IJCAI 2020 | 我们离有效的上下文建模还有多远?

编者按:一直以来,更好的上下文理解能力都是对话式语义解析模型追求的目标,学术界近几年也涌现了许多面向该场景的上下文建模方法。目前尚无研究对这些方法进行全面比较和深入分析,受此启发,微软亚洲研究院的科研人员在 IJCAI 2020 的论文中,全面评估了各种上下文建模方法的性能,并对不同方法在细粒度上下文现象的优势与困境做了深入分析。研究表明,目前的上下文建模方法仍不够成熟,在一些特定的上下文现象上表现不理想,因此未来该领域的研究任重而道远。(点击阅读原文,了解更多论文细节)
2019年,在 Excel 发布的一项新功能中,没有编程背景的用户也能通过自然语言零门槛地进行数据分析,洞悉数据价值。这项功能背后的技术就是语义解析(semantic parsing)。语义解析是自然语言处理中的一个重要领域,它旨在赋予机器理解人类语言,并将其翻译成指定编程语言的能力。而对话式语义解析(semantic parsing in context),则允许用户通过更自然的多轮对话的方式来渐进地分析数据。在这种场景中,我们希望机器不仅能理解上下文无关的问句(如图1中的 Q1),也能理解语义依赖于上下文的问句(如图1中,Q2 省略了语句主语、Q3 中的代词 its 指代了上文中的内容)。事实上,语义解析是个很大的领域,理论上语义解析模型可以将自然语言转换为各种编程语言。而本文主要关注数据分析领域,即把自然语言转换成结构化查询语句(structured query language, SQL,如图1中的 S1)的任务。

图1:对话式语义解析示例,左侧是数据库的 schema,右侧是用户与系统的对话
面向对话式语义解析的场景,研究者们提出了各种上下文建模的方法。按照使用的上下文类型,我们可以把它们分成两类:一类方法将部分用户的历史问题作为上下文(如将图1中的 Q2 和 Q1 作为模型的额外输入),而另一类则仅以上轮产生的 SQL 作为上下文(如将图1中的 S2 作为模型的额外输入)。直观来讲,依赖于 SQL 作为上下文的方法拥有更好的泛化性,因为不论处在对话的第几轮,模型都只会将上一轮产生的 SQL 作为上下文。值得注意的是,这两类方法并不互斥,模型可以同时使用它们。
目前已有许多建模上下文的方法,但学术界对于“哪个上下文建模方法最有效”这个问题尚无定论。许多研究问题也都值得探索,比如“这些方法擅长解决什么类型的上下文现象”,“它们目前还无法解决什么类型的上下文现象”等等。受此启发,我们试图通过一项细粒度的探索性研究来回答这些问题。相信如果这些问题可以得到解答,那么对话式语义解析领域未来的发展脉络会变得更清晰。
我们在研究中关注三个问题:
(1)与最先进的方法相比,最简单的上下文建模方法效果如何?
(2)在配置相同语义解析模块的情况下,不同的上下文建模方法相比如何?
(3)在不同的上下文现象上,不同的建模方法表现如何?
在回答这些问题之前,首先我们先来介绍一下单轮场景下基于语法的语义解析器(grammar-based semantic parser)是如何工作的,然后再介绍研究者们提出的各种上下文建模的方法如何与该模块搭配构成对话式语义解析器。

在单轮对话场景下,语义解析任务的输入包括若干通过主外键相连的关系数据库表、一个与这些表相关的自然语言问句,以及输出为反映该问句语义的 SQL 语句。通过在数据库表上执行 SQL 语句,用户可以得到问句的答案。
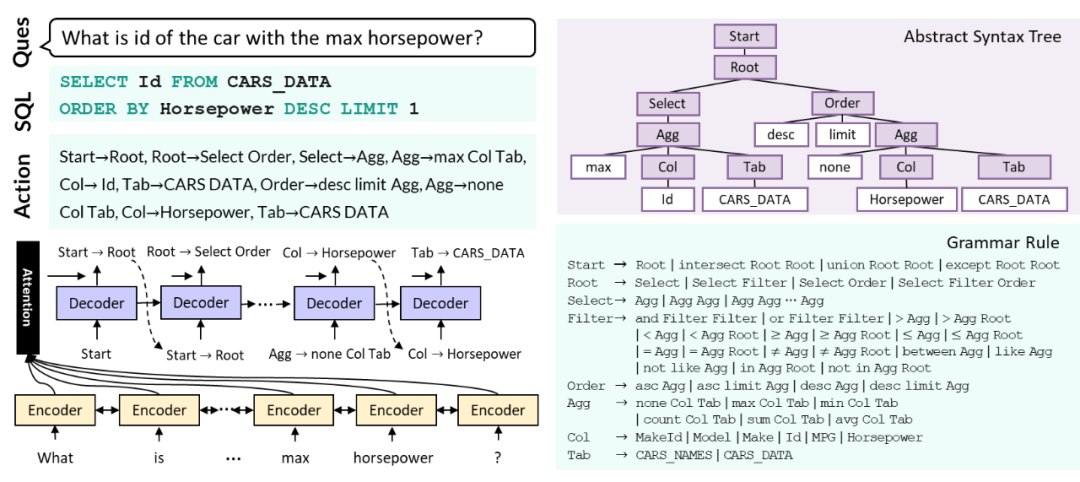
图2:基于语法的语义解析器
目前,做该任务比较流行的方法是基于语法的语义解析器,它基于带注意力的序列到序列模型(attention-based sequence to sequence),主要由编码器(encoder)和动作解码器(decoder)构成。
如图2所示,编码器负责建模问句与数据表的表示,而解码器则根据编码器提供的表示,逐个选择有效的语法规则(grammar rule),最终得到一个动作序列(action sequence)。每个语法规则都包含一个非终结符(nonterminal),和其展开得到的若干符号。在解码的每一步,都会有一个非终结符被一条其对应的语法规则展开,就形成了图2中的动作序列 [Start->Root, …, Tab->CARS_DATA]。
该动作序列可以通过从左至右深度遍历 SQL 语句 SELECT Id From CARS_DATA ORDER BY Horsepower DESC LIMIT 1 的抽象语法树(abstract syntax tree)得到,如图中的紫色部分所示。与普通的序列到序列模型将 SQL 语句单纯视为词序列不同,基于语法的语义解析器将 SQL 语句视作动作序列。通过融入 SQL 语法的知识,其生成的任意动作序列都可以转换成一个语法正确的 SQL 语句。
在单轮场景中,模型的输入只有一句上下文无关的自然语言,而在多轮对话中,模型的输入还有对话的历史。这里的历史不仅包括用户之前提出的问句,还包括之前问句对应的 SQL 语句。
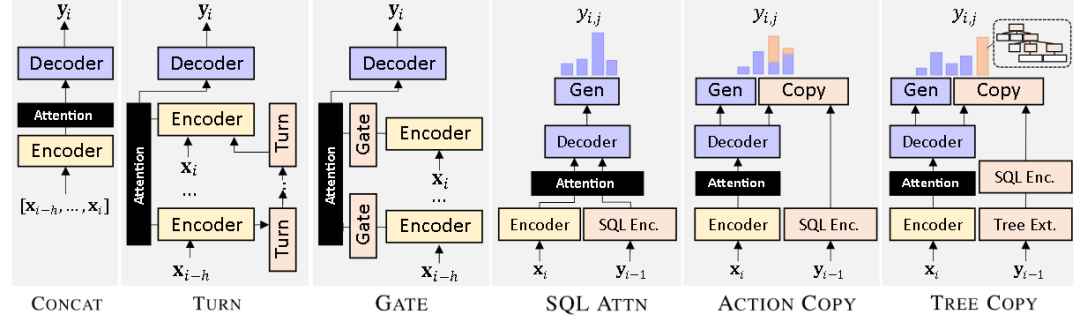
图3:不同的上下文建模方法
如图3所示,左侧三类属于前述的第一类建模方法(将部分用户的历史问题作为上下文),而右侧三类则属于第二类(仅以上轮产生的 SQL 作为上下文)。其中,CONCAT 方法是最直观、也是最简单的上下文建模方法,它直接将最近 h 轮问句拼接在一起作为模型的输入。但这种简单的建模丢失了句子粒度的依赖信息,为了更精确地建模句子间的依赖,研究者们提出了 TURN 方法。TURN 在原有的编码器基础上引入了一个新的编码器,该编码器以每轮的句子表示作为输入,通过 LSTM 编码句间的依赖关系,并将句子粒度的隐藏状态作为下一轮句子编码的输入。类似地,GATE 方法注意到不同上下文重要性不同的特点,在解码器的注意力上加入了可学习的上下文的权重,从而使得模型能够有选择性地依赖重要的上下文来产生 SQL 语句。
至于第二类方法,SQL ATTN 引入了一个 SQL 编码器,用其编码上轮 SQL 语句得到的表示作为解码器的额外输入,从而使得解码器利用到历史 SQL 的信息。ACTION COPY 和 TREE COPY 的思路则与复制网络类似,它们都注意到一个对话解析场景的典型特点:当前轮产生的 SQL 语句,往往与所依赖上文的 SQL 语句有较多重叠。例如图1的 S2,它的主体与上轮产生的 S1 相同。为了充分利用这个特点,ACTION COPY 允许模型复制上轮已产生的、与当前非终结符兼容的语法规则。而 TREE COPY 则允许模型一次复制多个语法规则,这些语法规则可以对应到 SQL 语句抽象语法树的一颗子树。
为了回答开头提到的三个研究问题,我们首先在两个跨域(cross domain)对话式解析数据集 SParC 和 CoSQL 上实验了不同的上下文建模方法以及部分它们的组合。作为最简单的上下文建模方法,CONCAT 方法在 SParC 和 CoSQL 开发集上的准确率分别达到了41.8和33.5。相比而言,目前最先进的 EditSQL 方法的准确率分别是33.0和22.2。类似地,CONCAT+BERT 的准确率也超过了 EditSQL+BERT,分别取得了52.6和41.0的结果。通过这一组数据的对比不难发现,只要搭配一个较好的语义解析模块,一个最简单的上下文建模方法也有能力超过最先进的方法。
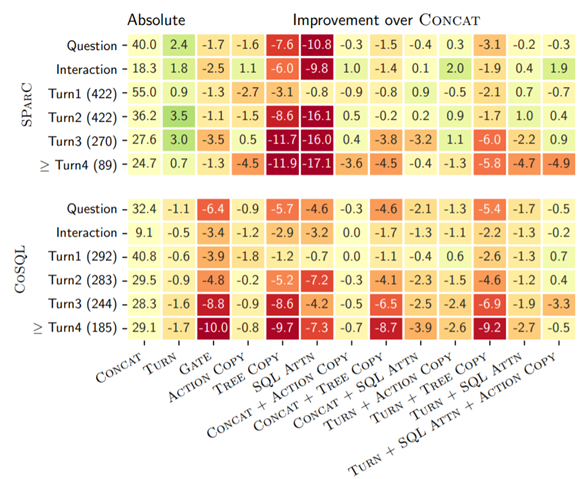
图4:不同上下文建模方法在不同指标上的对比
那么,不同上下文建模的方法之间对比如何呢?图4列举了不同方法及一些典型组合在两个数据集上不同指标下的结果,其中红色表示该方法的结果不如 CONCAT,绿色表示该方法的结果比 CONCAT 要好。总体上来看没有任何一个方法能够始终优于其他方法。同时,不同上下文建模方法的组合并不能显著提高性能。搭配 BERT 的结果也显示出了类似的趋势。总而言之,已有的上下文建模方法效果并不理想,它们相比最简单的 CONCAT 都没有显示出明显优势。

图5:典型的上下文现象
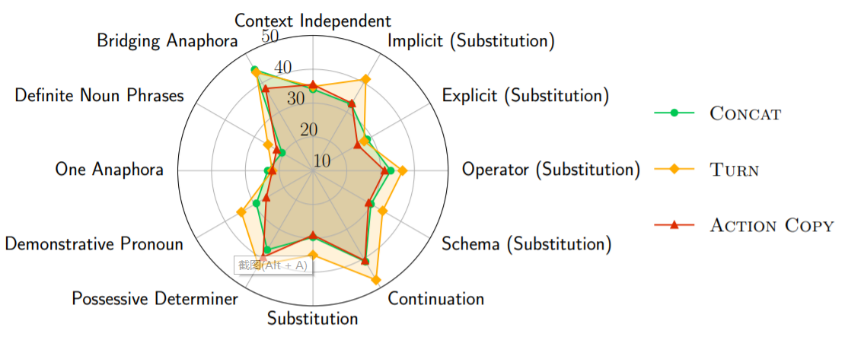
图6:三种典型上下文建模方法在不同现象上的准确率
我们将 SParC 的开发集作为样本,以 CONCAT、TURN 和 ACTION COPY 这些典型的上下文建模方法为例,分析了它们在各种上下文现象中的结果(见图5,图6)。结果显示,所有方法都在两种细粒度的指代现象上受挫:限定性名词短语(definite noun phrases)和一型回指(one anaphora)。这两种现象在代词指代上都需要较为复杂的上下文分析,目前的上下文建模方法都无法准确推理。
至于对话中另外一种常见的现象语义省略,通过三个层次的比较可以发现:(i) 所有的方法在延续省略(continuation)上的效果都比在替换省略(substitution)上更好。这是合理的,因为替换省略中上文会存在多余语义,干扰模型的预测。(ii) 所有的方法从隐式替换(implicit)到显式替换(explicit)都会有明显的性能下降。这个结论是反直觉的,因为显式替换提供了更多的线索供模型决策,它的效果理应更好。但已有的方法显然没有充分利用这样的信息,这间接表明已有的方法都无法有效地建模上下文。(iii) 相比于数据表替换(schema),操作符替换(operator)上各方法的效果更好。我们把这一点归结于这里跨域的设定,使得模型在数据表的替换现象上更难泛化。
本文以生成 SQL 为例,以一个探索性研究分析了对话式语义解析场景中各种上下文建模方法是否足够有效。文章的分析表明,和最简单的直接拼接上下文相比,已有的上下文建模机制并没有显现出一致更好的效果。细粒度分析的结果同样表明,目前的上下文建模方法对上下文的利用还不够充分。未来,我们计划从细粒度的分析结果入手,研究出更有效的上下文建模方法。
点击阅读原文,了解更多论文!
本篇 IJCAI 2020 论文:
How Far are We from Effective Context Modeling? An Exploratory Study on Semantic Parsing in Context, Qian Liu, Bei Chen, Jiaqi Guo, Jian-Guang Lou, Bin Zhou and Dongmei Zhang. In IJCAI 2020.
论文链接:https://www.ijcai.org/Proceedings/2020/0495.pdf
代码链接:https://github.com/microsoft/ContextualSP
你也许还想看:








