
The State of Machine Learning Frameworks in 2019
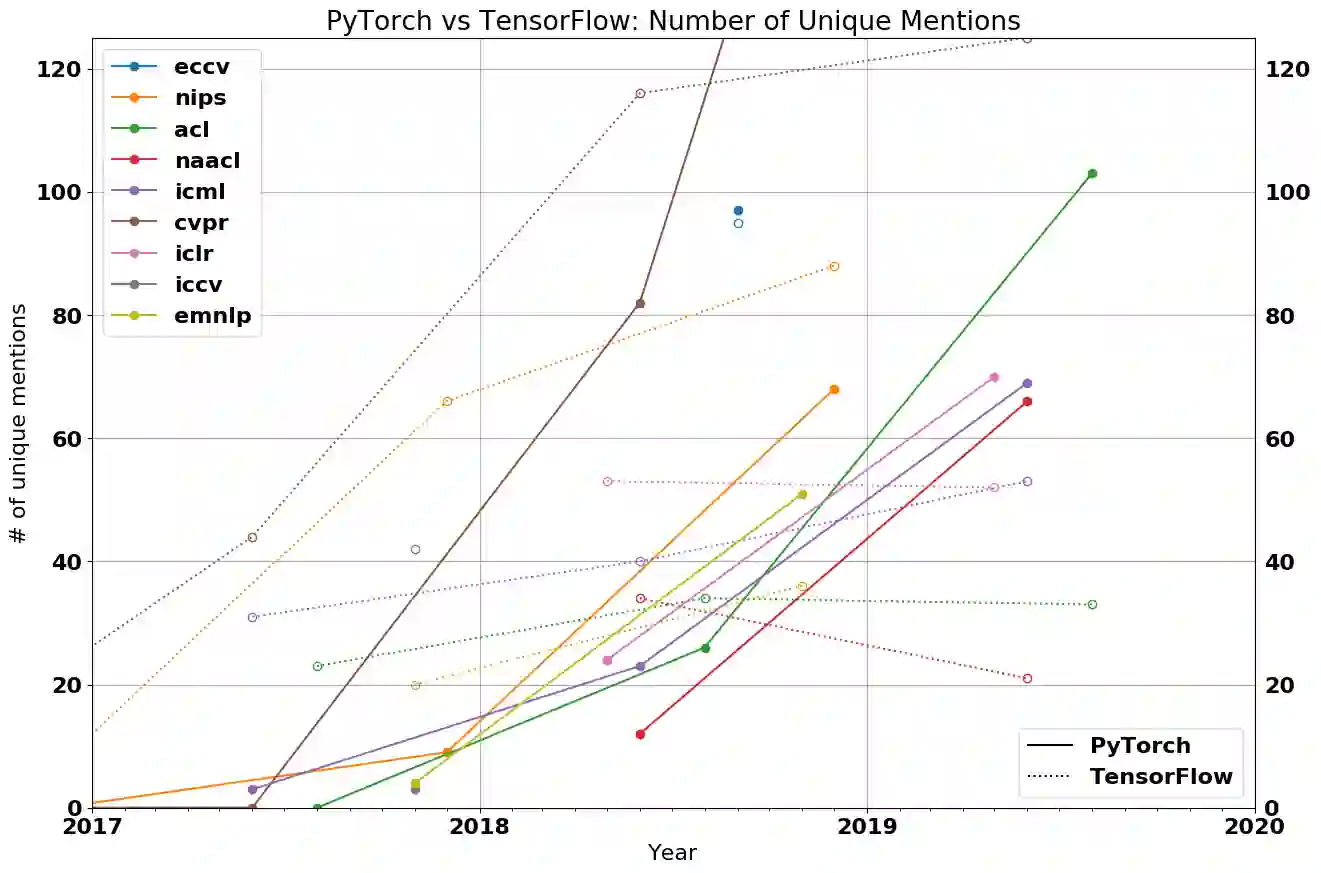
In 2019, the war for ML frameworks has two remaining main contenders: PyTorch and TensorFlow. My analysis suggests that researchers are abandoning TensorFlow and flocking to PyTorch in droves. Meanwhile in industry, Tensorflow is currently the platform of choice, but that may not be true for long.
相关内容

专知会员服务
38+阅读 · 2020年5月30日
Arxiv
9+阅读 · 2018年3月22日
相关主题


相关VIP内容
专知会员服务
38+阅读 · 2020年5月30日
相关资讯
相关论文
Arxiv
9+阅读 · 2018年3月22日