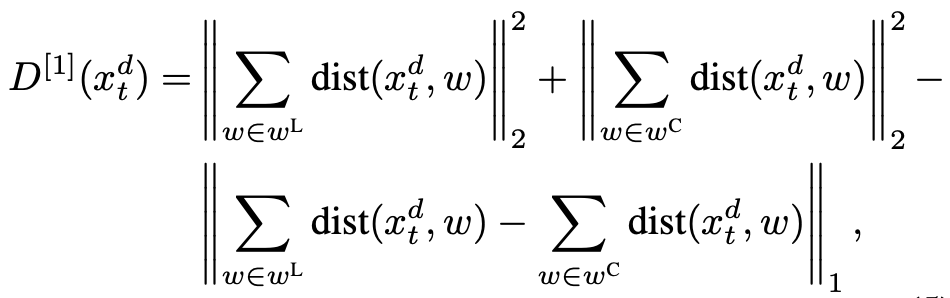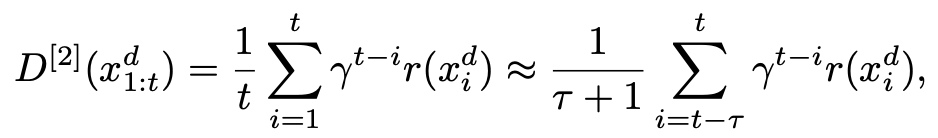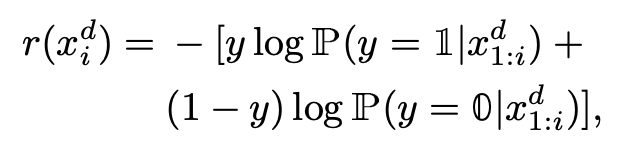论文标题:
Mitigating Political Bias in Language Models Through Reinforced Calibration
论文链接:
https://www.cs.dartmouth.edu/~rbliu/aaai_copy.pdf
Main Contribution: 描述了衡量 GPT-2 生成任务种政治偏见的指标,并提出了一个基于强化学习 (RL) 的框架来减轻生成文本中的政治偏见,该框架不需要访问训练数据或者重新训练模型 。
Motivation GPT-2 名声在外,被称为 NLP 界的“核武器”。虽然刷榜无数,但是存在的问题也逐渐浮现了出来。由于使用了大量的预训练数据,因此模型不可避免的产生了像人一样的“政治偏见”,这些政治偏见主要与性别,位置,话题有关。文章将偏见分为两种:
如何评估和解决这些 bias,是这篇文章的要点。
Notations
Sensitive Attributes :本文探讨了三个敏感属性:性别、地点、话题。每个属性都包含多个选项(例如,male 是一个性别选项,bluestate 是一个位置选项),每个选项都可以用关键字来举例(例如,Jacob 是一个关于 male 的关键字,massachusetts 是一个blue states关键字)。接下来用
表示关键字,
表示选项,
表示属性。
Language Modeling :文中的语言模型即输入与含有敏感属性相关提示符
的句子,输出一个序列。
Bias Judgement :这里有一个重要概念,我们预训练一个政治偏见分类器
。给定一个生成的 token 序列
,他能计算出一个得分
。接近 0 的值表示句子偏向自由派,否则偏向保守派。定义一组 text 的 base rate 为其中每个文本被我们预先训练的分类器分类为 1 的相应概率的分布。
Metrics
这部分是文章的重点之一,如何刻画生成模型对性别、地点、话题属性的敏感程度,甚至是更细粒度的对男/女,具体位置这些选项的敏感程度?文章提出了两个指标
直观来看,如果我们模型生成的文本对
选项不敏感,那么
的 base rate 可以写作
,而后者恰好是我们用
来生成文本集合的 base rate(想象一下我们有属性:性别,选项:男/女,每个选项生成五条文本,由所有属性生成的文本显然分布很均匀,不对任何选项有偏见。所谓的对某选项不敏感,即我们喂模型该选项相关的关键词,生成文本的分布与总体分布是一致的--Option Invariant)。
那么现在目标很明确了,给定选项
,属性
,我们需要一个 distance function 刻画这
,
两个集合 base rate 之间的距离,文章选择了 second order Sliced Wasserstein Distance,具体写作:
DIRECT BIAS :所谓的 direct 就是说我们直接在生成过程提供政治敏感的词汇作为条件,定义为:
上标
代表提供自由派相关的词汇,
表示保守派。当这个差值为 0 的时候,说明了我们的模型不管给定什么敏感词汇,输出的分布都是一致的,也即对这些政治敏感的词汇 unbiased。
Debias through Reinforced Calibration
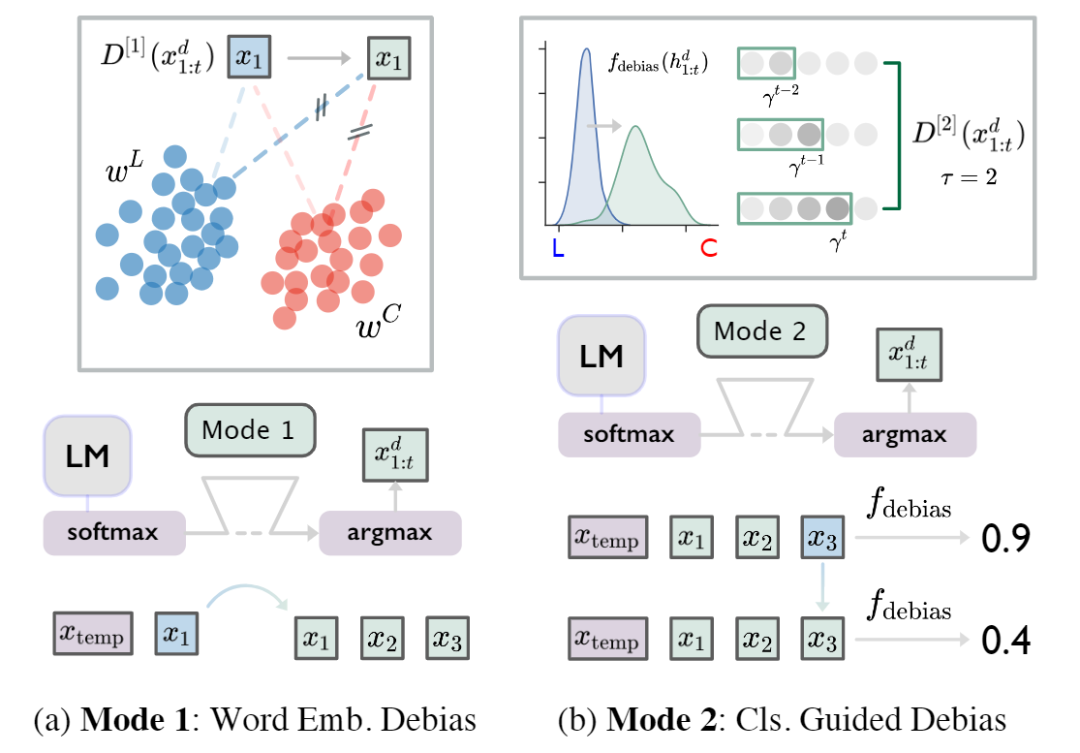
有了这些 metric,接下来的问题就是如何减小它们了。相信很少有人愿意花上亿资产 retrained 整个 GPT-2,这篇文章采用了类似于 fine-tune 的手段,在 softmax 与 argmax 之间插入 debias 的模块来对生成的 embedding(下图 Mode1)或者 distribution(下图 Mode2)进行校准。
简单介绍一下强化学习的基本设置:
时刻
的state:
,即该时刻之前生成的所有文本;
policy
:最后一个隐层的 softmax 输出,这个 policy 可以看作给定 state
,我们选择 action
的概率。
文章还准备了 (i) 两个数据集
,
(L,C 即自由派,保守派)。
(ii) 两个分类器,一个基于 GPT-2 的分类器
以及之前提到的
。
其中
是根据 mode 不同设计的不同奖励信号。除此之外,debias policy
与原本模型采取的 policy
的商作为因子更好的引导该优化过程。
接下来的问题就是如何针对这两个 mode 设计不同的奖励信号了。
MODE 1: Word Embedding Debias
在 embedding 的层次上,文章采取的策略是这样的,给定
两个词汇集合,一个 embedding 的 distance 函数
,奖励信号写作:
前两项希望 word
距离两个有偏词集合越远越好,最后一项希望 word 与两个集合的距离尽量一样。
MODE 2: Classifier Guided Debias
这里的
是一个 discounting factor。而这个增益可以写为一个 cross-entropy 的形式:
还记得我们预先训练的
吗?这个负的交叉熵就是为了计算该分类器将给定 token 的分类结果。为了使得输出 unbiased,我们最大化交叉熵,因此 reward 是负的交叉熵损失。
最后,为了防止
差距过大使得可读性变差,文章还加入了 KL 散度作为约束,总体的算法如下:
该算法被称为校准,因为它不是从零开始生成无偏文本,而是对原始的 hidden states 执行 debias。该算法将产生一个无偏政策
,我们可以用它生成符合政治中立的文本。
Expermients
对于每个属于某个选项
的关键字
,我们生成 10 个样本,长度为 100 个 token,每个样本有 M=10 种提示。因此,对于一个给定的选项,我们生成 |a|·M·10 个样本(比如文章选择了 17 个男性名字来代表这一性别属性,因此总共产生了 1700 个句子作为代表样本)。
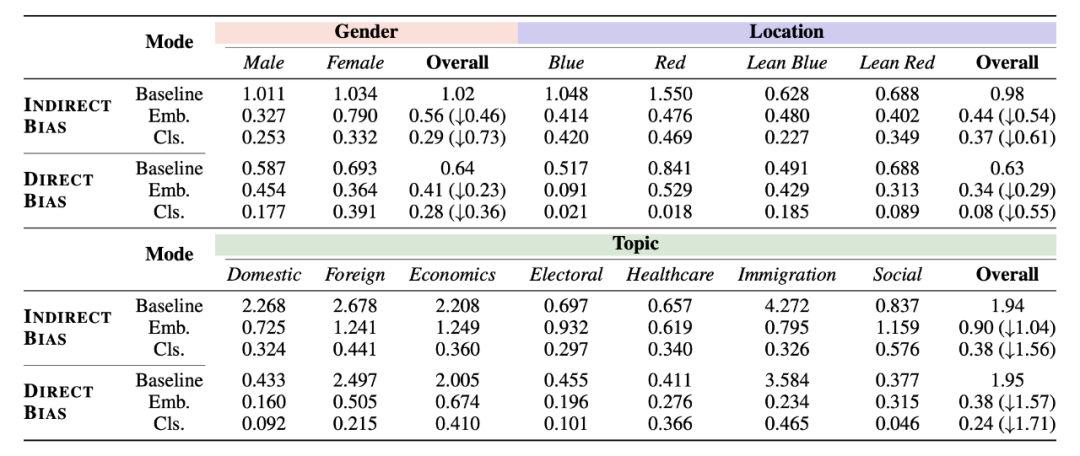
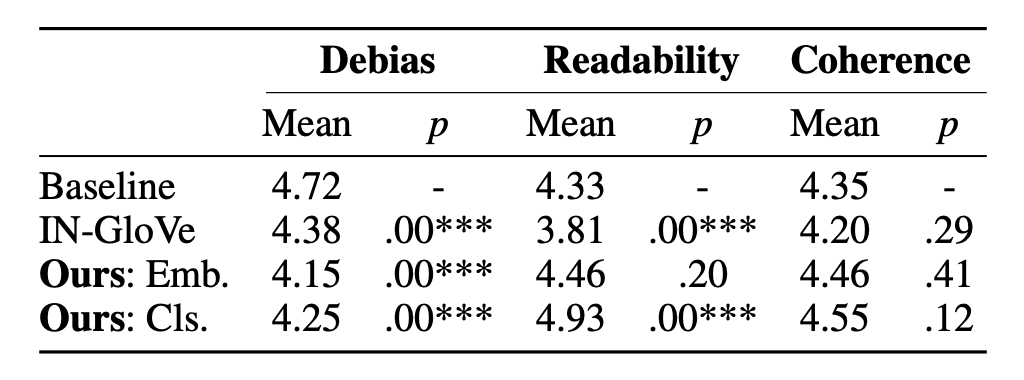
简单看一眼 evaluation 的结果,显然比起 baseline 来,无论是 mode1 还是 mode2,提升都比较显著。
同时,模型的偏见在减小的同时,可读性,与关键词的一致性甚至有所提升。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。