TensorFlow Lite发布重大更新!支持移动GPU、推断速度提升4-6倍
乾明 发自 凹非寺
量子位 出品 | 公众号 QbitAI
TensorFlow用于移动设备的框架TensorFlow Lite发布重大更新,支持开发者使用手机等移动设备的GPU来提高模型推断速度。
在进行人脸轮廓检测的推断速度上,与之前使用CPU相比,使用新的GPU后端有不小的提升。在Pixel 3和三星S9上,提升程度大概为4倍,在iPhone 7上有大约有6倍。

为什么要支持GPU?
众所周知,使用计算密集的机器学习模型进行推断需要大量的资源。
但是移动设备的处理能力和功率都有限。虽然TensorFlow Lite提供了不少的加速途径,比如将机器学习模型转换成定点模型,但总是会在模型的性能或精度上做出让步。
而将GPU作为加速原始浮点模型的一种选择,不会增加量化的额外复杂性和潜在的精度损失。
在谷歌内部,几个月来一直在产品中使用GPU后端做测试。结果证明,的确可以加快复杂网络的推断速度。
在Pixel 3的人像模式(Portrait mode)中,与使用CPU相比,使用GPU的Tensorflow Lite,用于抠图/背景虚化的前景-背景分隔模型加速了4倍以上。新深度估计(depth estimation)模型加速了10倍以上。
在能够为视频增加文字、滤镜等特效的YouTube Stories和谷歌的相机AR功能Playground Stickers中,实时视频分割模型在各种手机上的速度提高了5-10倍。

对于不同的深度神经网络模型,使用新GPU后端,通常比浮点CPU快2-7倍。对4个公开模型和2个谷歌内部模型进行基准测试的效果如下:
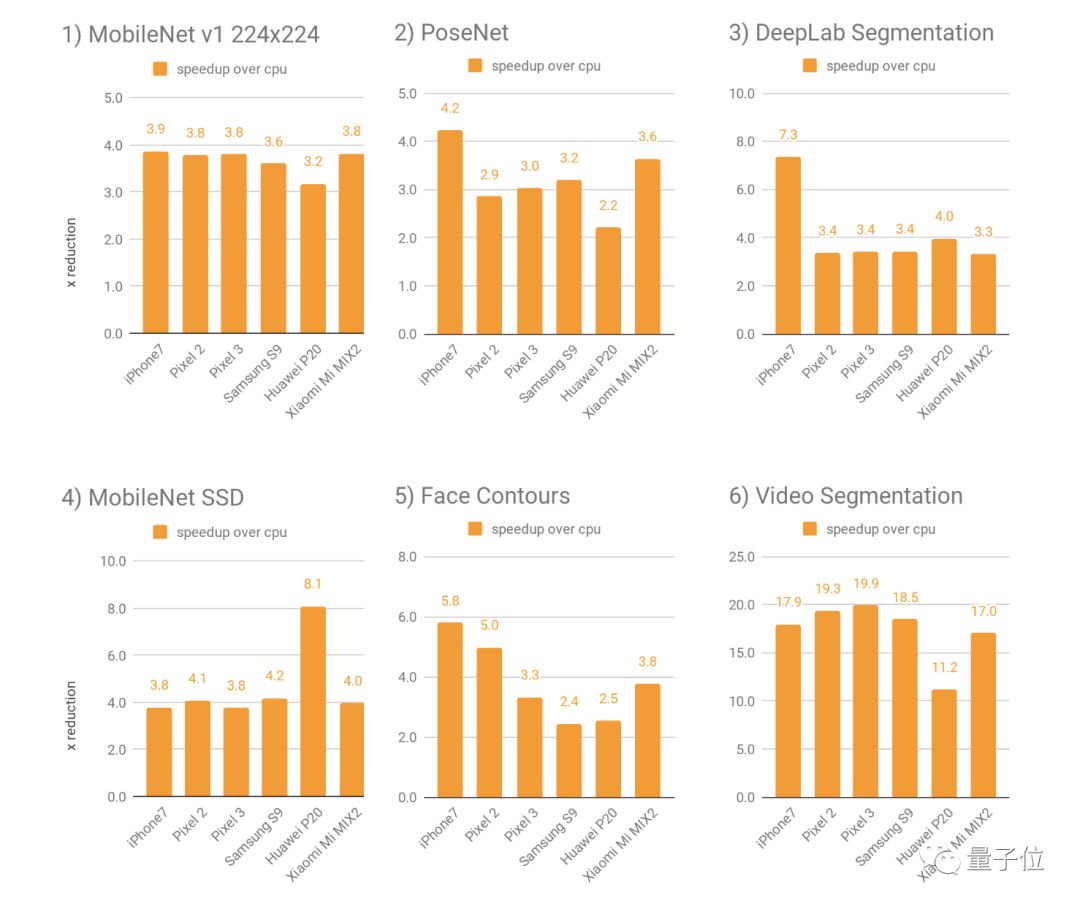
使用GPU加速,对于更复杂的神经网络模型最为重要,比如密集的预测/分割或分类任务。
在相对较小的模型上,加速的效果就没有那么明显了,使用CPU反而有利于避免内存传输中固有的延迟成本。
如何使用?
安卓设备(用Java)中,谷歌已经发布了完整的Android Archive (AAR) ,其中包括带有GPU后端的TensorFlow Lite。
你可以编辑Gradle文件,用AAR替代当前的版本,并将下面的代码片段,添加到Java初始化代码中。
// Initialize interpreter with GPU delegate.
GpuDelegate delegate = new GpuDelegate();
Interpreter.Options options = (new Interpreter.Options()).addDelegate(delegate);
Interpreter interpreter = new Interpreter(model, options);
// Run inference.
while (true) {
writeToInputTensor(inputTensor);
interpreter.run(inputTensor, outputTensor);
readFromOutputTensor(outputTensor);
}
// Clean up.
delegate.close();
在iOS设备(用C++)中,要先下载二进制版本的TensorFlow Lite。
然后更改代码,在创建模型后调用ModifyGraphWithDelegate ( )。
// Initialize interpreter with GPU delegate.
std::unique_ptr<Interpreter> interpreter;
InterpreterBuilder(model, op_resolver)(&interpreter);
auto* delegate = NewGpuDelegate(nullptr); // default config
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
// Run inference.
while (true) {
WriteToInputTensor(interpreter->typed_input_tensor<float>(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0));
}
// Clean up.
interpreter = nullptr;
DeleteGpuDelegate(delegate);
(更多的使用教程,可以参见TensorFlow的官方教程,传送门在文末)
还在发展中
当前发布的,只是TensorFlow Lite的开发者预览版。
新的GPU后端,在安卓设备上利用的是OpenGL ES 3.1 Compute Shaders,在iOS上利用的是Metal Compute Shaders。
能够支持的GPU操作并不多。有:
ADD v1、AVERAGE_POOL_2D v1、CONCATENATION v1、CONV_2D v1、DEPTHWISE_CONV_2D v1-2、FULLY_CONNECTED v1、LOGISTIC v1
MAX_POOL_2D v1、MUL v1、PAD v1、PRELU v1、RELU v1、RELU6 v1、RESHAPE v1、RESIZE_BILINEAR v1、SOFTMAX v1、STRIDED_SLICE v1、SUB v1、TRANSPOSE_CONV v1
TensorFlow官方表示,未来将会扩大操作范围、进一步优化性能、发展并最终确定API。
完整的开源版本,将会在2019年晚些时候发布。
传送门
使用教程:
https://www.tensorflow.org/lite/performance/gpu
项目完整文档:
https://www.tensorflow.org/lite/performance/gpu_advanced
博客地址:
https://medium.com/tensorflow/tensorflow-lite-now-faster-with-mobile-gpus-developer-preview-e15797e6dee7
— 完 —
请投“量子位”一票

加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !




