机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文包括哈佛大学首届计算机科学杰出博士论文,以及DeepMind提出的端到端对抗语音生成。
目录:
XGNN: Towards Model-Level Explanations of Graph Neural Networks
Preference-Based Learning for Exoskeleton Gait Optimization
Text Detection and Recognition in the Wild: A Review
Deep Latent Variable Models of Natural Language
Unsupervised Translation of Programming Languages
Learning Texture Transformer Network for Image Super-Resolution
End-to-End Adversarial Text-to-Speech
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:XGNN: Towards Model-Level Explanations of Graph Neural Networks
摘要:
图神经网络通过聚合和结合邻居信息来学习节点特征,在许多图的任务中取得了良好的性能。然而,GNN 大多被视为黑盒,缺乏人类可理解的解释。因此,如果不能解释 GNN 模型,就不能完全信任它们并在某些应用程序域中使用它们。
在这项研究中,
来自德克萨斯 A&M 大学(TAMU)和密歇根州立大学的研究者提出了一种新的方法,称为 XGNN,在模型级别上解释 GNN
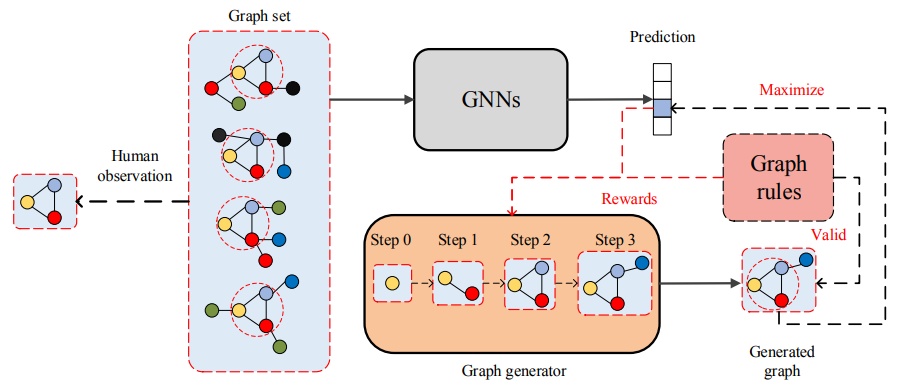
。特别地,他们提出通过训练图生成器来解释 GNN,使生成的图模式最大化模型的某种预测。研究者将图形生成表示为一个强化学习任务,其中对于每一步,图形生成器预测如何向当前图形中添加一条边。此外,他们还添加了一些图规则,使生成的图有效。
![]()
XGNN 工作流程图。图神经网络表示我们要解释的一个训练过的图分类模型。
![]()
![]()
本研究使用的两个数据集:Is_Acyclic 和 MUTAG。需要注意,边和节点数量均为平均值。
推荐:
在合成和真实数据集上的实验结果表明,研究者提出的方法有助于理解和验证训练过的 GNN。
论文 2:Preference-Based Learning for Exoskeleton Gait Optimization
摘要:
这项研究展示了如何利用「个人偏好」,来定制化提升人类使用下肢外骨骼的舒适感。以往,机械外骨骼一直被美国军队视为提升士兵作战能力的工具,但
加州理工和清华大学的这项研究在未来或许可为数千万残障人士带来帮助
。该研究提出了一种叫做 COSPAR 的算法,它可以将合作学习应用于下肢外骨骼操作时对人类偏好的适应,并在模拟和真人实验中进行了测试。
研究者表示,未来计划将 COSPAR 用于优化规模更大的步态参数,但可能需要集成该算法与更多可用于高维特征空间学习的技术。这一方法还可以扩展到预计算步态库以外的数据,进而生成全新的步态或者控制器设计。
![]()
本研究致力于优化下肢外骨骼 Atalante 的步态,以最大程度地提升用户舒适度。
![]()
![]()
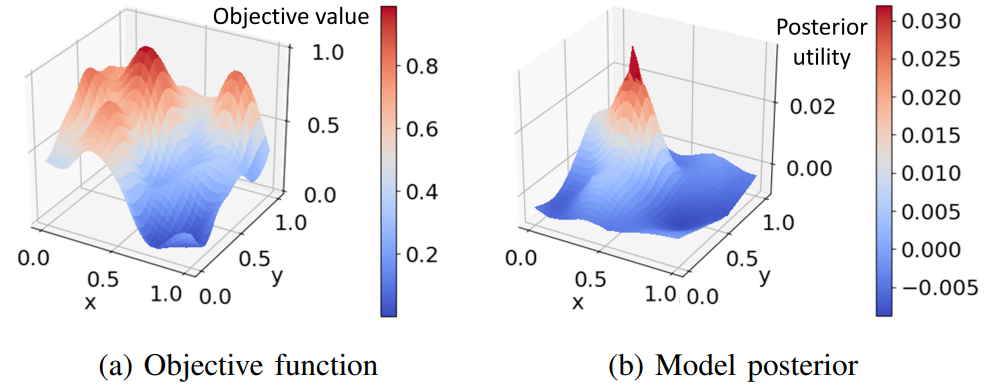
研究者在综合 2D 效用函数上测试 COSPAR 算法,每个效用函数都基于 30x30 网格上的高斯过程先验生成。这些实验评估了将 COSPAR 算法扩展至更高维度时的性能,以及合作反馈的优势。
推荐:
本研究荣获
ICRA 2020 最佳论文奖以及最佳人机交互论文奖(Best Paper Award on Human-Robot Interaction)
。
论文 3:Text Detection and Recognition in the Wild: A Review
摘要:
在这篇综述论文中,
来自加拿大滑铁卢大学和 ATS Automation Tooling Systems 公司的研究者首先回顾了场景文本检测和识别领域的新进展,并展示了利用统一的评估框架进行广泛实验的结果
。这个统一的评估框架对挑战性案例中选定方法的预训练模型进行评估,并在这些方法上应用相同的评估标准。
其次,研究者确定了在「野外场景」图像中检测或识别文本过程中遇到的一些挑战,即面内旋转(inplane-rotation)、多方向和多分辨率文本、透视失真(perspective distortion)、光照反射(illumination reflection)、繁体和特殊字符。
最后,研究者在文章结尾提出了该领域的潜在研究方向,以解决目前场景文本检测和识别方法依然存在的一些问题和挑战。
![]()
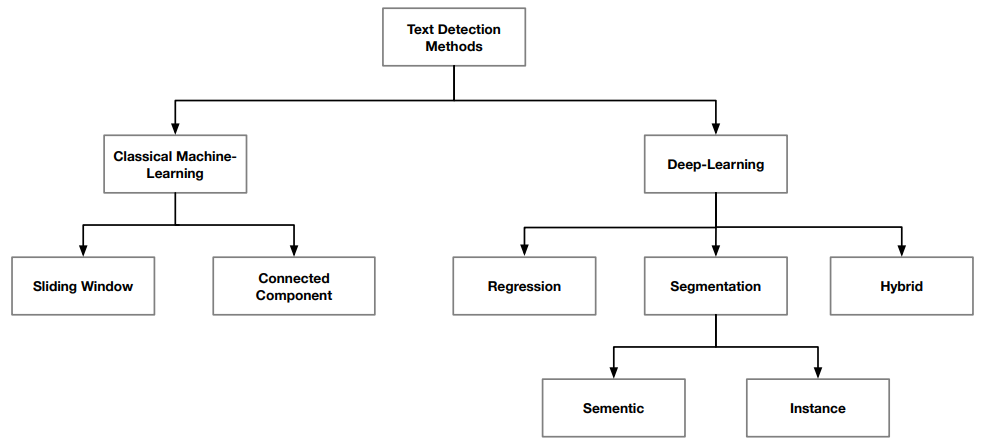
文本检测方法可以划分为经典机器学习和深度学习,其中经典机器学习方法包括滑动窗口(sliding window)和连通分量(connected component),深度学习方法包括回归(regression)、分割(segmentation)和合并(hybrid)。
![]()
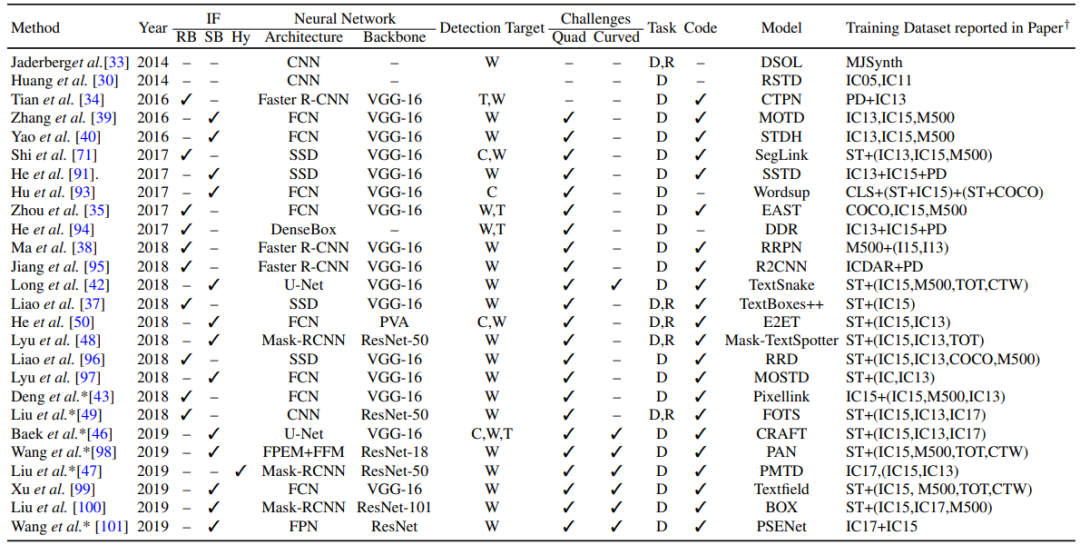
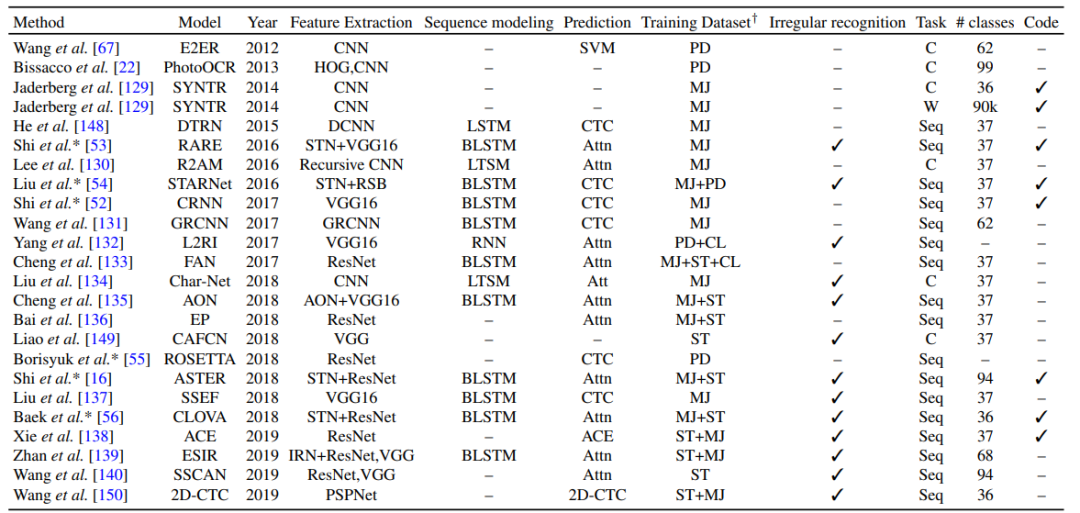
基于深度学习的文本检测方法,其中 W 表示单词、T 表示文本线条(text-line)、C 表示字符、D 表示检测、R 表示识别、RB 表示基于候选区域(region-proposal-based)、ST 表示合成文本(synthetic text)。
![]()
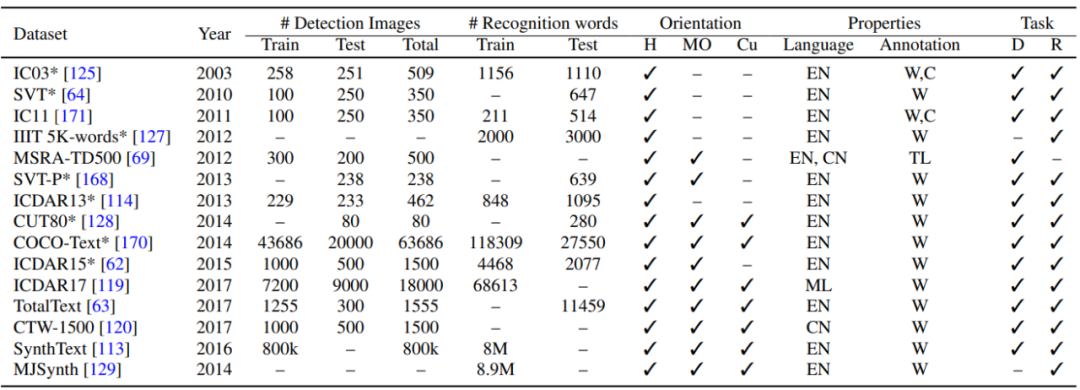
基于深度学习的 SOTA 文本识别方法,其中 TL 表示文本线条、C 表示字符、Seq 表示序列识别(sequence recognition)、PD 表示私人数据集(private dataset)、HAM 表示层级注意力机制(hierarchical attention mechanism)、ACE 表示聚合交叉熵(aggregation cross-entropy)。
![]()
推荐:
本篇综述论文对场景文本检测和识别方法进行了全面的汇总整理,读者可以更方便地了解该领域的新进展、面临的挑战以及未来的发展方向。
论文 4:Deep Latent Variable Models of Natural Language
摘要:
这篇博士论文的作者是哈佛大学计算机科学博士 Yoon Kim,他将于 2021 年入职 MIT 担任电子工程与计算机科学系助理教授
。综述了自然语言处理应用中的深度学习和潜变量建模。作者研究了深度潜变量模型,这类模型对具有神经网络的概率潜变量模型的组件进行参数化表示,因而在保持潜变量模型模块化的同时可以利用深度学习最新进展所赋能的丰富参数化。作者对不同类型的深度潜变量模型展开了广泛实验,以具体分析词对齐和分析树等一系列语言现象,并将这些语言现象应用到语言建模、机器翻译和无监督分析等核心的自然语言处理任务中。
作者还探究了深度潜变量模型用于语言应用时在学习和推理两方面遇到的一些关键挑战。学习此类模型的标准方法是基于平摊变分推理(amortized variational inference),其中训练全局推理网络来执行潜变量的似然后验推理。但是,均摊变分推理的简单实现常常无法满足相关应用需求,因而作者对标准方法进行扩展,以提升学习和推理效率。
整体来说,每章节都阐述了专用于特定语言领域建模的深度潜变量模型,并扩展均摊变分推理以解决相应潜变量模型使用过程中遇到的一些问题。作者预测这些方法将广泛应用于其他相关领域。
![]()
![]()
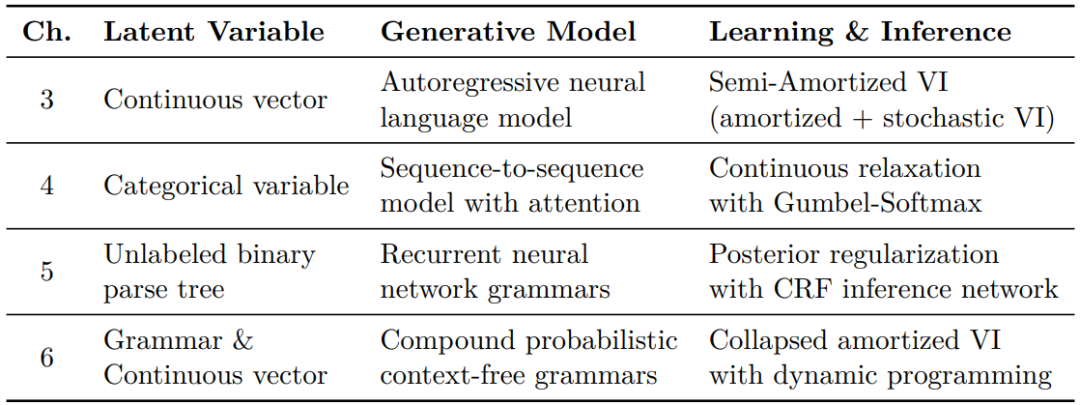
本论文中用到的各种潜变量、生成模型以及学习和推理方法。
![]()
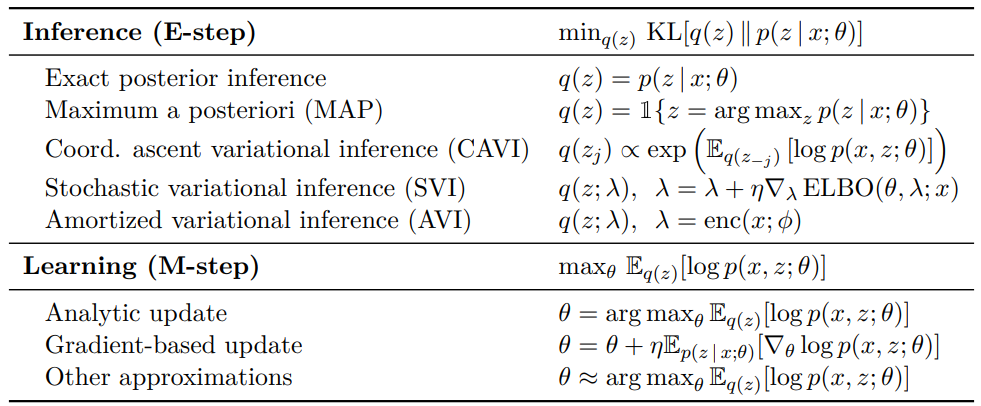
利用最大似然学习(maximum likelihood learning)训练潜变量模型的不同优化方法。
推荐:
这篇博士论文获得了
哈佛大学首届计算机科学杰出博士论文奖
。
论文 5:Unsupervised Translation of Programming Languages
摘要:
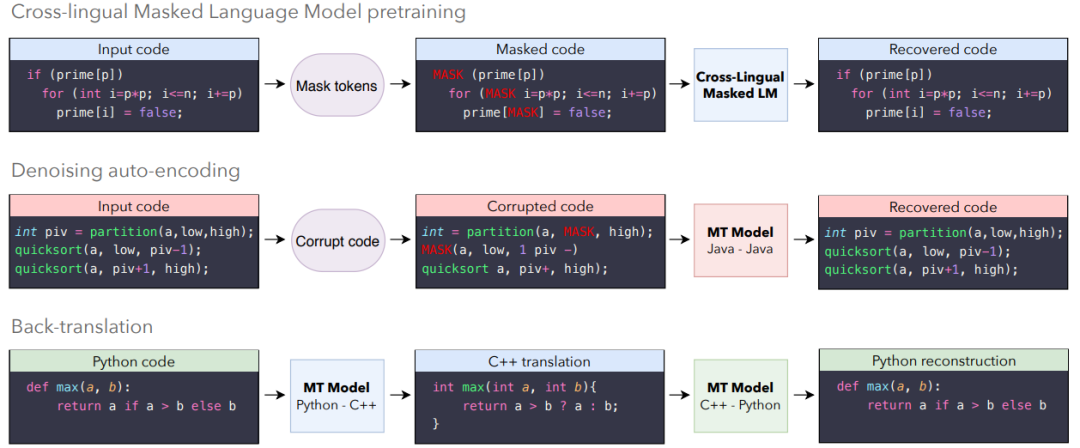
transcompiler 系统,又称源到源编译器,可以将高级编程语言(如 C++ 或 Python)写成的源代码转换成另一种语言。此类工具主要为了提升互操作性,将用过时或废弃语言(如 COBOL、Python 2)写成的代码库移植到现代语言。它们通常依赖于手动编写的重写规则,并应用于源代码抽象语法树。但是,transcompiler 存在一些缺陷,如转换结果通常缺乏可读性,无法遵循目标编程语言的规范,需要人类程序员进行手动修改才能准确运行。整个转换过程不仅耗时,还需要专家掌握源语言和目标语言的专业知识,因此这类代码转换项目的成本很高。
因此,在本文中,
Facebook 研究人员利用无监督机器翻译方法,训练出一种无监督神经 transcompiler——TransCoder
。TransCoder 基于 GitHub 开源项目中的源代码训练而成,能够以高准确率实现 C++、Java 和 Python 三种编程语言之间的函数转换。
![]()
![]()
TransCoder 将 Python 代码转换成了 C++ 代码。
![]()
在使用贪婪解码(greedy decoding)时,TransCoder 在测试集上的结果。
推荐:
利用 TransCoder,只需单语源代码,无需任何源语言或目标语言的专业知识。深度学习「三驾马车」之一 Yann LeCun 转推了该研究。
论文 6:Learning Texture Transformer Network for Image Super-Resolution
摘要:
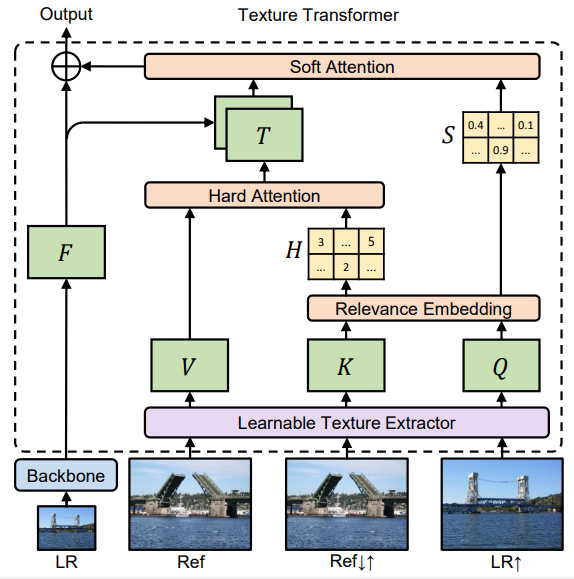
在这篇论文中,
来自上海交通大学和微软研究院(北京)的研究者对图像超分辨率(super-resolution, SR)展开研究,目的是从低分辨率(low-resolution, LR)图像中恢复真实纹理
。目前的方法是将超分辨率图像作为参考(reference, Ref),所以相关纹理可以迁移至低分辨率(LR)图像中。并且,这些 SR 方法往往不使用注意力机制将参考图像中的纹理信息迁移至高分辨率(HR)图像中。
因此,
研究者提出了一种新颖的图像超分辨率纹理 Transformer 网络(Texture Transformer Network for Image Super, TTSR)
,其中低分辨率(LR)和参考(Ref)图像分别表示为 Transformer 中的查询和关键字。TTSR 包含四个紧密相关且针对图像生成任务进行优化的模块,即 DNN 的可学习纹理提取器、相关性嵌入模块、用于纹理迁移的硬注意力模块以及用于纹理合成的软注意力模块。
这种设计鼓励低分辨率(LR)和参考(Ref)图像之间进行联合特征学习,其中深度特征对应关系可以通过注意力发现,从而可以实现纹理特征的准确迁移。本研究提出的纹理 Transformer 能够以跨尺度的方式实现进一步堆叠,进而实现不同级别的纹理恢复。
![]()
本研究中 TTSR 方法与当前 SOTA 方法 RefSR 的实际效果对比。
![]()
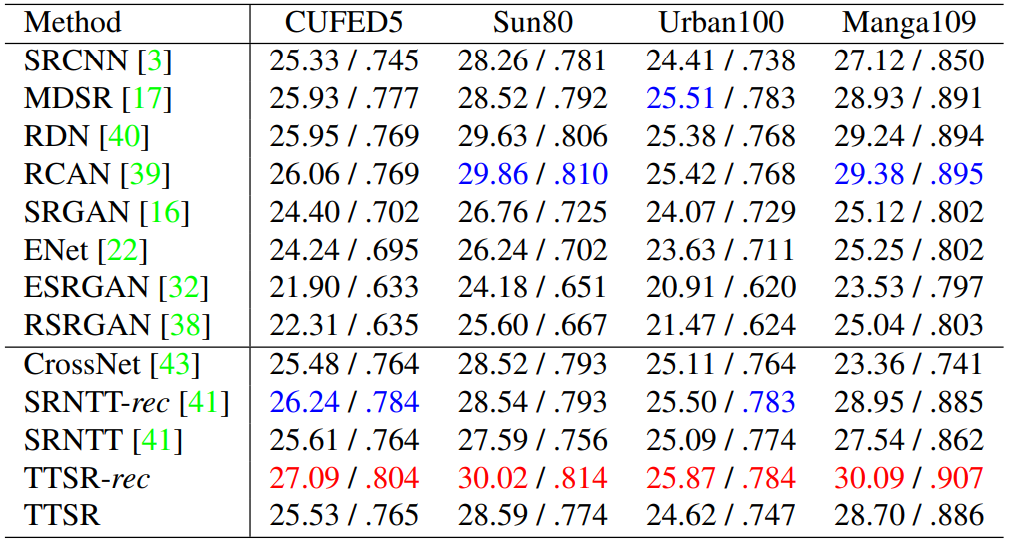
![]()
不同超分辨率(SR)方法在 GUFED5、Sun80、Urban100 和 Manga109 四个数据集上的 PSNR/SSIM 结果对比。
推荐:
大量的实验表明,TTSR 在定量和定性评估两方面较当前 SOTA 方法均有显著提升。
论文 7:End-to-End Adversarial Text-to-Speech
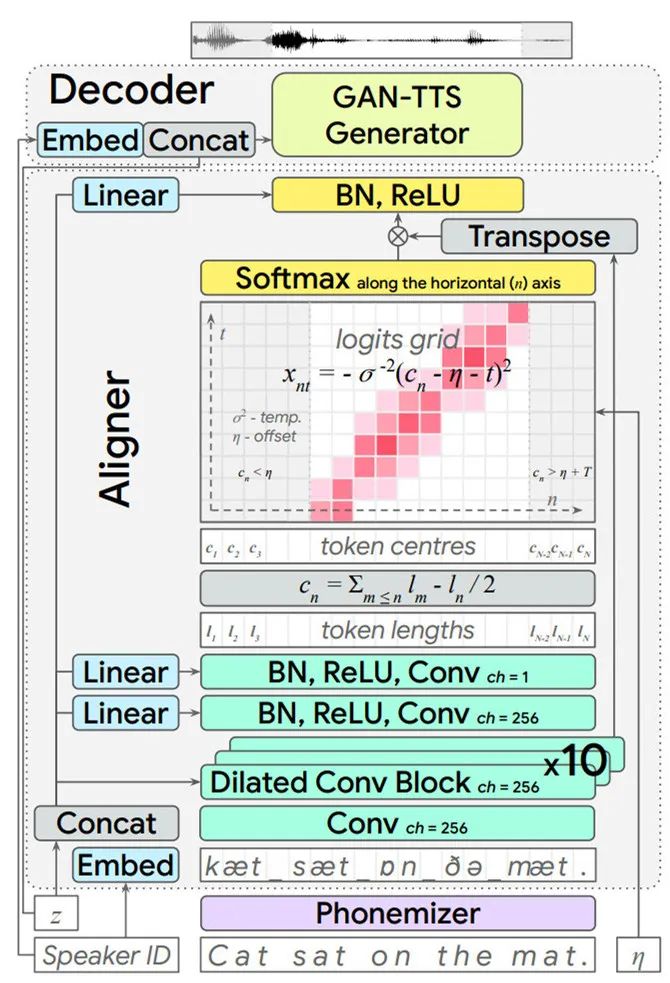
摘要:经典的文本转语音(以下称 TTS)系统包括多个独立训练或独立设计的阶段,如文本归一化、语言特征对齐、梅尔谱图合成和原始音频波形合成。尽管 TTS 已经能够实现逼真和高保真度的语音合成,并在现实中得到广泛应用,但这类模块化方法也存在许多缺点。比如每个阶段都需要监督,在某些情况下需要耗费高成本的「真值」标注来指导每个阶段的输出。此外,这类方法无法像机器学习领域很多预测或者合成任务那样,获得数据驱动「端到端」学习方法的全部潜在收益。
近日,
来自 DeepMind 的研究者试图简化 TTS 流程,对以端到端的方式基于文本 / 音素合成语音的任务发起了挑战。他们提出了一种端到端对抗式 TTS 模型(End-to-end Adversarial Text-to-Speech,EATS)
,该模型可在纯文本或者暂未对齐的原始音素输入序列上运行,并输出原始语音波形。通过维护从网络中学习到的中间特征表征,该模型消除了大多数 TTS SOTA 模型中存在的典型中间瓶颈。
![]()
![]()
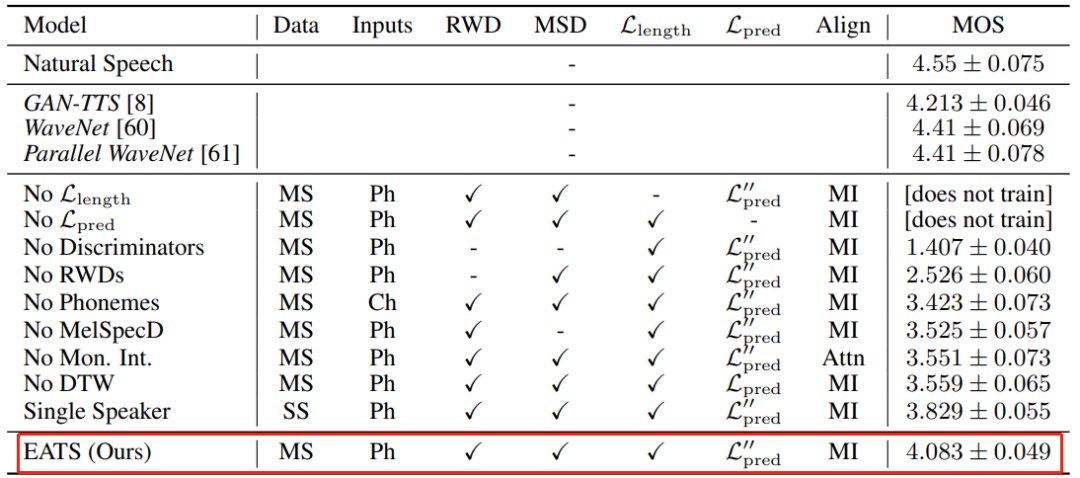
EATS 模型的定量结果,以及各种模型和学习信号组件的控制变量研究结果。
![]()
本研究训练数据集中具有最多数据的前四位说话者的平均意见得分(MOS)。
推荐:
EATS 模型可在纯文本或者暂未对齐的原始音素输入序列上运行,并输出原始语音波形。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Spoken dialect identification in Twitter using a multi-filter architecture. (from Mohammadreza Banaei, Rémi Lebret, Karl Aberer)
2. Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access. (from Seokhwan Kim, Mihail Eric, Karthik Gopalakrishnan, Behnam Hedayatnia, Yang Liu, Dilek Hakkani-Tur)
3. SOLO: A Corpus of Tweets for Examining the State of Being Alone. (from Svetlana Kiritchenko, Will E. Hipson, Robert J. Coplan, Saif M. Mohammad)
4. Performance in the Courtroom: Automated Processing and Visualization of Appeal Court Decisions in France. (from Paul Boniol, George Panagopoulos, Christos Xypolopoulos, Rajaa El Hamdani, David Restrepo Amariles, Michalis Vazirgiannis)
5. Multi-hop Reading Comprehension across Documents with Path-based Graph Convolutional Network. (from Zeyun Tang, Yongliang Shen, Xinyin Ma, Wei Xu, Jiale Yu, Weiming Lu)
6. CoCon: A Self-Supervised Approach for Controlled Text Generation. (from Alvin Chan, Yew-Soon Ong, Bill Pung, Aston Zhang, Jie Fu)
7. Teaching Pre-Trained Models to Systematically Reason Over Implicit Knowledge. (from Alon Talmor, Oyvind Tafjord, Peter Clark, Yoav Goldberg, Jonathan Berant)
8. Discrete Latent Variable Representations for Low-Resource Text Classification. (from Shuning Jin, Sam Wiseman, Karl Stratos, Karen Livescu)
1. Quasi-Dense Instance Similarity Learning. (from Jiangmiao Pang, Linlu Qiu, Haofeng Chen, Qi Li, Trevor Darrell, Fisher Yu)
2. Real-time Human Activity Recognition Using Conditionally Parametrized Convolutions on Mobile and Wearable Devices. (from Xin Cheng, Lei Zhang, Yin Tang, Yue Liu, Hao Wu, Jun He)
3. Map3D: Registration Based Multi-Object Tracking on 3D Serial Whole Slide Images. (from Ruining Deng, Haichun Yang, Aadarsh Jha, Yuzhe Lu, Peng Chu, Agnes Fogo, Yuankai Huo)
4. Privacy-Preserving Visual Feature Descriptors through Adversarial Affine Subspace Embedding. (from Mihai Dusmanu, Johannes L. Schönberger, Sudipta N. Sinha, Marc Pollefeys)
5. Spectral Image Segmentation with Global Appearance Modeling. (from Jeova F. S. Rocha Neto, Pedro F. Felzenszwalb)
6. Joint Training of Variational Auto-Encoder and Latent Energy-Based Model. (from Tian Han, Erik Nijkamp, Linqi Zhou, Bo Pang, Song-Chun Zhu, Ying Nian Wu)
7. TCDesc: Learning Topology Consistent Descriptors. (from Honghu Pan, Fanyang Meng, Zhenyu He, Yongsheng Liang, Wei Liu)
8. SLIC-UAV: A Method for monitoring recovery in tropical restoration projects through identification of signature species using UAVs. (from Jonathan Williams, Carola-Bibiane Schönlieb, Tom Swinfield, Bambang Irawan, Eva Achmad, Muhammad Zudhi, Habibi, Elva Gemita, David A. Coomes)
9. Morphing Attack Detection -- Database, Evaluation Platform and Benchmarking. (from Kiran Raja, Matteo Ferrara, Annalisa Franco, Luuk Spreeuwers, Illias Batskos, Florens de Wit Marta Gomez-Barrero, Ulrich Scherhag, Daniel Fischer, Sushma Venkatesh, Jag Mohan Singh等)
10. Explaining Autonomous Driving by Learning End-to-End Visual Attention. (from Luca Cultrera, Lorenzo Seidenari, Federico Becattini, Pietro Pala, Alberto Del Bimbo)
1. XAI for Graphs: Explaining Graph Neural Network Predictions by Identifying Relevant Walks. (from Thomas Schnake, Oliver Eberle, Jonas Lederer, Shinichi Nakajima, Kristof T. Schütt, Klaus-Robert Müller, Grégoire Montavon)
2. Zeroth-Order Supervised Policy Improvement. (from Hao Sun, Ziping Xu, Yuhang Song, Meng Fang, Jiechao Xiong, Bo Dai, Zhengyou Zhang, Bolei Zhou)
3. Population-Based Black-Box Optimization for Biological Sequence Design. (from Christof Angermueller, David Belanger, Andreea Gane, Zelda Mariet, David Dohan, Kevin Murphy, Lucy Colwell, D Sculley)
4. Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing. (from Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le)
5. MLE-guided parameter search for task loss minimization in neural sequence modeling. (from Sean Welleck, Kyunghyun Cho)
6. The Backbone Method for Ultra-High Dimensional Sparse Machine Learning. (from Dimitris Bertsimas, Vassilis Digalakis Jr)
7. UVeQFed: Universal Vector Quantization for Federated Learning. (from Nir Shlezinger, Mingzhe Chen, Yonina C. Eldar, H. Vincent Poor, Shuguang Cui)
8. Inference from Stationary Time Sequences via Learned Factor Graphs. (from Nir Shlezinger, Nariman Farsad, Yonina C. Eldar, Andrea J. Goldsmith)
9. A Primer on Zeroth-Order Optimization in Signal Processing and Machine Learning. (from Sijia Liu, Pin-Yu Chen, Bhavya Kailkhura, Gaoyuan Zhang, Alfred Hero, Pramod K. Varshney)
10. Efficient Contextual Bandits with Continuous Actions. (from Maryam Majzoubi, Chicheng Zhang, Rajan Chari, Akshay Krishnamurthy, John Langford, Aleksandrs Slivkins)
![]()