赢得WMT机器翻译大赛,Meta的单个多语言模型是怎样炼成的?

本文最初发布于 Facebook AI 博客,由 InfoQ 中文站翻译并分享。
现如今,大多数 MT 系统都使用多组双语模型。通常,这需要为每个语言对和任务提供大量的标签实例。遗憾的是,这种方法对于许多训练数据稀少的语言无效(例如冰岛语和豪萨语)。它的高复杂性也使得它无法扩展到 Facebook 的实际应用中,上面每天有数十亿人用数百种语言发帖。
为了构建一个通用的翻译器,我们认为 MT 领域应该从双语模型转向多语言翻译——在这种情况下,一个模型可以同时翻译许多语言对,包括低资源(如冰岛语到英语)和高资源(如英语到德语)。
多语言翻译是一种很有吸引力的方法——它更简单,更具可扩展性,而且更适合低资源语言。但直到现在,对于高资源语言对,这种方法的效果还比不上与专门为这些语言对训练的双语模型。因此,在许多语言中,提供高质量的翻译通常需要组合使用多个双语模型,而低资源语言被抛在了后面。
现在,我们取得了令人激动的突破:单个多语言模型首次在 14 个语言对的 10 个中超过了专门训练的最好的双语模型,赢得了 WMT 这个著名的 MT 竞赛。我们的单一多语言模型为低资源语言和高资源语言都提供了最好的翻译,这表明 多语言方法确实是 MT 的未来。
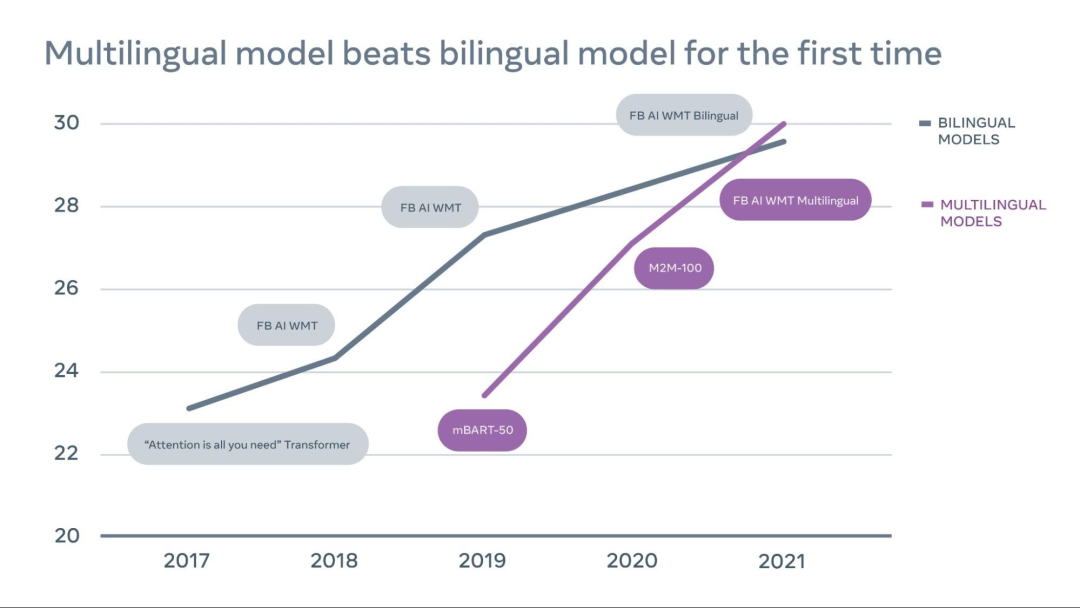
我们展示了在 WMT 比赛中,英译德翻译的质量随时间的推移逐步提升,其中多语言模型现在已经超过了双语模型。通常,英译德被认为是最具竞争力的翻译方向。我们公布了所有模型在 Newstest 2021 上的表现。
这项工作是以之前的突破性工作为基础,那些工作提高了低资源语言的翻译质量。然而,当加入拥有不同资源的语言时,先前的工作在基本能力方面就遇到了挑战——随着更多语言的加入,一个模型变得不堪重负,每一种语言都有自己独特的语言特性、字母和词汇。当高资源语言从大型多语言模型中受益时,低资源语言对就有可能过度拟合。
我们的模型获奖是 MT 领域一个令人兴奋的转折点,因为它表明,借助大规模数据挖掘、模型容量扩展方面的 最新进展 和更有效的基础设施,多语言模型有可能在高资源和低资源语言上都取得良好的效果。它使我们离构建一个通用的翻译器更近了一步,这个翻译器可以连接全世界所有语言的人,而不管翻译数据有多少。
为了训练 WMT 2021 模型,我们构建了两个多语言系统:任意语言到英语以及英语到任意语言。我们利用 并行数据挖掘技术,在从网络上抓取的大型数据集中确认翻译,从而克服人工翻译的标准训练文档的局限性,如欧洲议会的演讲稿,并不是所有的翻译方向都有这样的文件。
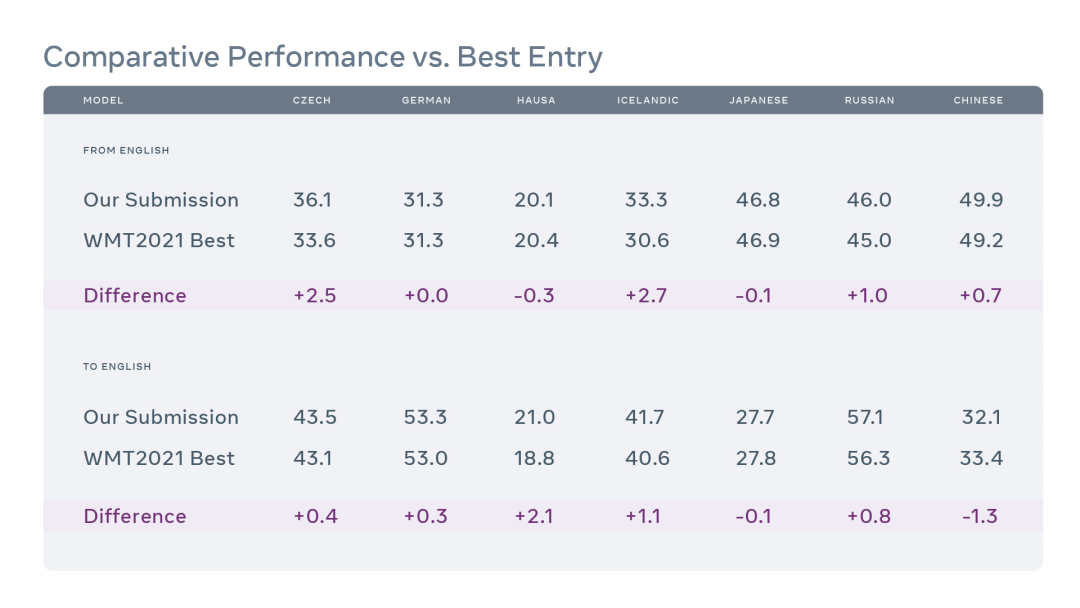
我们的模型与提交给 WMT '21 的最佳模型的效果比较。上述数值是在 WMT '21 决赛测试集上取得的 BLEU 分数。
由于任何语言的单语数据量都大大超过了其并行数据,所以利用现有的单语数据来最大化 MT 系统的效果至关重要。对于单语数据的使用,最常见的技术之一是 逆向翻译,我们用它赢得了 2018 年和 2019 年的英译德 WMT 新闻翻译任务。
我们在工作中大量增加了单语数据,包括来自所有八种语言的数亿个句子。我们对现有的单语数据进行了过滤,以减少噪音量,然后组合当前最强的多语言模型对它们进行了逆向翻译。
除了使用逆向翻译来扩展数据规模外,我们还将模型规模从 150 亿个参数扩展到 520 亿个参数,以增强多语言模型架构的能力。所有这些扩展工作都得益于 Facebook 最近推出的名为 Fully Sharded Data Parallel 的 GPU 内存节省工具,它使大规模训练的速度比以前的方法快了 5 倍。
由于多语言模型本质上是对容量的竞争,它们必须在共享参数和针对不同语言的特殊化之间取得平衡。按比例扩展模型大小会导致计算成本的不可持续增加。
每种建模技术对最终提交的影响。我们使用最后一行(黑体字)作为 WMT2021 的提交,因为它在所有语言中都表现最好。上述数值是在 WMT'21 开发数据集上取得的 BLEU 分数。
我们使用了另一种方法,以便可以利用条件计算方法,对于每个训练实例,它只激活模型的一个子集。具体来说,我们训练 稀疏门控专家混合(MoE)模型,其中每个标记都根据学习到的门控函数被路由到前 k 个专家 FeedForward 块。我们使用一个 Transformer 架构,在每一个可选的 Transformer 层中,用 Sparsely Gated Mixture-of-Experts 层取代 FeedForward 块,并在编码器和解码器中使用 top-2 门控。这样,每个输入序列都只使用所有模型参数的一个子集。
这些模型有助于向高资源方向的翻译从增加的专家模型容量中获益,同时又能通过共享模型容量实现向低资源方向的翻译。
机器翻译领域克服重重障碍,取得了令人印象深刻的进展,但大多数都集中在少数几种广泛使用的语言上。低资源翻译仍然是 MT 的 "最后一英里 "问题,也是该子领域目前公开的最大的挑战。
我们相信,我们在 WMT 2021 大会上的成功证明,多语言翻译是构建一个通用的翻译系统、为世界各地的人们提供高质量翻译的重要途径。我们已经证明,单个多语言模型可以为高资源语言和低资源语言提供比双语模型质量更高的翻译,并且更容易针对具体任务进行微调,例如翻译新闻文章。
这种“一个模型适用于多种语言”的方法也可能简化现实世界中翻译系统的开发——有可能用一个模型取代成千上万的模型,从而也就更容易为世界各地的人们带来新的应用和服务。
现在,我们正在研究克服接下来的挑战,从而使这些技术可以适用于 WMT 比赛中所涉及的语言之外的语言。例如,如何开发新的技术来支持单语数据更少的稀有语言,在这些语言中,像逆向翻译这样行之有效的技术是否还可能?
原文链接:
The first-ever multilingual model to win WMT, beating out bilingual models

你也「在看」吗?👇



