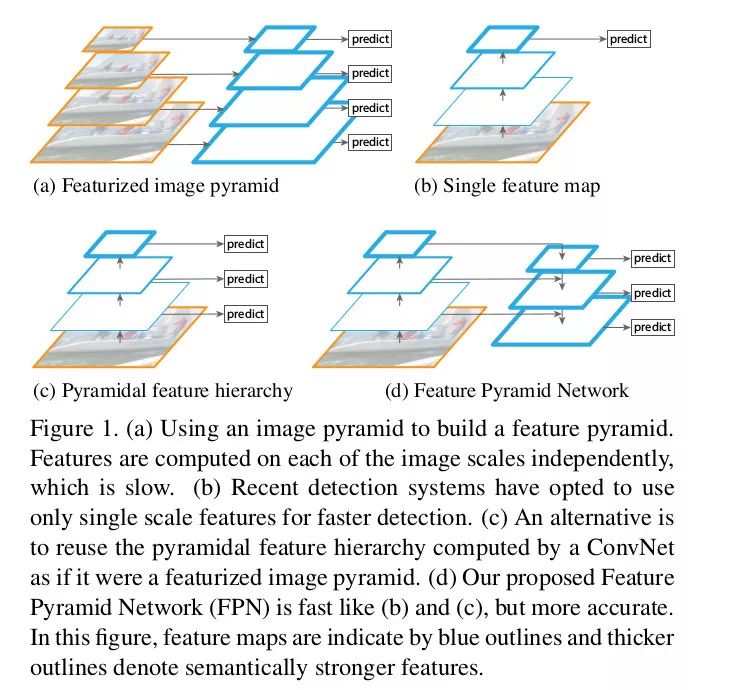
图像里的目标尺寸大小各种各样,数据集里的物体不可能涵盖所有的尺度,所以人们利用图像金字塔(不同分辨率的下采样)来帮助 CNN 学习。但是这样的速度太慢了,所以人们只使用单一尺度来预测,也有人会取中间结果来预测。后者和前者很像,只不过是在特征图上的。比较容易想到的方法是,在几层残差模块后面加一层转置卷积,提高分辨率,得到分割的结果,或者通过 1x1 的卷积或 GlobalPool 得到分类的结果。这种架构在有辅助信息和辅助损失函数时被大量使用。
FPN 的作者用一种很巧妙的办法提高了上述的方法。除了侧向的连接,还加入了自上而下的连接。这样做效果非常好。作者把从上到下的结果和侧向得到的结果通过相加的办法融合到一起。这里的重点在于,低层次的特征图语义不够丰富,不能直接用于分类,而深层的特征更值得信赖。将侧向连接与自上而下的连接组合起来,就可以得到不同分辨率的的特征图,而它们都包含了原来最深层特征图的语义信息。
模型细节
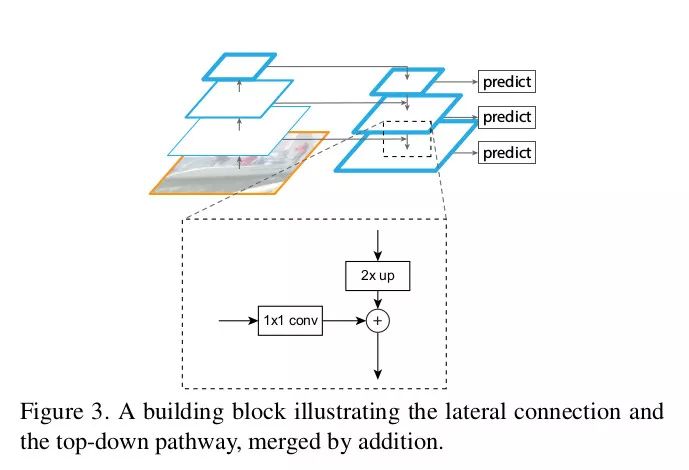
金字塔 - 同样尺寸的特征图属于同一级。每级最后一层输出是金字塔的特征图,比如 ResNet 第 2,3,4,5 个模块的最后一层。你可以根据需要进行调整。
侧向连接:通过 1x1 卷积并与经过上采样的从上到下连接的结果相加求和。自上而下的部分生成粗粒度特征,自下而上的部分通过侧向连接加入细粒度特征。原文的图示表达的非常明了。
原文中只是用一个简单的例子展示了 FPN 的设计之简单以及效果之可观,这不代表它不能用于更复杂的研究中。
如我刚才所说,这是个万金油网络,可以用在目标检测、实例分割、姿态识别、面部识别等各种各样的应用里。文章仅仅公开几个月就有了近 100 次引用。文章题目是《用于目标识别的金字塔特征网络》,所以作者把 FPN 带入到 Faster-RCNN 中作为区域推荐网络 (RPN)。很多关键的细节在原文中都有详细的解释,为了节约时间我这里列几条重点。
实验要点
用 FPN 作为 RPN - 用 FPN 的多分辨率特征取代单一分辨率的特征图,每一级上用同样的尺寸的 anchor(因为特征图尺度不同从而达到了多尺度 anchor 的效果)。金字塔的每一级都共享相似的语义水平。
FasterRCNN - 用类似于处理图像金字塔的方法来处理 FPN。ROI 通过下面这个公式来分派给特定的一级。
w 和 h 分别代表宽度和高度。k 是ROI被分配到的层级,
表示输入原图大小(224x224)的那一层。
简单粗暴地在 COCO 数据集上获得了最优效果。
对每一个模块都进行了单变量实验,从而证明了开头的说法。
基于 DeepMask and SharpMask 架构演示了 FPN 可以用于图像分割建议生成。
对实现细节感兴趣的同学一定要去读一读原文。
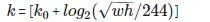
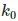
附注:FPN 是基于一个主干模型的,比如 ResNet。常见的命名方法是:主干网络-层数-FPN,例如:ResNet-101-FPN
代码实现
Caffe2(官方实现) - https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
Caffe - https://github.com/unsky/FPN
PyTorch - https://github.com/kuangliu/pytorch-fpn(just the network)
MXNet - https://github.com/unsky/FPN-mxnet
Tensorflow - https://github.com/yangxue0827/FPN_Tensorflow
同样的团队,同样的一作,这篇文章发表在了 2017 年的 ICCV 上[2]。这篇文章有两个重点,一般性的损失函数 Focal Loss (FL) 以及单阶段的目标检测模型 RetinaNet。这两者的结合在 COCO 目标检测任务中大显身手,超过了刚才提到的 FPN。
Focal Loss
这是一个极其精巧简洁的设计。如果你熟悉加权损失函数的话,这基本上是同样的原理,只不过更集中在难以分类的样本上。它的公式如下,很好理解
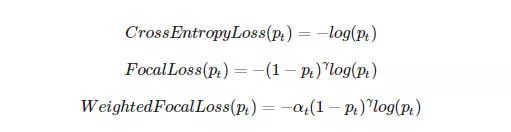
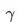
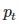
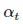
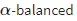
RetinaNet
一款单阶段检测器竟是出于 FAIR 之手,实在惊人。YOLOv2 和 SSD 在单阶段检测领域称霸至今。但如作者所说,它们都没有达到目前(包括两阶段检测器)最佳的效果。 同为单阶段检测器的 RetinaNet 却做到了,兼顾速度与效果。作者表示能带到如此效果是因为新的损失函数而不是网络的改进(网络用的是 FPN)。 单阶段检测器会面临大量的样本不平衡状况,背景样本太多,物体样本太少。加权损失只能做到平衡,而 FL 主要针对难例,这两者也可以相结合。
需要注意的地方
两阶段检测器不需要担心不平衡的问题,因为第一阶段移除了几乎所有的不平衡。
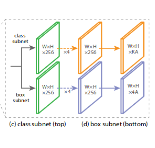
网络包含两部分 - 主干网络(用于特征提取,比如 FPN)和两个子网络分别用于分类与边框回归。
选择不同组件时性能差异不大。
Anchor 或 AnchorBoxes 与 RPN [5] 中的 Anchor 相同,都以滑窗为中心并有一个长宽比。尺度与长宽比和 [1] 一样,尺度从
到
,长宽比分别为 1:2, 1:1, 2:1。
FPN 的每一级,都通过子网络给出相应的有 anchor 的输出。
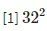
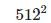
代码实现
Caffe2(官方实现) - https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
PyTorch - https://github.com/kuangliu/pytorch-retinanet
Keras - https://github.com/fizyr/keras-retinanet
MXNet - https://github.com/unsky/RetinaNet
Mask R-CNN [3] 也是来自同一个团队。在 2017 年的 ICCV 上发表的,用于图像实例分割。对于外行人来说,它是基本的对象检测,而不是画边界框, 任务是给出对象的精确分割图! 回想起来,人们会说这一个如此简单的想法,但是它是可行的,并且成为了 SOTA,为预训练的模型提供了一种快速实现,这是一项了不起的工作!
长话短说,如果你知道 Faster-RCNN,那你就会知道它非常简单,给分割添加另外一个头部(分支)。通常是3个分支,分别用于分类,边框回归和分割。
又一次,这种方法关注于使用简单和基本的神经网络设计来提高效率。没有任何花里胡哨的东西就让他们获得了 SOTA。(有一些免费技术(比如OHEM,多维度训练/测试等)能够适用于所有的方法用于提高准确性,花里胡哨的实现并不使用他们。因为他们是免费的,准确率肯定会提高。但是这不在本文的讨论范围之内)
我非常喜欢这篇论文,它非常的简单。但有一些论文在一些很简单的事情上给了过多的解释,并给出了明确的方式进行实现。比如说,使用多项 mask 和独立的 mask(softmax 和 sigmoid)。此外,它不需要假定大量先验知识和解释所有的事情(有时候可能也是一个骗局)。有人认真了论文的话就会很明显地发现,他们的新想法在现有成熟的环境上不能工作。下面的解释假定了你对 Fast RCNN 有基本的了解:
它和 FasterRCNN 是相似的,有两个阶段,第一阶段是RPN。
加入了平行分支用于预测分割mask——一个FCN。
损失是
的总和
用 ROIAlign 层替代了 ROIPool。这实际上是将 (x/spatial_scale) 分数四舍五入为一个整数像 ROIPool 中那样。 相反,它通过双线性插值来找出那些浮点值处的像素。
例如:假设 ROI 的高度和宽度分别为 54,167。 空间尺度基本上是图像尺寸/ FMap 尺寸(H / h),在这种情况下它也被称为步幅。通常为:224/14 = 16(H = 224,h = 14)。
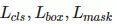
ROIPool: 54/16,167/16 = 3,10
ROIAlign:54/16,167/16 = 3.375,10.4375
现在我们可以使用双线性插值来上取样
根据 ROIAlign 输出形状(例如 7x7),类似的逻辑将相应的区域分成适当的区域。
如果感兴趣的话,可以查阅 Chainer 用 Python 实现的 ROIPooling,并尝试自己实现 ROIAlign
ROIAlign代码可以在不同的库中使用,请查看下面提供的代码仓库。
核心是 ResNet-FPN
PS - 我针对Mask-RCNN上也写了一篇单独的文章,很快就会在这里发布。
代码实现
Official Caffe2 - https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
Keras - https://github.com/matterport/Mask_RCNN/
PyTorch - https://github.com/soeaver/Pytorch_Mask_RCNN/
MXNet - https://github.com/TuSimple/mx-maskrcnn
正如标题所说的,这是关于分割的。更准确的说,是实例分割。计算机视觉中的分割标准数据集,对现实世界有用的非常少。 COCO 数据集[7]即使在 2018 年也是最流行和丰富的数据集,只有 80 个对象类。这甚至不是很有用。 相比之下,对象识别和检测数据集(如 OpenImages [8])具有近 6000 个分类和 545 个检测 。话虽如此,斯坦福大学还有另一个名为 Visual Genome 数据集的数据集,其中包含 3000 类对象!那么,为什么不使用这个呢? 每个分类下的对象数量太少,所以 DNN 没有办法在这样的数据集上很好的工作,所以人们不使用这个数据集尽管它很丰富,对现实世界也很有用。请注意,数据集没有任何分割的注释,只有 3000 个类别的对象检测(边框)标签可用。
谈到第四篇论文啦,这也是一篇非常酷的论文。正如人们能想到,在边框和分割注解领域上并没有太大的区别,只是后者比前者精确得多。所以,因为我们在 Visual Genome [9]数据集中有 3000 个类,为什么不利用它来给出分割输出。这就是他们所做的,这可以称为弱监督(或弱半监督)学习,你没有完全监督你试图完成的任务。它还可以与半监督相关联,因为它们使用 COCO + Visual Genome 数据集。分割标签以及边框标签。这篇论文是迄今为止最酷的。
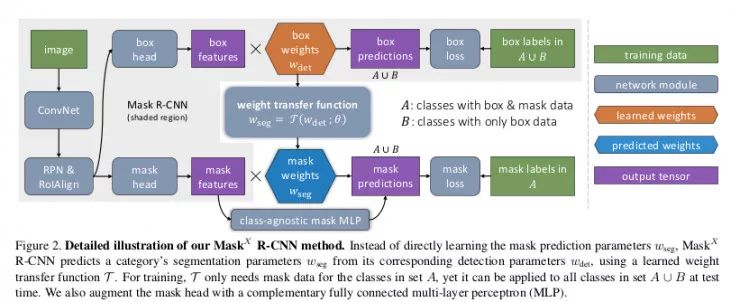
建立在 Mask-RCNN 之上
输入有 mask 和输入没有 mask 两种方式进行训练
在 mask 和 bbox mask 之间添加一个权重转换函数
在训练过程中,一个能够在整个数据集上 反向传播 bbox 的损失,但是另外一个只能在输入的真实数据(数据集 A)中带有 mask 的损失上反向传播
在推断过程中,当通过一个输入的时候,函数 τ 预测 mask 特征需要相乘的权重。模型的一种拓展使用了融合 MLP+FCN 模型的方式来改善准确度。这里只是使用了简单的 MLP 来代替。
如下图所示,两个数据集:A 是 COCO 数据集和 B 是 VG 数据集, 注意不同输入(bbox 和 mask)在任意输入计算得到不同的损失。
反向传播是计算这两种损失会导致
的权重出现差异,因为 COCO 和 VG 之间的共同类别有两个损失(bbox 和 mask),而其余类别只有一个(bbox)。这有一个解决办法:
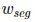
当反向传播 mask 时,计算预测 mask 权重
与权重传递函数参数θ的梯度,但不包括边框权重
。
其中 τ 函数预测 mask 的权重
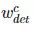
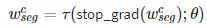
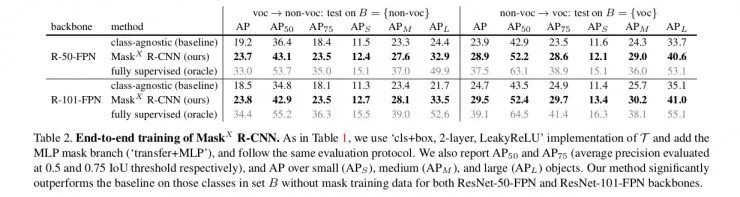
由于没有注释可用,因此他们无法在 VG 数据集上显示精确度。 所以他们把这个想法应用到可以证明结果的数据集上。PASCAL-VOC 有 20 个等级,在 COCO 中都很常见 。因此,他们使用 VOC 分类标签进行培训,并且只使用来自 COCO 的 bbox 标签对这 20 个类进行训练。 针对在 COCO 数据集的 20 个类的实例分割的任务的结果如下. 反之亦然,因为这两个数据集中都有真实值(Ground truth),这个结果列在下面的表格中。
PS - 如果它变得有用的话,我打算查阅论文来写一篇关于使用权重预测方法,去做有意思的事。
代码实现
PyTorch
致谢
感谢 Jakob Suchan 最初的努力让我们更熟悉 Mask RCNN 和 Learning to Segment Everything 论文!
参考文献
[1] Lin, Tsung-Yi, Piotr Dollár, Ross B. Girshick, Kaiming He, Bharath Hariharan and Serge J. Belongie. “Feature Pyramid Networks for Object Detection.” *2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)* (2017): 936-944.
[2] Lin, Tsung-Yi, Priya Goyal, Ross B. Girshick, Kaiming He and Piotr Dollár. “Focal Loss for Dense Object Detection.” *2017 IEEE International Conference on Computer Vision (ICCV)* (2017): 2999-3007.
[3] He, Kaiming, Georgia Gkioxari, Piotr Dollár and Ross B. Girshick. “Mask R-CNN.” *2017 IEEE International Conference on Computer Vision (ICCV)* (2017): 2980-2988.
[4] Hu, Ronghang, Piotr Dollár, Kaiming He, Trevor Darrell and Ross B. Girshick. “Learning to Segment Every Thing.” *CoRR*abs/1711.10370 (2017): n. pag.
[5] Ren, Shaoqing, Kaiming He, Ross B. Girshick and Jian Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.” *IEEE Transactions on Pattern Analysis and Machine Intelligence* 39 (2015): 1137-1149.
[6] Chollet, François. “Xception: Deep Learning with Depthwise Separable Convolutions.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017): 1800-1807.
[7] Lin, Tsung-Yi, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár and C. Lawrence Zitnick. “Microsoft COCO: Common Objects in Context.” ECCV (2014).
[8] Krasin, Ivan and Duerig, Tom and Alldrin, Neil and Ferrari, Vittorio et al. OpenImages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github.com/openimages
[9] Krishna, Ranjay, Congcong Li, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, David A. Shamma, Michael S. Bernstein and Li Fei-Fei. “Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations.” International Journal of Computer Vision 123 (2016): 32-73.
博客原址:
https://skrish13.github.io/articles/2018-03/fair-cv-saga
更多文章,关注 AI 科技评论。添加雷锋字幕组微信号(leiphonefansub)为好友,备注「我要加入」,To be an AI Volunteer !

对了,我们招人了,了解一下?

4 月 AI 求职季
8 大明星企业
10 场分享盛宴
20 小时独门秘籍
4.10-4.19,我们准时相约!

┏(^0^)┛欢迎分享,明天见!