一次 PyTorch 的踩坑经历,以及如何避免梯度成为NaN

本文首发于知乎答主小磊在「PyTorch有哪些坑/bug?」下的回答,AI 研习社获原作者授权转载。
分享一下我最近的踩坑经历吧。
这几天在实现一个语义分割的 loss(链接:http://ieeexplore.ieee.org/document/7801846/)
该loss考虑了边缘,结果一致性等因素,如图
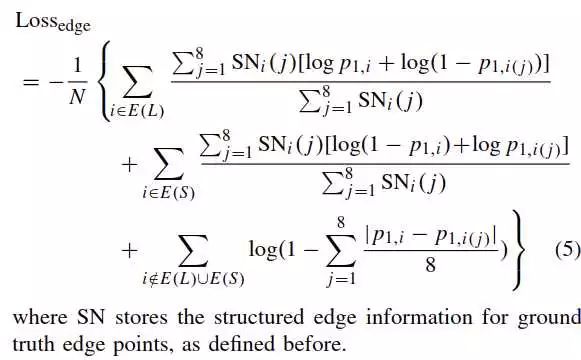
loss最复杂的部分
由于公式较为复杂, 决定用风格和numpy相似的pytorch来实现。
再由于torch是动态图,而且 Python的for循环很慢, 所以打算全用Tensor操作。
想着应该和numpy差不多,难度中等,加上熟悉API的时间 一天足够了。
开工前,准备了一组(image, ground truth, 及假装是分割网络结果的概率矩阵prob) 作为测试用例, 然后,正式开工!
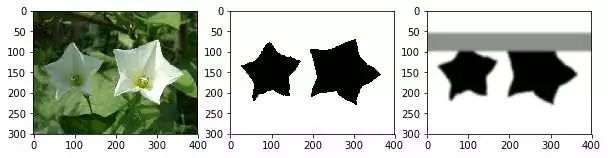
image, ground truth 及假装是分割网络结果的prob
写着写着,发现处理后的图片根本不对,可视化一下,发现 ground truth转化成`FloatTensor`后 就成了这个鬼样子:
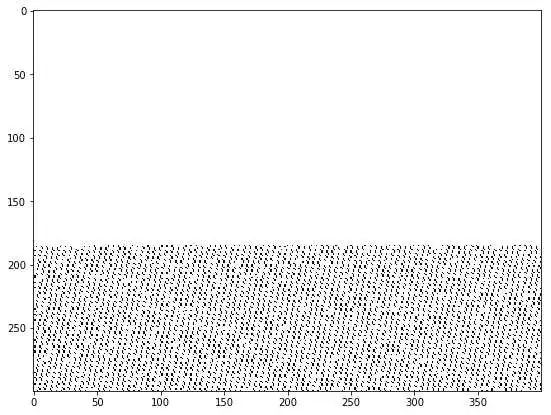
查明原因是: 对`torch.FloatTensor`传一个bool的numpy array , 即`torch.FloatTensor(Bool_Ndarray)` 就会成为上面这样的乱码。
得先转化为float32 即 `torch.FloatTensor(np.float32(labels))`。
继续写,咦 torch不支持[::-1]和flip?那自己写一个flip。
又继续写,全Tensor操作,遇到复杂公式, 就意味着超多维度的select, index, 纬度变换,纬度匹配,若出了bug 分析起来特别麻烦
比如:
otherSideEdgeLossMap = -th.log(((probnb*gtind).sum(-3)*gtdf).sum(-3)/gtdf.sum(-3))
这么黑灯瞎火地写下去,调试又复杂又慢。
工欲善其事, 必先利其器
于是,我便先去改之前只支持numpy可视化的工具代码 yllab (链接:https://github.com/DIYer22/yllab),增加其对torch的支持。
配合`Ipython@Spyder` 调试效率提高不少,比`print xx.shape,xx.mean()` 不知高到哪里去了。
最后, loss总算写出来了, 而且可视化出来的 loss map 符合预想效果,还很好看!
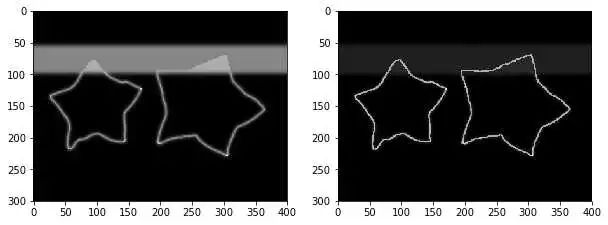
左图:crossEntropyMap 右图: edgeLossMap
最后一到工序,将概率矩阵prob变成Variable 测试一下反向传播,我天真得以为工作马上就要被完成了。改成Variable(prob)后, loss.backward()一下。啥?Error?Variable 竟然不能和 Tensor 运算 ! 不用记录grad的Variable和Tensor有啥区别?无语, 那全改为Variable吧。
Tensor和Variable部分api竟然不一样!比如(`.type`)。
行, 为了兼容性 函数都加上判断是否为Variable, 并转化为Variable.data。
继续吐槽一下torch的类型系统 `Tensor/Variable * 8个数据类型` * `cuda/cpu` 共 `2*8*2=32` 类啊!而且8个数据类型不支持类型自动转换,所以 这32个类型的数据都是两两互斥。
不同类型间的操作前都得转化, 可怕的是转换操作还有许多像上文提到的那种坑!
改好代码, 反向传播通了 赶忙可视化一下 prob.grad。
毛线!全是白的 分析一下grad中99.97%的是nan, 人家loss都好人一个 你梯度怎么就成了nan! 数学上不成立啊!
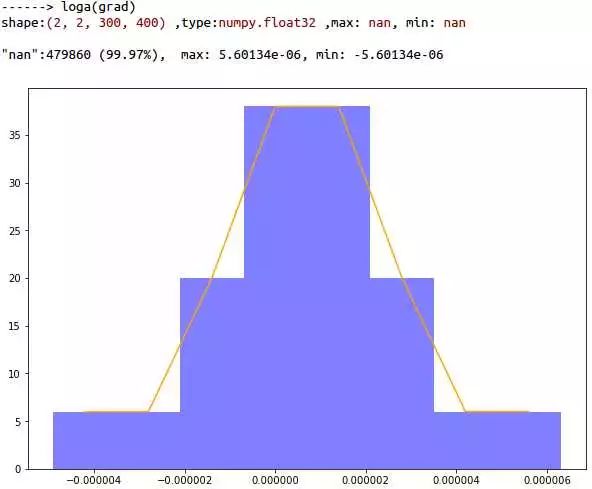
可视化分析 loga(grad)的结果
遂开始了漫长的DEBUG之路。终于,再不断地拆开loss。
分别Backpropagation后,将凶手精准定位了导致nan的loss。
进一步分析,果然是pyTroch的BUG。整理好BUG后,
就提交到了pytorch 的 GitHub上了。
x.grad should be 0 but get NaN after x/0 · Issue #4132 · pytorch/pytorch
(链接:https://github.com/pytorch/pytorch/issues/4132)
BUG如下:
Reproduction BUG code
x = Variable(torch.FloatTensor([1.,1]), requires_grad=True)
div = Variable(torch.FloatTensor([0.,1]))
y = x/div # => y is [inf, 1]
mask = (div!=0) # => mask is [0, 1]
loss = y[mask]
loss.backward()
print(x.grad) # grad is [nan, 1], but expected [0, 1]
由于被`mask`阻挡,`x[0]`根本就没在计算图中,所以`x[0]`梯度应该为0,却返回了`nan`
我还给出了BUG的解决方案:
Your code should't generat any inf in forward, which often produce by torch.log(0) and x/[0, ]
That means 0 should be filtered before do torch.log(x) and x/div
为避免这个BUG,代码变得更复杂了。
variables
└─ /: 4
├── gtind: torch.Size([1, 2, 300, 400]) torch.cuda.FloatTensor
├── edge: torch.Size([1, 300, 400]) torch.cuda.ByteTensor
├── probnb: torch.Size([1, 8, 2, 300, 400]) torch.cuda.FloatTensor
└── gtdf: torch.Size([1, 8, 300, 400]) torch.cuda.FloatTensor
th = torch
tots = lambda x:x.data
code(before)
otherSideEdgeLossMap = -th.log(((probnb*gtind).sum(-3)*gtdf).sum(-3)/gtdf.sum(-3))
otherSideEdgeLossMap[~tots(edge)] = 0
code(after)
numerator = ((probnb*gtind).sum(-3)*gtdf).sum(-3)
numerator[tots(edge)] /= gtdf.sum(-3)[tots(edge)]
numerator[tots(edge)] = -th.log(numerator[tots(edge)])
otherSideEdgeLossMap = (numerator)
otherSideEdgeLossMap[~tots(edge)] = 0
最后,把代码适配成多batch版本加上分割网络后,顺利跑通了 。 回想着一路下来,还好用的是动态图的pyTorch, 调试灵活,可视化方便,若是静态图,恐怕会调试得吐血,曾经就为了提取一个mxnet的featrue 麻烦得要死。
不过,换成静态图的话 可能就不会顾着效率,用那么多矩阵操作了,直接for循环定义网络结构,更简单直接 。
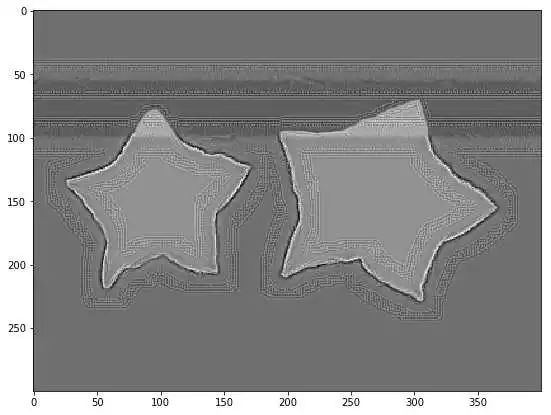
所有loss 反向传播后,prob 的 grad
写于 2017.12
torch version : 0.3

上海交通大学博士讲师团队
从算法到实战应用
涵盖 CV 领域主要知识点
手把手项目演示
全程提供代码
深度剖析 CV 研究体系
轻松实战深度学习应用领域!
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
PyTorch 到底好用在哪里?
▼▼▼





